使用 Rational Performance Tester 执行 WebSphere Commerce 性能测试,第 2 部分: WebSphere Com...
简介
随机浏览的目的是遍历目录结构并打开一个产品页面。WebSphere Commerce 目录由顶级类别、子类别和产品来表示。浏览从顶级类别开始,然后到子类别,直到达到某个产品页面。
WebSphere Commerce 中最近引入了一个叫做 “分面导航” 的特性,它允许用户直接导航到产品。基本上讲,分面导航按颜色、大小和类型等属性来过滤产品,仅显示与选定的属性相匹配的产品。
为了更好地使用缓存,我们实施了 80/20 规则。此规则可确保 80% 的目录请求针对的是 20% 的目录产品。这导致产生许多被重复访问的目录和产品页面,因此缓存命中率更加真实。此规则在目录树比较均衡时的效果更好;也就是说,在每个导航路径下包含相同数量的子类别和产品时效果更好。在测试环境中推荐均衡目录树。
图 1显示了全文中使用的目录分层结构,也显示了 80/20 规则。该规则可确保 topCat1 在 80% 的时间被访问,这也使用户在 80% 的时间浏览到产品 Prod1 到 Prod6。
图 1. 目录和 80/20 规则

在 Rational Performance Tester 中,有两种方式来实现随机浏览:
- 静态浏览,由数据驱动
- 动态浏览,也就是爬网(web crawling)
我们使用一个示例来查看每种浏览技术。
静态浏览
静态浏览使用固定的、预先定义的 HTTP 请求数量。这方面的示例包括请求浏览到主页、顶级类别、子类别和产品页面。
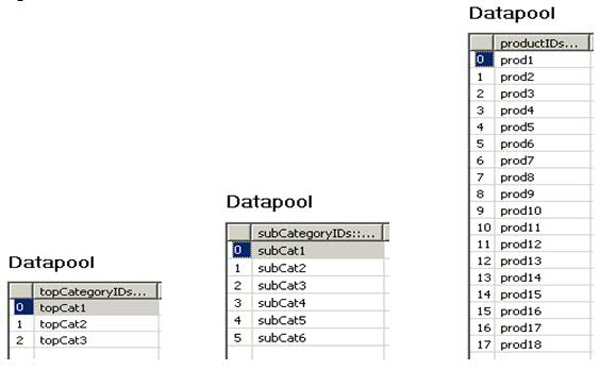
请求参数需要替换为实际的类别 ID 或产品 ID。也就是说,它意味着需要在执行测试之前知道 ID(类别和产品)。在 Rational Performance Tester 中,数据池用于存储这些 ID,并用于代入测试的请求参数。一个数据池用于顶级类别,另一个数据池用于子类别,还有一个数据池用于产品,如图 2所示。在此示例中,使用了类别和产品名,而不是 ID 编号。
图 2. 数据池
对于每种类型的页面(主页、顶级类别、子类别和产品页面),需要一个 HTTP 请求即可浏览到该页面。每个请求可放在一个单独的页面中。用绿色突出显示的变量替换为各自的数据池中的值,如图 3所示。
图 3. 将数据池链接到 URL

此测试具有固定的顺序(主页 → 顶级类别 → 子类别 → 产品),所以每个用户重复同样的路径,但用户可以为请求选择不同的 ID。但是,不是所有购买者都具有此行为。要在更真实的浏览场景中进行测试,一些用户会浏览到主页并离开,其他用户会继续浏览到顶级类别,然后离开,另一些用户继续浏览到一个子类别并离开,还有一些用户可能会浏览到产品页面才离开。
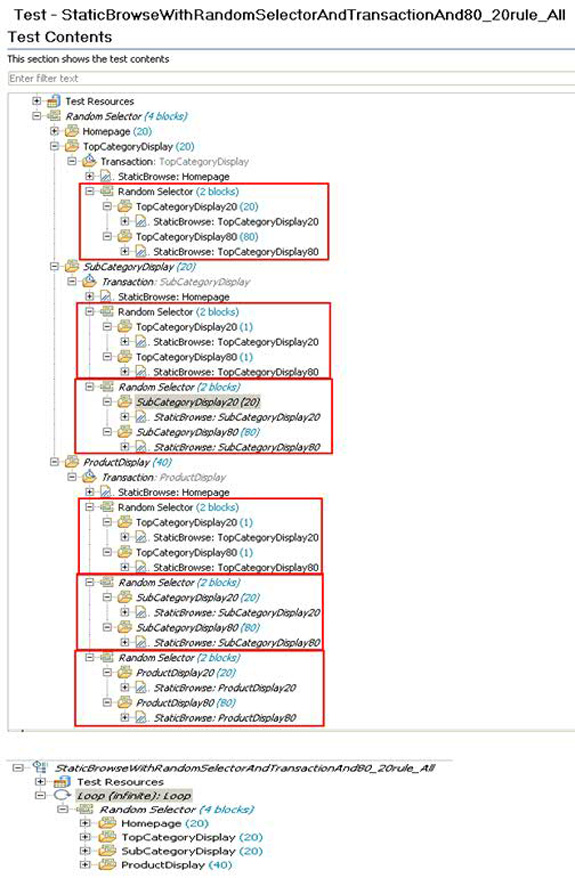
此行为使用随机选择器来实现。这 4 个 HTTP 页面放在此选择器内,每个页面位于一个 Weighted Block 中。假设 20% 的用户仅浏览到主页,20% 的用户浏览到顶级类别,20% 的用户浏览到子类别,40% 的用户浏览到产品。图 4显示了此测试。
图 4. 随机选择器
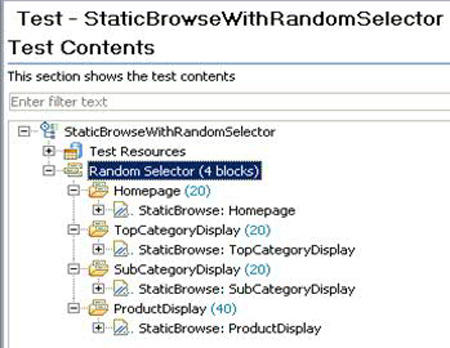
如果运行图 4中所示的测试,会让一个用户直接挑选一个主页、顶级类别页、子类别页或产品页面。如果此浏览类型满足了需求,则没有必要进一步更改测试。但是,如果这些需求指定:用户需要从上至下浏览,而且只有首先访问顶级类别和子类别页,才能到达产品页面,那么您需要修改测试来满足此需求。
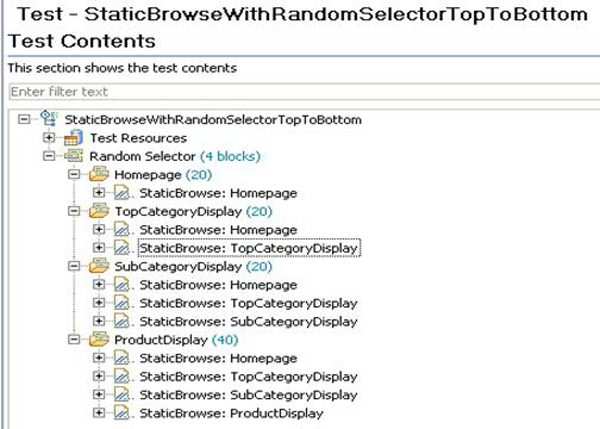
要让用户在打开一个产品页面之前经历一个顶级类别和一个子类别,ProductDisplay 块应拥有前述所有请求。其他代码块也应拥有前述所有请求。图 5显示了经过修改的测试。
图 5. 自上而下浏览的随机选择器
前面(第 1 部分中)已解释过,您可以将每个选择器下的每组页面放入一个事务块中,如图 6所示。
图 6. 随机选择器和事务

我们现在更进一步,实现了 80/20 规则。
80/20 规则
为了让测试环境更加真实,可以使用 80/20 规则来确保 80% 的请求针对的是 20% 的目录产品。这会导致反复访问许多类别和产品,从而具有更高的缓存命中率。
要实现此规则,需要在 80% 的时间里拾取 20% 的顶级目录。随机拾取一个子类别,然后随机拾取一个产品。
因为有 3 个顶级类别(topCat1、topCat2 和 topCat3),所以确保 80% 的时间拾取了第一个顶级类别 topCat1。然后,对于剩余 20% 的时间,确保随机拾取了两个剩余的顶级类别(topCat2 和 topCat3)中的一个(在 3 个顶级类别中,66% 的时间拾取了 topCat1,剩余 33% 的时间拾取了其他顶级类别中的一个)。
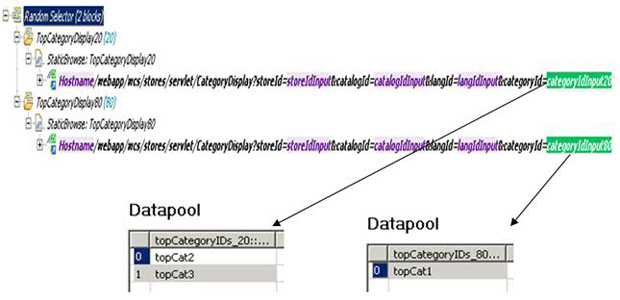
采用的方法是将顶级类别的数据池分解为两个数据池。一个数据池仅包含 topCat1,而且在 80% 的时间内被拾取。另一个数据池包含 topCat2 和 topCat3。在这里,随机选择器同样变得很方便。您使用两个代码块,一个代码块的权重为 80,负责浏览到第一个类别;另一个代码块的权重为 20,负责浏览到剩余的两个类别。
这些代码块下的 HTTP 请求是相同的,但一个链接一个新创建的数据池,另一个链接到另一个新创建的数据池。图 7显示了数据池的拆分方法(80 和 20)。
图 7. 拆分数据池
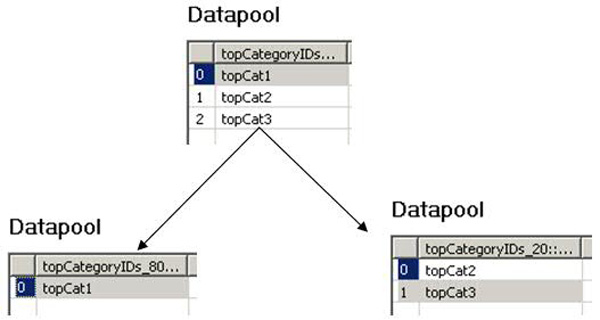
图 8显示了最终的测试。
图 8. 应用 80/20 规则

图 9. 与新数据池的链接
根据现在这个进度表中实现的,这种静态测试可让一个虚拟用户浏览到一个顶级类别,然后浏览到不属于这个顶级类别的子类别,然后浏览到不属于这个子类别的产品。根据此行为,80/20 规则没有得到遵守。
要在之前描述的目录中遵守此规则,需要在 80% 的时间里访问 topCat1,以及这个顶级类别下的所有子类别。
要实现此行为并遵守 80/20 规则,您需要拆分子类别和产品数据池,采用浏览到顶级类别时所采用的相同方式,在进度表中添加随机选择器,如图 9所示。在拆分数据池后,它们如图 10所示。
图 10. 顶级类别、子类别和产品数据池
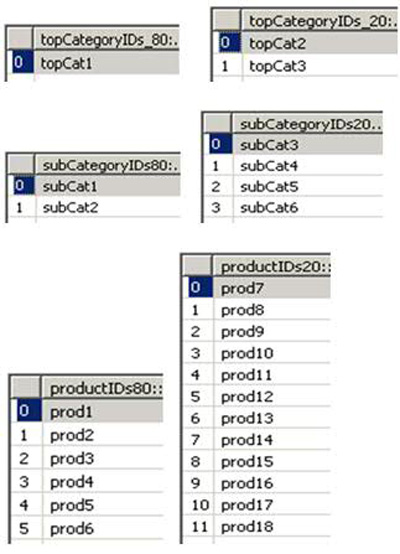
图 11显示了最终的测试。
图 11. 最终测试
点击查看大图
关闭 [x]
图 11. 最终测试
静态的浏览的重要优势是容易实现。测试人员不需要创建任何正则表达式来获取产品或类别 ID,也不需要首先实现任何自定义代码。它是一种在浏览类别和产品时快速获得响应的方式。
以下几点总结了静态浏览的一些不足之处:
- 在静态浏览中,所选的类别可能并未真正链接到最终产品。
- 静态浏览链接到的是数据,这意味着更改数据会更改测试。添加或删除一个类别后,测试人员需要在测试中添加或删除代码块;而且在添加产品时,测试人员需要更新数据池。
这些不足使得测试不可移植,因为它无法原封不动地用于测试另一个 Commerce 类别。
动态浏览
在动态浏览中,不需要知道目录分层结构、产品或类别 ID 就可以构建动态浏览测试。这种浏览尊重父子关系,所以避免了静态浏览的不足之处。
执行动态浏览的方式是,首先访问一个包含所有顶级类别 ID 的页面,随机拾取一个类别 ID,然后浏览到它。对其他类别重复此过程,直到您到达某个产品页面并选择一款随机产品。
动态浏览节使用了前面的静态浏览部分中定义的相同目录。
在讨论实现动态浏览的细节之前,让我们看看如何在这种情况下实现 80/20 规则。
80/20 规则
为了使测试环境更加真实,可以使用 80/20 规则来确保 80% 的请求针对的是 20% 的目录产品。这会导致反复访问许多类别和产品,进而具有更高的缓存命中率。
实现 80/20 规则的一种方式(请注意还有其他方式)是使用以下公式:
f(x) = floor(N*x^7)
其中:
- x 是使用均匀分布 0<=x<1 而随机生成的一个数。
- N 是要浏览的项目数。
此公式仅用于获取一个随机顶级类别。
在一个自定义代码中,如果顶级类别位于一个名为 topCategoryList 的数组中,那么拾取一个遵守 80/20 规则的随机类别的公式类似于:
i = ( int )( Math.floor( topCategoryList.size() * Math.pow( Math.random(), 7 ) ) );
其中:
- topCategoryList.size() = N。
- Math.random() = x。
- i 是顶级类别列表 topCategoryList 数组中从 0 开始的索引。
公式中的数字 7
如果在 80/20 规则公式中使用了数字 1 代替数字 7,那么每个产品都具有同等的拾取机会(正太随机)。
在 Rational Performance Tester 中,测试通常是从一条记录中构建的。以下是一条经历了以下路径的记录:
Home page → Sitemap → topCat3 → subCat6 → Prod17
在记录后,添加了一个输入变量,而且仅保留了主要的 URL。
图 12. 随机浏览记录

如果反复运行此测试,它始终会经历相同的路径。
要让此测试动态地适用于任何目录树,它需要从站点地图响应内容中拾取一个随机子类别,并浏览到该子类别。然后,它需要从响应中拾取另一个随机子类别,并浏览到该子类别。它需要不断这么做,直到到达一个产品页面并浏览到某个随机产品。
下面展示了如何使用伪代码将一条简单浏览的记录转换为动态浏览测试。
以下步骤给出了记录的伪代码(R 表示记录):
- R1 - Browse to the home page.
- R2 - Browse to the Sitemap.
- R3 - Browse to top category topCat3.
- R4 - Browse to subcategory subCat6.
- R5 - Browse to top category Prod17.
要编写一种浏览任何 Commerce 目录的一般性测试,需要保留步骤 R1 和 R2。它们在表 1的右侧显示为 T1 和 T2(T 表示测试)。从步骤 T2 上的站点地图,拾取了一个随机的顶级类别。表左侧的步骤 R3 和 R4 转换为了一个循环。此循环浏览到一个子目录,从响应内容获取一个随机子类别,然后浏览到该子类别。只要能在响应内容中找到子类别,循环就会继续执行。该循环如表右侧的步骤 T4 中所示。
如果没有找到子类别,则意味着到达了某个产品页面。在这种情况下,会拾取一个随机产品,并终止循环。然后,该产品会在步骤 T13 上显示。
表 1. 从记录伪代码转换为测试伪代码
| 记录伪代码 | 测试伪代码 |
|---|---|
| R1 - 浏览到主页。 R2 - 浏览到网站地图。 R3 - 浏览到顶级目录 topCat3。 R4 - 浏览到子目录 subCat6。 R5 - 浏览到顶级目录 Prod17。 | T1 - Browse to the home page. T2 - Browse to the Sitemap. T3 - Pick one top category from the Sitemap in CategoryLink. T4 - Loop. T5 - If CategoryLink != none. T6 - Then. T7 - Browse to a CategoryLink. T8 - Parse and pick a category in CategoryLink or set it to none. T9 - Parse and pick a product in ProductLink or set it to none. T10 - Else. T11 - BreakLoop. T12 - End Loop. T13 - If ProductLink != none. T14 - Browse to ProductLink. |
清单 1中的伪代码与表 1右侧的伪代码相同。但是,添加了一些内容,我们稍后将解释。此伪代码是使用与 Rational Performance 测试类似的方式编写的。
清单 1. 动态浏览伪代码
点击查看代码清单
关闭 [x]
清单 1. 动态浏览伪代码
1 - Browse to the Sitemap page or a page with all top-categories. 2 - Custom Code: SiteMapParseTopCategories(). 3 - Set CategoryLink = SiteMapParseTopCategories(). 4 - Loop (infinite). 5 - If CategoryLink != “none”. 6 - Then // Another category is found. Browsing down to it. 7 - Browse to the URL=http://hostname/CategoryLink. 8 - Parse for CategoryLink in the response of the previous URL or set CategoryLink to “none”. 9 - Parse for ProductLink in the response of the previous URL or set ProductLink to “none”. 10 - Else // This is a product page. Exit the loop and try to display a product later. 11 - Custom Code: BreakLoop(). 12 - End Loop. 13 - If ProductLink != “none”. 14 - Browse to the URL=http://hostname/ProductLink.
采用将记录伪代码转换为测试伪代码的相同方式,将记录的测试转换为动态浏览测试。这一节会多次引用清单 1中的伪代码,展示在以下步骤将要更新/转换的当前行:
- 添加一个循环
在 Rational Performance Tester 测试编辑器中,创建一个无限循环,将两个页面放在循环内的站点地图下,操作如下所示:
选择两个页面 → 右键单击 → Insert → Loop。
这可以在图 13中的屏幕截图中直观地看到。
图 13. 添加一个循环

将循环持续时间设置为无限,如图 14所示。
图 14. 无限循环

添加两个变量 CategoryLink 和 ProductLink 后(它们已在清单 1的第 7 行和第 14 行中突出显示),测试如图 15所示。
图 15. 添加一个循环后

- 自定义代码
在清单 1中的动态浏览伪代码中,有两段自定义代码 SiteMapParseTopCategories 和 BreakLoop。第 2 行的 SiteMapParseTopCategories 解析站点地图的响应内容,以检索所有顶级类别链接,然后应用 80/20 规则来随机拾取其中一个链接。第 11 行上的 BreakLoop 将会退出循环。
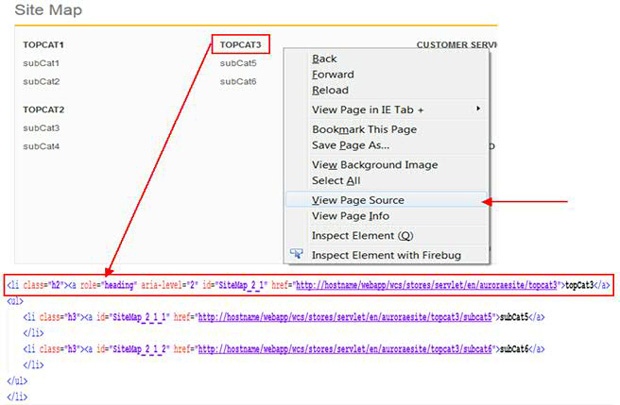
图 16展示了如何从站点地图页面源代码获取所有顶级类别。
图 16. 查看页面源代码
对于 topCat1
点击查看代码清单
关闭 [x]
<li id="SiteMap_1_1" class="h2"><a role="heading" aria-level="2" href="http://hostname.domain.com/webapp/wcs/stores/servlet/en/auroraesite/topcat1">topCat1</a>
对于 subCat1
点击查看代码清单
关闭 [x]
<li id="SiteMap_1_1_1" class="h3"><a href="http://hostname.domain.com/webapp/wcs/stores/servlet/en/auroraesite/topcat1/subcat1"> subCat1</a>
这些链接中的单词 SiteMap 后跟表示顶级类别的两个数字 (_1_1) 和表示子类别的 3 个数字 (_1_1_1)。利用此区别,下面的正则表达式仅检索顶级类别链接:
SiteMap_[0-9]+_[0-9]/ ".*?href=/"http://[^/]+([^/"]+)/"
要检查此正则表达式是否正确,可使用如何检查正则表达式部分中讨论的类。请参阅这一部分,查看如何验证响应内容上的正则表达式。
将该类用于站点地图,将在控制台上生成如图 17所示的输出。
图 17. 控制台输出

这正是我们需要的;因此,站点地图正则表达式是正确的。
该正则表达式添加到记录的测试中,如图 18所示。
图 18. 向测试添加自定义代码
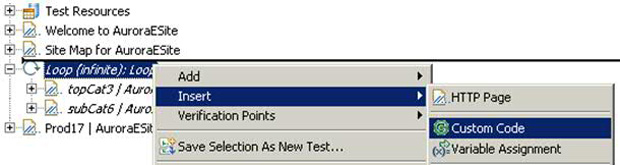
下面给出了 SiteMapParseTopCategories 的代码:
package custom; import com.ibm.rational.test.lt.kernel.services.ITestExecutionServices; import java.util.ArrayList; import java.util.regex.Matcher; import java.util.regex.Pattern; public class SiteMapParseTopCategories implements com.ibm.rational.test.lt.kernel.custom.ICustomCode2 { public final static String regex="SiteMap_[0-9]_+[0-9]/".*?href=/"http://[^/]+([^/"]+)/""; public final static Pattern pattern = Pattern.compile(regex,Pattern.DOTALL); public SiteMapParseTopCategories() {} public String exec(ITestExecutionServices tes, String[] args) { // INPUT arguments String text=args[0]; // LOCAL variables String result="none"; ArrayList<String> topCategoryList=new ArrayList<String>(); Matcher matcher = pattern.matcher(text); while (matcher.find()) { result=matcher.group(1); result=result.replaceAll("&", "&"); if (!topCategoryList.contains(result)) { topCategoryList.add(result); } } if (topCategoryList.size()>0) { int i = (int)(Math.floor(topCategoryList.size()*Math.pow(Math.random(),7))); result=(String)topCategoryList.get(i); } tes.getTestLogManager().reportMessage("ParseTopCategories: "+result); return result; } }站点地图响应内容需要作为参数传递给 SiteMapParseTopCategories 自定义代码。要定义此参数,可为站点地图响应内容创建一个字段引用,如图 19所示。选择站点地图的响应内容。
图 19. 选择响应内容

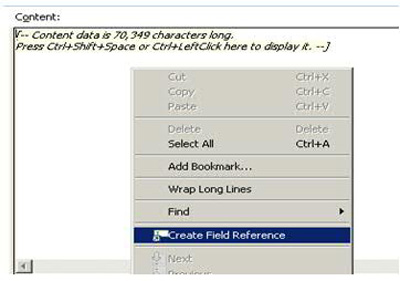
在 Content 字段中右键单击并选择 Create Field Reference 命令,如图 20所示。
图 20. 创建一个字段引用
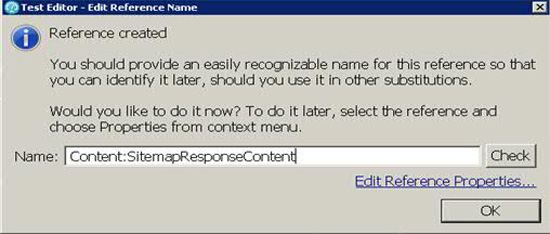
为该引用提供一个名称,如图 21所示。
图 21. 命名引用
最后,选择该自定义代码并添加参数,如图 22所示。
图 22. 添加参数

与前面的自定义代码相比,BreakLoop 是一段较小的自定义代码。它包含对下面这个函数函数的一次调用:
tes.getLoopControl().breakLoop()
它会在以后添加到测试中。
- 设置 CategoryLink
在清单 1中的动态浏览伪代码中,CategoryLink 在自定义代码中的第 3 行和响应内容的第 8 行设置。采用与从站点地图检索随机顶级类别的相同方式,您可编写自定义代码来解析响应内容,以获得一个随机子类别;但是,设置此变量无需任何自定义代码。添加站点地图的自定义代码,只是为了能够在此代码中使用 80/20 规则的公式。
首先:编写正则表达式。
响应内容中的子类别名称使用正则表达式来搜索。
图 23. 子类别的链接

该正则表达式需要匹配所有子类别链接。也就是说,需要匹配图 23中突出显示的内容。
下面这个正则表达式将会查找响应内容中的所有子类别链接:
<a id=/"SBN_[^/"].*?/" href=/"http://[^/]+(/[^/"]+)
在子类别页面上使用如何检查正则表达式部分中介绍的类来测试这个正则表达式,将得到图 24中所示的输出。
图 24. 控制台输出

这完全满足我们的需求。
第二:更改响应内容。删除所有响应内容,仅保留以下这行:
<a id="SBN_Link" href="http://hostname/CategoryLink
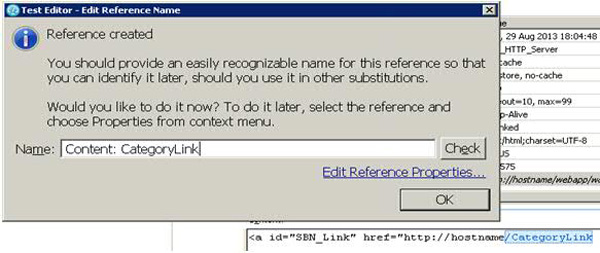
第三:创建一个引用。创建 /CategoryLink 的引用,如图 25所示。
图 25. 创建一个引用
最后:设置引用的特性。
选择该引用并右键单击,在上下文菜单中选择 Properties 命令。在出现的 “Properties for” 弹出窗口中,将正则表达式更改为您之前找到的一个正则表达式,然后选择 Random occurrence 单选按钮,如图 26所示。
图 26. 设置引用的特性

如果未找到子类别,必须退出循环。此行为在同一个弹出窗口中的 Error Handling 选项卡中定义,如图 27所示。
图 27. Error Handling 选项卡

单击 Change 按钮并选择合适的选项,如图 28所示。
图 28. 发生错误时执行的操作

-
设置 ProductLink
ProductLink 在清单 1中的动态浏览伪代码中的第 9 行设置。它的设置方式与 CategoryLink 相同。请参见图 29。
图 29. 产品链接

下面这个正则表达式将会对所有产品链接进行匹配:
点击查看代码清单
关闭 [x]
<a id=/"WC_CatalogEntryDBThumbnailDisplayJSPF.*?[^/"]/".*?href=/"http://[^/]+(/[^/"]+)"
使用如何检查正则表达式部分中提供的 CheckRegex 类来测试它,会得到图 30所示的输出。
图 30. 控制台输出
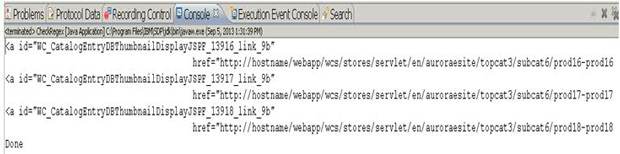
这一次,会以与之前相同的方式更改响应内容,响应内容中保留了以下内容:
点击查看代码清单
关闭 [x]
<a id="WC_CatalogEntryDBThumbnailDisplayJSPF_link" href="http://hostname/ProductLink.
将前一行放在已更新的相同响应内容中;也就是 topCat3 页面的响应内容中(参见图 15)。
更新响应内容后,以之前描述的相同方式创建一个引用并更新它的特性(更改正则表达式和发生条件)。
图 31. 更新响应内容

-
删除不需要的页面。
页面 “subCat6 | AuroraESite” 不需要,因为所有子类别(顶级类别和子类别)都已在 “topCat3 | AuroraESite” 页面的循环中抓取。请参见图 15。
此删除操作会在循环中仅留下一个页面。
-
更改一些页面名称。
将页面名称 “topCat3 | AuroraESite” 更改为更一般性的名称,比如 “Category Display”。类似地,将页面名称 “Prod17 | AuroraESite” 更改为更一般性的名称,比如 “Product Display”。此更改可帮助提升运行结束时生成的页面性能报告的可读性。
-
添加 IF-THEN-ELSE。
要实现清单 1的第 5 行上的 IF 分支,可选择循环中的所有页面并插入一个 if 条件,如图 32所示。该 if 条件用于测试是继续还是退出无限的子类别循环。
图 32. 添加一个条件

设置条件的特性,如图 33所示。
图 33. 条件的参数

添加一个 Else 块(清单 1中的第 10 行),如图 34所示。
图 34. 添加一个 Else 块

将 BreakLoop 自定义代码添加到 Else 块下。
- 向 CategoryLink 和 ProductLink 变量赋值。
向 CategoryLink 添加一个变量赋值,如图 35所示。
图 35. 添加一个变量赋值

从数据源选择一个值,如图 36所示。
图 36. 选择变量的数据源

选择 CategoryLink 引用,如图 37所示。
图 37. 选择引用

对 ProductLink 变量重复相同的步骤。
- 将类别和产品显示链接替换为相应的变量。
将 “Category Display” 页面的 URL 更改为 CategoryURL,将它替换为 CategoryLink 变量,如图 38所示。
图 38. 替换变量

对 “Product Display” 页面重复同样的步骤,将产品 URL 替换为 ProductLink。
- 在产品显示之前添加一个 if 测试。
如清单 1中第 13 行所示,在显示产品之前测试 ProductLink 值。
-
最终的脚本类似于图 39中所示的输出。
图 39. 最终的脚本

以下几点总结了如何将记录转换为动态浏览测试:
- 在记录中,构建一般性的伪代码来浏览目录。
- 更改记录以让测试一般化(添加了一个循环来取代一直到产品页面的类别遍历)。
- 在自定义代码和引用的特性中,测试了正则表达式并使用它们来获取随机内容。
- 在自定义代码中实现 80/20 规则并添加到测试中。
注意:
仅实现了浏览。如果请求实现一个完整的购物流,还必须考虑订单部分。这通过从显示的产品中提取参数值(比如 catEntryId)并将它们添加到购物车中来实现。
如何检查正则表达式
这一节提供了两种检查正则表达式的方式:
- 内联测试正则表达式
- 创建一个 Java 类来检查正则表达式
内联测试正则表达式
创建引用时,在引用上对正则表达式执行内联测试。查看引用特性或右键单击任何引用并选择 Properties 。在 Properties 窗口中,单击正则表达式右侧的按钮来测试正则表达式,如图 40所示。
图 40. 内联测试正则表达式

创建一个 Java 类来检查正则表达式
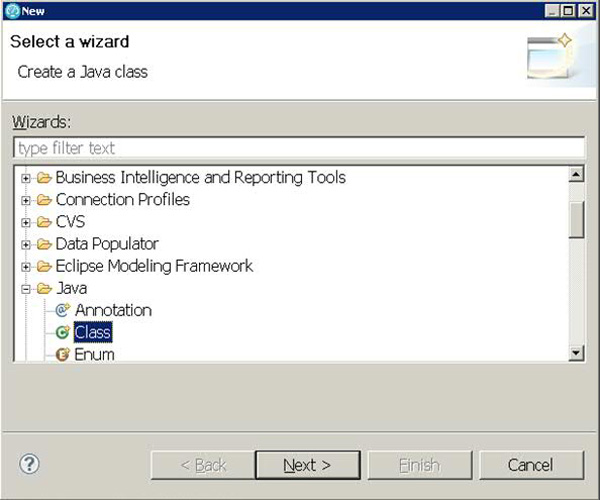
要在 Rational Performance Tester 中创建一个 Java 类,可选择:
- File → New → Other … → Expand Java folder → Choose Class,如图 41所示。
图 41. 创建 Java 类
- 单击 Next 。此时将会显示一个 New Java Class 窗口。
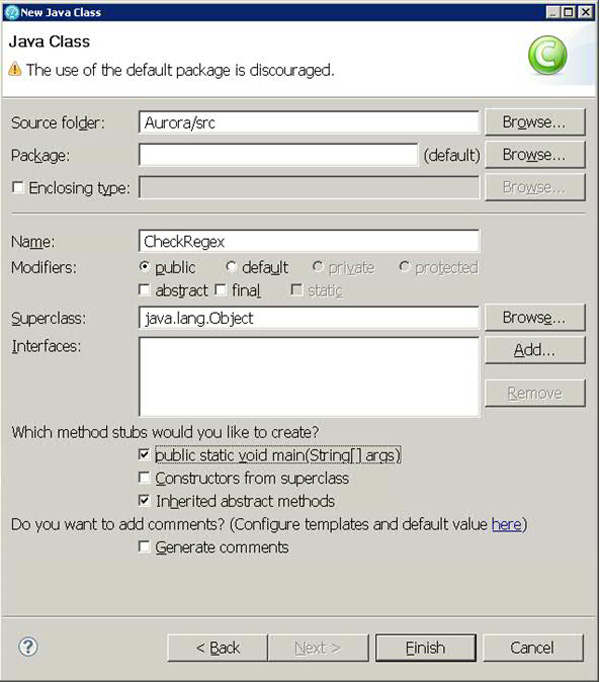
- 在 Name 字段中键入该类的名称,选择复选框 public static void main(String[] args) ,如图 42所示。
图 42. 设置 Java 类的特性
- 单击 Finish 。Rational Performance Tester 为您创建了一个空类,如图 43所示。
图 43. 创建的新的空 Java 类

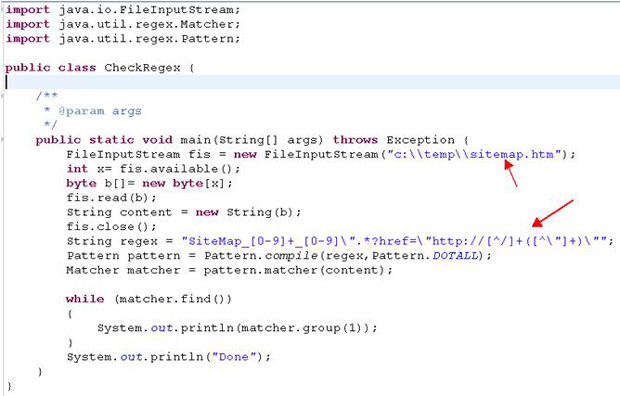
- 将以下代码放在主要类中:
FileInputStream fis = new FileInputStream("c://temp//sitemap.htm"); int x= fis.available(); byte b[]= new byte[x]; fis.read(b); String content = new String(b); fis.close(); String regex = "SiteMap_[0-9]_+[0-9]/ ".*?href=/"http://[^/]+([^/"]+)/""; Pattern pattern = Pattern.compile(regex,Pattern.DOTALL); Matcher matcher = pattern.matcher(content); while (matcher.find()) { System.out.println(matcher.group(1)); } System.out.println("Done"); -
将前面的文本添加到代码中时,编辑器会显示一些有关使用的类型的错误。您需要添加以下导入语句:
import java.io.FileInputStream; import java.util.regex.Matcher; import java.util.regex.Pattern;
还需要添加 “throws exception”,如下所示:
public static void main(String[] args) throws Exception {图 44显示了整个类。
图 44. 完整的类
每次您想要使用此类来测试正则表达式时,需要注意以下几点:
- 更改类中的变量 regex 来更改正则表达式公式本身。
- 将您想要引用此正则表达式的页面保存到一个文件中,将 fis 变量更改为新文件的完整路径,已在图 44中用箭头突出显示。
- 请注意使用了转义字符 “/”。使用它是因为正则表达式字符串包含双引号标记。
结束语
在这个关于使用 Rational Performance Tester 设计测试的文章系列的这一部分(第 2 部分)中,逐步实现了一个真实的 WebSphere Commerce 浏览场景。本文介绍了两种浏览方法:静态浏览和动态浏览。对于这两种方法,本文介绍了如何实现 80/20 规则。
本系列第 3 部分将提供一些调试 Rational Performance Tester 的最佳实践。
致谢
非常感谢来自 Rational Performance Tester 开发团队和 WebSphere Commerce 性能团队的以下人员提供的帮助、审阅和宝贵建议。
- Kent Siefkes - 首席架构师,Rational Performance Tester
- Dawn Peters - 软件设计师,Rational 质量和需求管理
- Andrei Moraro - 团队中来自多伦多大学的实习生
- Alejandro Octubre - 团队中来自麦克马斯特大学的实习生
回页首
下载
| 描述 | 名字 | 大小 |
|---|---|---|
| 静态浏览工件 | StaticBrowserWithRandomSelectorAndTransactionWith80_20Rule.zip | 46KB |
| 动态浏览工件 | DynamicBrowsing.zip | 62KB |
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

