基于Go实现的分布式MQ
讲师:赵超(Beta版厨子3.0)
个人简介:
6年的Java开发经验、先后就职于淘宝Java中间件团队、腾讯无线媒体产品部。现就职于陌陌担任基础业务组主管。专注于分布式消息总线、LBS技术领域、golang在大规模生产换环境应用的探索。
今天交流的内容也是我上半年主要做的一个开源的MQ的项目,希望对大家有帮助
一、RPC与MQ之间对比

我们通常接触到的RPC同步调用的种类非常多比如fb 的thrift/阿里的dobbo
腾讯的taf、淘宝的hsf这类同步调用框架
从图里面可以看到作为一个业务完成后端要发生非常多的RPC通信
随着业务的复杂度提高,各服务间的依赖度也逐步加大,那么服务间的响应时间也就各有参差了
在一个请求链路上如果存在一个慢的服务那么可能会引起雪崩的效用,短板非常明显
最重要的时在一些要求一致性高的场景下,对错误的处理也是非常重要的。所以个服务也都要去做容错处理的代码保证逻辑和数据一致

A、B、C。。。服务之间通过共同的消息协议进行通信,数据一致性问题完全交给MQ去处理即可
A、B、C服务的同步响应效率得到提升
总结:

所以在我理解的消息中间件就是以消息作为信息载体实现系统间的可靠异步的调用,减少系统间耦合的中间层框架
二、消息传输模型
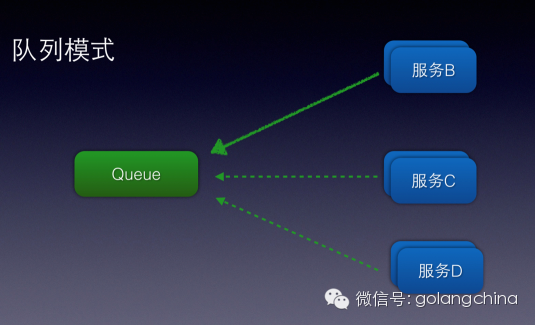
队列模式或者也可以叫点对点
很明显看到这个图很多人就会联想到redis的list结构
rpush—>lpop,没错
通过轮训去完成消息的送达
但是对于点对点模型来说存在的问题是,没法做到消息被B、C、D服务都消费的目标。
例如日常开发中我们想将用户登录“陌陌”的消息同时要给用户中心、anti-spam
这个时候就非常的不方便,那么PUB、SUB模式就呼之欲出了
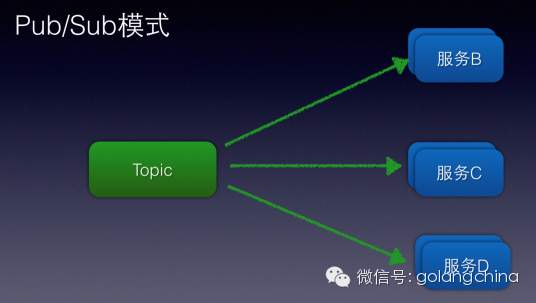
pub/sub模式 以Topic为单位进行对消息的订阅、发布
B、C、D这些订阅了该Topic的服务均可以处理该Topic的消息
就好比你打开收音机,你在听91.5飞鱼秀、别人也订阅了飞鱼秀,可以同时收听感兴趣的主题的信息一样的道理
三、KiteQ是什么?

kiteq 是我在今年2月份开始开发mq,它具有如上描述的特性,分布式、支持2PC、多种存储方式、跨语言的特性。
首先想了解KiteQ,先对几个概念有所了解

messageType产生是为了更细分业务类型下的消息。精细化控制消息的粒度
group对于kiteq来说是为了以组为单位,逻辑上认为是一个消费或者发送方,但groupId下面可以对应多台实例用于实现负载均衡
最重要的时Binding,订阅关系:订阅方发给mq的签约信条。kiteq拥有这个信条才会将订阅方感兴趣的话题消息推送给订阅方,非常重要。
Listener当然分两种:
第一种是MessageListener订阅方接收方的消息送达回调
第二种是CheckMessageListener是用来解决分布式事务的本地事务提交或回滚的确认消息;
KiteQ的整体架构:

整体的流程就入图描述

使用zk做集群发现包括 server producer consumer
同样zk做订阅关系的管理

如果(图)描述了kiteq的三个组成部分在zk中的数据体现


普通消息就是不牵扯分布式事务的消息
生产者发送消息到kiteq,kiteq首先做的时存储(哪怕是内存、Mysql、file)
同步给producer返回成功,或失败
然后producer就去干别事情
kiteq内部会根据消息头部的topic/messageType 去查询kiteq通过zk下发的订阅关系找到匹配的订阅方分组id
然后通过分组ID选取客户端物理连接 write出去
等待消费方回执:超时重发、成功记录已经投递成功的分组ID,下次不再投递或失败重投

事务消息,先是为了解决,比如在A系统中执行Mysql操作
同时要告诉用户系统订单充值成功夸两个资源的访问
这个时候就要保证两个跨资源的事务同时成功同时失败
所以就引入了事务消息
区别于普通消息
事务消息在发送阶段在没有得到本地producer回执本地事务成功或者回滚时是不会给consumer投递该消息,这样就保证了producer和远端consumer服务的事务一致性
所以刚才提到的listener分两种 CheckMessageListener就是为了做事务消息KiteQ询问Producer本地事务处理成功或回滚的入口
要么Producer主动通知kiteq结果和KiteQ主动询问Producer成功与否
三、KiteQ对几种错误场景的处理

场景一:存储失败那就同步返回消息发送失败,producer需要重新发送。注意我们指的MQ做到异步是指(发送方与消息被投递给订阅方是异步的,而发送方和MQ之间是同步方式不可避免,不然就会有丢消息不可靠的问题)
场景二:事务消息发送给KiteQ时头部是一个未提交标识,所以Kiteq是不会投递的,只投递已提交消息,对本地事务结果的确认有客户端主动通知回滚和服务端主动询问机制双重保证消息最终的可投递状态,不会产生本地事务失败,但是kiteq将消息投递给订阅者不一致的情况

场景三、四:订阅方接收超时、或者宕机,KiteQ在每次投递后会记录当前已经投递成功的分组也就是groupId,后续根据这些groupId再去重发
保证消息的一定送达,但是当消息超过的TTL或者最大投递次数就会被放到deadline queue中不再投递。所以即使机器groupId内的机器全部宕机也不会有丢消息的风险。
四、重复消息、消息顺序的处理、消息堆积
重复消息:
大家其实可以想一下重复消息产生的原因
消息的ID现在采用的UUID,所以可以做到唯一
重复消息,比如消费端处理超时了(服务端不知道是否处理成功)、消费端挂了,必然需要重投,如果需要做到消息去重,我建议还是在客户端做一个消息处理状态用于去重
消息顺序:
分布式场景下消息的顺序是在是难以保证,然后很多人会说那用分布式锁
what 's a fucking idea!
但我给的建议是消费端做状态机。比如 处理顺序是 1、2、3如果消息到来顺序是2、1、3那么只需要客户端做到2先到的时候返回处理失败,通过下次重投自旋去保证状态吧。
消息堆积:
所以mq设计也要考虑到这个问题,解决方案也就是你的存储
试想redis不具有海量堆消息的能力,这是考验MQ在消费方异常时非常关键的系统稳定性的指标。
在kiteq设计的时候,根据你消息的重要程度也提供了三种可靠级别的存储mysql master-slave / file /memory供不同业务场景使用。
kiteq中的file就是模仿了kafka顺序写数据,分为data和log。data为消息体,log中保存消息的每次投递结果(哪些失败了哪些成功了等)、消息是否提交等数据,即对消息的更新操作记录。内存中保持指定数目的segment
保证读的性能,消息重投时通过逻辑id,二分查找消息所在的segment,然后按照tlv格式读取消息体即可。
好了kiteq的东西就分享这么多吧
然后最后总结一下
Go开发的体会 :

希望对家学习go有所帮助吧
五:Q & A
1 为什么用zookeeper不用etcd
etcd在gopher china的时候不是提到了对于支持临时序列节点简直非常蛋疼。。。 而且我对zk比较熟吧
2. 目前这个消息系统应用于线上系统了吗?
内部在推广中
3 可以分别根据消息重要度来区别存储么,比如重要的持久化到mysql,不重要的内存,还是全局只能用统一的消息存储方式
根据消息重要性来区分,我觉得最好按照集群来划分即可;比如可以丢掉消息就用file存储、重要的就用Mysql的Master-slave;比较好管理
4. 看介绍采用的是推模式,那对consumer的处理速度做了适配处理么?
设计的时候有预留watermark;不同的consumer可以有不同的推送速度,归根到底是偏向对订阅方的保护了
5.对于分布式事务,服务器主动询问发送方实现机制能不能详细讲解实现机制,尤其是发送方的处理
比如你购买会员:扣钱在本地mysql操作,然后要通知会员系统给用户发送会员
这个时候都有可能失败,所以kiteq的处理就是先发一个未提交的消息给kiteq,然后处理本地事务,本地事务处理成功就发送commit消息、如果处理失败就会提交rollback。如果本地事务处理时间比较长或者正好发送方挂掉了,那么服务端就会根据配置去回扫未提交的消息,并下发txack消息用于询问本地事务是否成功。这样客户端和服务端同时保证,未提交消息的最后确定的状态。
6. 一个topic或者messagetype的msg会发送到不同的kiteq节点上吗。然后一个group描述了topic、msgtype、produsers、consumers的关系?一个topic可以在多个group吗
同一个topic的消息会发送到不同的kiteq上,因为KiteQ也是集群,具体的负载均衡是客户端逻辑,当前采用的是随机
topic这些事跟消息相关的、group是用来划分不同集群,两者属于不同类别的概念
7. 推1,2,3。收1,3,2。接收端怎么知道这个顺序。设计一组消息时对顺序有严格要求的加个sort标识吗
1、2、3是代表你的业务顺序号,比如统一个订单有订单创建、未支付、支付完毕,1、2、3指的这个
所以你的消息里肯定有orderid,当然你可以把你的业务id放在消息头部便于对这种进行处理
你要有序那就必须严格显示跳转啦
9. 使用zk 做订阅关系管理 主要考虑 zk的服务发现和良好的异步通知功能吧?还要其他考量么
zk偏向成熟吧。
10 protobuf的使用是基于什么考虑呢,为何不用简单的jsonrpc
至于json和pb的选择 json的类型约束太弱了,而且效率和压缩方面pb好于json。
11. 为什么不在Kafka的基础上做扩展?
kafka还是感觉太重了些。而且如果在一个公司考虑运维成本和开发成本来说,开发一个代价相对较小吧。
12. kiteq 和 nsq 区别列举一些,为什么说nsq可靠性不太够
(不可靠因为)是否是消息来了持久化存储
是否给发送方以回馈消息持久化成功
在订阅方宕机的期间的消息是否在恢复后能够收到期间的消息
这个也是非常重要的衡量标准
13 之前的问题,如果生产者在收到反馈前崩溃或mq崩溃,能否之后确认消息持久化
生产者和MQ之间是同步关系。所以状态是清楚的,超时、失败都认为是失败需要重新发送,只有明确告知发送方成功才认为是成功的
这一阶段跟普通的RPC是一样的
调用成功就是成功失败就是失败哪怕是超时
所以说重复消息必然会有。发送方超时重新发送、接收方失败重投。。。
(怎么去重?)消息ID是一方面,然后你的消息头部可以定义你的业务ID号 然后本地数据库保持这些业务ID号对应的状态 同一个事务多条消息.....
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

