N1QL为NoSQL数据库带来SQL般的查询体验
关系型数据库已经流行了超过40年,在这个过程中SQL也成为了操作关系型数据库的标准。SQL将数据的存储方式进行了包装和抽象,使开发人员可以专注于程序逻辑。对开发人员工作的简化也是SQL甚至关系型数据库流行的原因。
社会在发展,数据在变化。从社交网络、科学研究、物联网等数据源产生的数据已经不局限于某个固定的结构,因此对于这些数据擅长结构化数据的关系型数据库就难以处理了。
关系型数据库最好有固定的schema,这也使得满足现代商业要求的敏捷性和快速迭代变得困难。动态schema不仅仅要求我们重新思考数据模型和数据库,我们还需要一门新的查询语言来读取这些数据。
数据模型
我们先来看看数据模型。九十年代开始随着图形界面应用和Web应用的流行,多数商业应用的程序都使用面向对象的开发模式。对于Web应用来说JSON是表示数据对象的标准,服务器和应用之间交换的就是一个个JSON文件。两千年左右NoSQL数据库开始流行起来,NoSQL数据库的目的就是方便存储和管理JSON文件。
JSON数据库很受开发人员的喜爱,因为它表示数据的方式和其他面向对象的程序设计语言如Java、C++、.NET、Python和Ruby等是一样的而且可以有灵活的schema。然而文件数据库的开发人员一直以来都欠缺好用的查询语言。
文件数据库查询语言的欠缺使开发人员陷入了两难的境地:要么享受JSON灵活的数据模型要么享受关系型数据库的SQL但两者不可兼得。
查询语言
N1QL(发音是“妮叩”)是一门将SQL引入文件数据库的查询语言。讲得技术一点,JSON是不符合第一范式的数据模型,而N1QL则对这一数据模型进行操作。N1QL将传统SQL对表和行的操作拓展至JSON (嵌套文件)。
将SQL引入JSON有点像汽车油改电,虽然引擎换了但驾驶员的操作方式保持不变。现在开发人员既可以使用熟悉的SQL来操作又可以动态扩展应用的schema。
下图中是SQL和N1QL中join的写法的一个简单例子。想要深入学习N1QL的话请移步到Couchbase的N1QL教程。
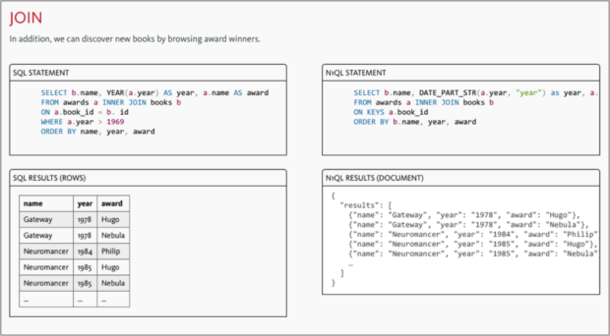
扩展SQL而不是完全重新创造一门语言的好处是SQL中经典的关键字操作符排序集合等功能都可以进行复用。这极大地降低了开发人员使用N1QL的门槛。
不过关系型数据库和文件数据库的模型总归是不同的,所以N1QL也有一些新的东西。比如N1QL引入了NEST和UNNEST关键字来集合或分解嵌套的对象、IS NULL和IS MISSING来处理动态schema以及ARRAY函数来对数组元素进行遍历或过滤。
新型数据模型的灵活性与开发人员熟悉的查询语言的强大功能相结合为下一代更灵活更强大的应用开发打下了良好的基础。开发者们借着妮叩尽情享受文件数据库吧!
原文链接: N1QL brings SQL to NoSQL databases (译者/刘旭坤 审校/朱正贵 责编/仲浩)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

