假如不是BAT,专项测试要怎样做?
其实这个话题对于身在BAT的我来说,是个难题。因为BAT对测试本身的投入力度,在行业内是走在前面的。一直在这个环境成长,可能会不理解其他小团队的痛。但是我意识到,必须写一篇文章,一方面是因为最近 确实 接触了一些腾讯系公司,了解了他们的测试现状,我觉得需要有所总结; 另一方面是希望自己透过这个文章有更进一步的思考,最终能给出一些可以真正帮助到测试行业内其他团队的意见。
心理篇
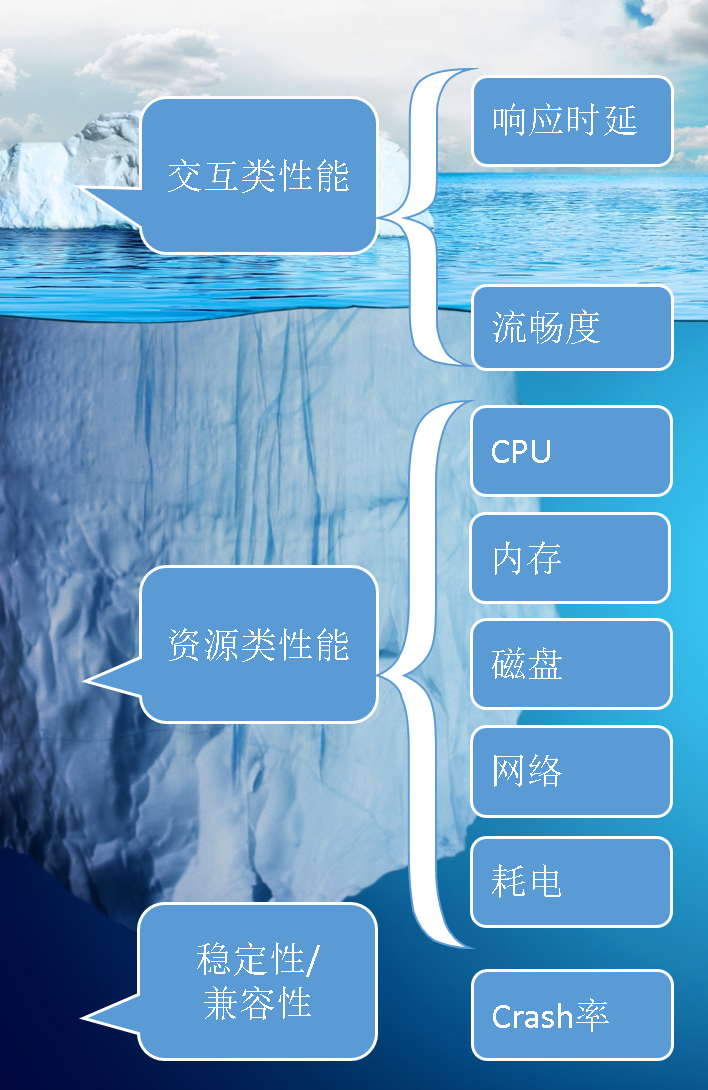
我在QCon北京上的演讲《 手Q专项测试最佳实践 》中曾经提过,专项测试有资源类性能、交互类性能、稳定性、兼容性和安全性等等。但仔细想想,对于一个小团队,一个创业或创业初成的团队需要管那么多吗?不用,只要心中有概念, 并有对应保底措施即可。对于小团队来说,更重要的应该是 打痛点 ,因为痛点是产品发展的最大障碍,具备极高的性价比。但是什么是痛点呢?表面上很多产品都知道自己的痛点,其实并非如此。在不了解用户反馈的情况下,说自己明白用户的痛点,并且创造产品需求的比比皆是。所以对于专项测试而言,第一步无疑是找痛点。
第一步是建设反馈系统,找痛点。 这种反馈包括各种用户反馈的收集分析,各种专项数据的前段和后端的上报分析。有一些如 听云 、 OneAPM , Bugly 其实已经有一些这种监控上报的能力,只可惜在用户反馈收集和分析上,暂时没见到对应的系统。所以在应用现有系统的基础上,可能还需要自建。那么,假如有了这些系统,帮助我们知道有多少用户遇到卡死, 实际Crash率是多少,多少用户说耗费流量,实际终端耗费流量上报结果是多少。这时,痛点自然就一目了然,未来能达成的目标也清晰可见,老板也许会更加清楚地了解问题的 严重性 ,从而下定决心改善。
第二步是找底线和目标。 我们有了反馈系统,知道了用户的实际情况,这时我们就需要根据数据让团队自上而下地明确底线和目标,从而提升后续团队合作的效率。目标可以是,Crash率是多少不让发布,Crash率是多少可以不FIX, 切换界面底线是多少,百分之多少的用户的流畅度是多少,用户反馈的卡顿问题从TOP10问题剔除等等。
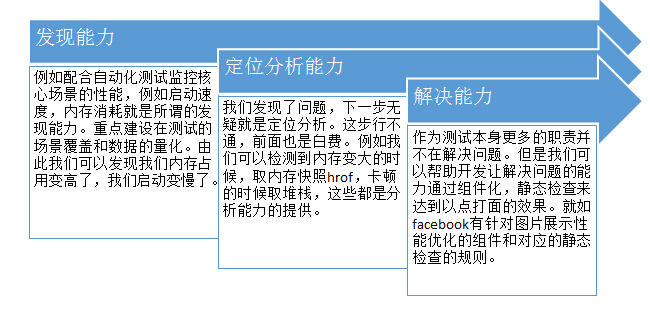
第三步是解决问题 。有痛点有解决痛点的目标,我们就要行动,为了达成目标,解决问题。我们以及我们的平台需要具备如下三个能力:
第四步是回到反馈系统,展示效果。 开发,测试忙活了许久,达成了效果,却没有展示,那就是错失了开发与测试形成信任关系闭环的最佳时机。当然也缺失了进一步改进,做就精品的机会。就如我们的上传图片,一开始的目标仅仅是提高成功率,然后就是让带宽好的传输速度更快,再后就是让网络差的也能在保证成功的基础上再快点,再想办法搭救更多的在演唱会时发送不出消息和图片的用户,一路上都是不断地看数据上报,分析,解决问题,展示效果,再分析,再解决,再展示效果,形成闭环。
工具篇
一般来说,用户最痛苦的专项问题,通常是最表面和直观的问题,包括:
闪退: 包括CRASH,系统强杀,ANR,直接影响用户的使用。
卡顿: 包括丢帧,动画帧率低,相应用户操作速度慢,甚至是卡死,但却没有触发ANR或者watchdog timeout。这些给用户的感觉就是用得不爽,尤其是有对比的时候。
流量大/速度慢: 移动应用必然面对流量问题,我们至此为止都会看到月末时候的流量效应,就知道这个的重要性。况且对于小公司来说,更痛的可能还是带宽,CDN的费用问题。
弱网络兼容差: 用户面向的网络情况其实是时好时坏的,但是用户期待业务能执行成功,哪怕多耗费一点时间。
待机时间短/手机发烫: 自IPHONE开始,每个手机都需要“吊盐水”(使用移动电源)。如果他发现你在耗电排行榜TOP1, 却一直在后台毫无建树,相信用户会好不犹豫地删掉。
业务专项问题: 不同的产品有不同的业务专项问题,单独说出来是因为前面4个是通用的,请大家不要限制自己的思维。根据业务特质还有一些专项的指标会产生,例如地图应用定位的准确性,广告能力推送的准确性,音乐软件播放的音质,图片应用图片的质量。
下面针对这些问题,我们来看下我们有什么工具可以帮助到我们。没有像BAT这样的资源投入,但是问题还要解决。下面小V给大家推荐一些跟我们内部的建设思路近似的外部开源工具来帮助大家解决问题。(PS: 我只推荐我认为落地成本低产出最高的工具给大家,所以有些工具我不是不知道,而是投入的问题。并且下面我不再说专项指标,我会说是痛点,因为专项指标肯定不只有这些。下面的内容我尽量客观,但是不排除有一些主观判断,毕竟我没有每个都深入使用。)
Android
|
痛点 |
工具名 |
推荐原因 |
工具类别 |
落地优先级 |
落地成本 |
|
卡顿 |
Chrome for android开源性能测试工具(surface_stats.py) |
里面已经涵盖了FPS和janky采集的方法,用python写的命令行,简单直接地跟自动化测试结合。 |
发现 |
P0 |
低 |
|
卡上报(AnimationPerfMon.java) |
在空间落地卡上报,跟处理crash一样,通过堆栈快速定位解决问题, 补充ANR的缺失 |
发现+定位 |
P0 |
中 |
|
|
听云 / OneAPM |
基于UIThread/主线程的监控,都有不错的卡顿的发现能力。但是因为没有获取堆栈,而只有简单的方法名和activity,所以对于复杂的软件定位稍微困难。 |
发现+定位(弱) |
P1 |
低 |
|
|
Fresco |
通过内存缓存的优化达到流畅的图片及列表展示性能 |
解决 |
P1 |
低 |
|
|
Realm |
通过更优秀的I/O性能,降低APP对持久化数据读写的损耗,从而提升交互性能。可替代sqlite。 |
解决 |
P1 |
中 |
|
|
闪退 |
LeakCanary |
高效率发现大部分内存泄漏导致的OOM。 |
发现+定位 |
P0 |
低 |
|
Bugly /听云/OneAPM/Testin |
CRASH监控的能力大同小异,都能对数据上报的统计分析,清晰现网情况,用户痛点。但我会推荐腾讯的BUGLY, 因为ANR, CRASH都能提供比较足够的信息定位问题,另外,因为是腾讯的。 |
发现+定位+反馈上报 |
P0 |
低 |
|
|
Testin |
兼容性/稳定性测试利器,关键是机器的量够! |
发现+定位 |
P0 |
低 |
|
|
待机时间短 |
Chkbugreport |
从用户手机中提取BUGREPORT。通过这个工具是可以分析简单的耗电问题,如sensor或摄像头没有关闭,wakelock的问题。 |
发现+定位 |
P0 |
中 |
IOS
|
痛点指标 |
工具名 |
推荐原因 |
工具类别 |
落地优先级 |
落地成本 |
|
卡顿 |
FastImage |
通过节省decode的耗时等方法,提升图片及图片列表的展示性能 |
解决 |
P1 |
低 |
|
Realm |
通过更优秀的I/O性能,降低APP对持久化数据读写的损耗,从而提升交互性能。可替代coredata,userdefault,sqlite。 |
解决 |
P1 |
中 |
|
|
MGWatchdog |
实现类似ANR的机制,主要是要跟上报结合 |
发现+定位 |
P0 |
低 |
|
|
闪退 |
Infer |
解决因内存泄漏导致的内存耗尽导致的闪退。能扫描简单的循环引用导致的内存泄漏。 |
发现+定位 |
P0 |
低 |
|
Bugly /听云/OneAPM/Testin |
CRASH监控的能力大同小异,都能对数据上报的统计分析,清晰现网情况,用户痛点。但我会推荐腾讯的BUGLY, 因为ANR, CRASH都能提供比较足够的信息定位问题,另外,因为是腾讯的。 |
发现+定位+反馈上报 |
P0 |
低 |
|
|
待机时间短 |
iOSDiagnostics |
可以获取一些耗电的模块的信息,如果可以融合到数据上报中的话就更好了。 |
发现+定位 |
P0 |
中 |
通用
|
痛点指标 |
工具名 |
推荐原因 |
工具类别 |
落地优先级 |
落地成本 |
|
流量大/速度慢 |
BPG (android,类似webp) BPG (ios) |
BPG是H265帧内压缩做图片压缩,webp是利用VP8帧内压缩做图片压缩。图片压缩对于图片应用来说,除了能提升用户下载显示图片的速度,还能为企业节约带宽成本。 |
解决 |
P1 |
中 |
|
Pngquant |
利用PNG8压缩PNG图片,颜色单一的图片,效果会非常明显。 |
解决 |
P0 |
低 |
|
|
Wireshark |
实用的流量分析工具,包括export http object, I/O graph等等 |
发现+定位 |
P1 |
中 |
|
|
Emmagee |
Android的性能测试组件,里面涵盖很多性能数据获取的方法,可参考使用。 |
发现 |
P1 |
低 |
|
|
HAR + PageSpeed |
利用tcpdump在手机上获取的PCAP, 利用HAR转换PCAP,然后给pagespeed组件分析。 |
定位 |
P1 |
低 |
|
|
弱网兼容性差(ios通用) |
ATC |
Facebook弱网络模拟工具。好处是模拟丢包,抖动的时候比较稳定,而且还有HTTP API可以调用, 方便和自动化配合。 |
发现 |
P0 |
中 |
|
SPDY / QUIC |
特别是QUIC, 就是为了网络抖动而设计的。 |
解决 |
P2 |
中 |
|
|
OKHTTP |
推荐的HTTP组件。性能好,弱网兼容也不错。 |
解决 |
P1 |
低 |
结局篇
跟很多不小不大的互联网公司都交流过,测试的人力投入是非常有限的。当然更不可能有成建制的专项测试团队。所以正如前面提及的,找业务的痛点很重要,不求大而全。既然是痛点,就容易获得至上而下的支持,如果没有支持,就给信息给数据来说服,然后定底线定目标让事情持续有效。手Q的安装包就是个典型的案例,看到安装包一个版本就大10M,其实没有感觉到任何的痛和担心,我们用数据说话,多少用户用3G下载,各个安装包大小的下载失败率是多少,最终让老大重视了起来,并且确立了安装包增量监控的工具和流程。另外很重要的是信任关系,而信任关系不可能一蹴而就,需要有产品痛点,沉淀正面和反面案例,老大重视,自身技术过硬,并且持续相互教育,之后的事情就会更加一帆风顺了。最后,总的来说,少点埋怨,调整心态,数据说话,坚持底线。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

