深入理解Spark Streaming执行模型
正如市面上存在众多可用的流处理引擎,人们经常询问我们Spark Streaming有何独特的优势?那么首先要说的就是Apache Spark在批处理以及流处理上提供了原生支持。这与别的系统不同之处在于其他系统的处理引擎要么只专注于流处理,要么只负责批处理且仅提供需要外部实现的流处理API接口而已。Spark 凭借其执行引擎以及统一的编程模型可实现批处理与流处理,这就是与传统流处理系统相比Spark Streaming所具备独一无二的优势。尤其特别体现在以下四个重要部分:
- 能在故障报错与straggler的情况下迅速恢复状态;
- 更好的负载均衡与资源使用;
- 静态数据集与流数据的整合和可交互查询;
- 内置丰富高级算法处理库(SQL、机器学习、图处理)。
本文,我们将描述Spark Streaming的架构并解释如何去提供上述优势。紧接着我们还会讨论一些目前正在进行令大家感兴趣的相关后续工作。
流处理架构-过去与现在
当前分布式流处理管道执行方式如下所述:
- 接收来自数据源的流数据(比如时日志、系统遥测数据、物联网设备数据等等),处理成为数据摄取系统,比如Apache Kafka、Amazon Kinesis等等。
- 在集群上并行处理数据。这也是设计流处理引擎的关键所在,我们将在下文中做出更细节性的讨论。
- 输出结果存放至下游系统(例如HBase、Cassandra, Kafka等等)。
为了处理这些数据,大部分传统的流处理系统被设计为连续算子 模型,其工作方式如下:
- 有一系列的工作节点,每组节点运行一至多个连续算子;
- 对于流数据,每个连续算子一次处理一条记录,并且将记录传输给管道中别的算子;
- 源算子从摄入系统接收数据,接着沉算子输出到下游系统。
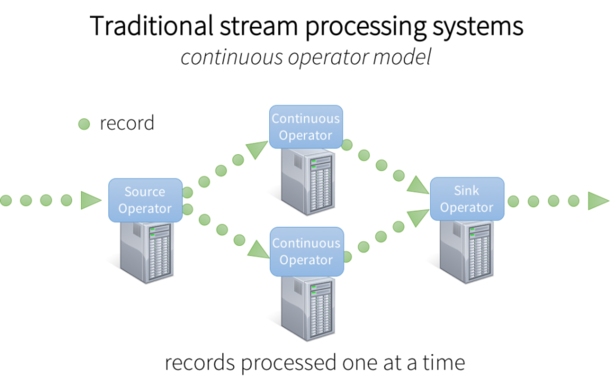
图1:传统流处理系统架构
连续算子是一种较为简单、自然的模型。然而,随着如今大数据时代下,数据规模的不断扩大以及越来越复杂的实时分析,这个传统的架构也面临着严峻的挑战。因此,我们设计Spark Streaming就是为了解决如下几点需求:
- 故障迅速恢复–数据越庞大,出现节点故障与节点运行变慢(例如straggler)情况的概率也越来越高。因此,系统要是能够实时给出结果,就必须能够自动修复故障。可惜在传统流处理系统中,在这些工作节点静态分配的连续算子要迅速完成这项工作仍然是个挑战;
- 负载均衡–在连续算子系统中工作节点间不平衡分配加载会造成部分节点性能的bottleneck(运行瓶颈)。这些问题更常见于大规模数据与动态变化的工作量面前。为了解决这个问题,那么要求系统必须能够根据工作量动态调整节点间的资源分配;
- 统一的流处理与批处理以及交互工作–在许多用例中,与流数据的交互是很有必要的(毕竟所有流系统都将这置于内存中)或者与静态数据集结合(例如pre-computed model)。这些都很难在连续算子系统中实现,当系统动态地添加新算子时,并没有为其设计临时查询功能,这样大大的削弱了用户与系统的交互能力。因此我们需要一个引擎能够集成批处理、流处理与交互查询;
- 高级分析(例如机器学习、SQL查询等等)–一些更复杂的工作需要不断学习和更新数据模型,或者利用SQL查询流数据中最新的特征信息。因此,这些分析任务中需要有一个共同的集成抽象组件,让开发人员更容易地去完成他们的工作。
为了解决这些要求,Spark Streaming使用了一个新的结构,我们称之为 discretized streams (离散化的流数据处理),它可以直接使用Spark引擎中丰富的库并且拥有优秀的故障容错机制。
Spark Streaming架构:离散化的流数据处理
对于传统流处理中一次处理一条记录的方式而言,Spark Streaming取而代之的是将流数据离散化处理,使之能够进行秒级以下的微型批处理。同时Spark Streaming的Receiver并行接收数据,将数据缓存至Spark工作节点的内存中。经过延迟优化后Spark引擎对短任务(几十毫秒)能够进行批处理并且可将结果输出至别的系统中。值得注意的是与传统连续算子模型不同,其中传统模型是静态分配给一个节点进行计算,而Spark task可基于数据的来源以及可用资源情况动态分配给工作节点。这能够更好的完成我们在接下来所要描述的两个特性:负载均衡与快速故障恢复。
除此之外,每批数据我们都称之为弹性分布式数据集(RDD),这是Spark中容错数据集的一个基本抽象。正是如此,这些流数据才能处理Spark的任意指令与库。
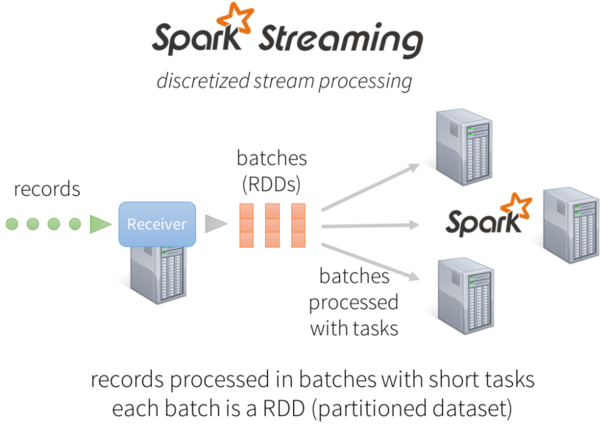
图2:Spark Streaming架构
离散化流数据处理的优点
我们来看看这个架构如何通过Spark Streaming来完成我们之前设立的目标。
动态负载均衡
Spark系统将数据划分为小批量,允许对资源进行细粒度分配。例如,考虑当输入数据流需要由一个键值来分区处理。在这种简单的情况下,别的系统里的传统静态分配task给节点方式中,如果其中一个分区计算比别的更密集,那么该节点处理将会遇到性能瓶颈,同时将会减缓管道处理。而在Spark Streaming中,作业任务将会动态地平衡分配给各个节点,一些节点会处理数量较少且耗时较长task,别的节点将会处理数量更多且耗时更短的task。
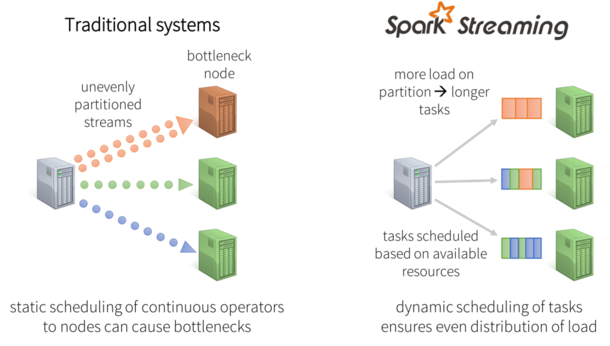
图3:动态负载均衡
快速故障恢复机制
在节点故障的案例中,传统系统会在别的节点上重启失败的连续算子。为了重新计算丢失的信息,还不得不重新运行一遍先前数据流处理过程。值得注意的是,此过程只有一个节点在处理重新计算,而且管道无法继续进行工作,除非新的节点信息已经恢复到故障前的状态。在Spark中,计算将被拆分成多个小的task,保证能在任何地方运行而又不影响合并后结果正确性。因此,失败的task可以同时重新在集群节点上并行处理,从而均匀的分布在所有重新计算情况下的众多节点中,这样相比于传统方法能够更快地从故障中恢复过来。
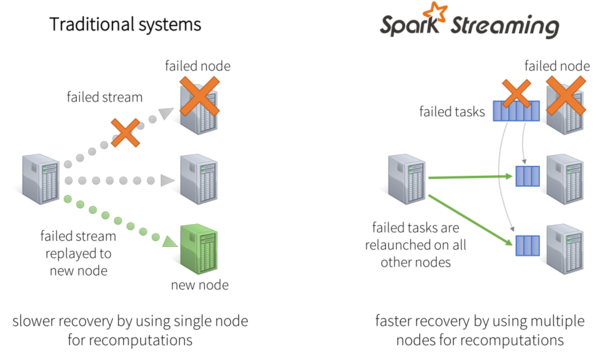
图4:快速故障恢复原理
批处理、流处理与交互式分析的一体化
离散数据流(DStream)作为Spark Streaming中一个关键的程序抽象。在其内部,DStream是通过一组时间序列上连续的RDD来表示的,每一个RDD都包含了特定时间间隔内的数据流。这种常用表示允许批处理和流处理进行无缝交互操作。从而用户可以对每一批流数据进行Spark相关操作。例如:利用DStream与预先创建的数据集相连接。
// Create data set from Hadoop file val dataset = sparkContext.hadoopFile(“file”) // Join each batch in stream with the dataset kafkaDStream.transform { batchRDD => batchRDD.join(dataset).filter(...) }
正如流数据中每一批都储存于Spark节点中的内存里,我们便能根据所需进行交互查询。例如,你可以通过Spark SQL JDBC server,查询所有stream的状态,该内容我们在下节中也会展示。正因为Spark对这些工作进行一个共有的抽象,所以这种将批处理、流处理与交互式工作结合在一起的情况,在Spark中是非常容易实现的,而在那些没有共同抽象的系统中却很难。
高级分析-机器学习、SQL查询
因为Spark具有互操作性,因此延伸出丰富的库供用户使用,例如:MLlib(机器学习)、SQL、DataFrames和Graphx。下面我们来一起探索一些用例:
- Streaming + SQL and DataFrames
DStream内部维护的RDD序列可以被转换成DataFrame(Spark SQL的编程接口),进而可通过SQL语句进行查询操作。例如:使用Spark SQL的 JDBC server ,外部程序可以通过SQL查询stream的状态。
val hiveContext = new HiveContext(sparkContext) ... wordCountsDStream.foreachRDD { rdd => // Convert RDD to DataFrame and register it as a SQL table val wordCountsDataFrame = rdd.toDF("word”, “count") wordCountsDataFrame.registerTempTable("word_counts") } ... // Start the JDBC server HiveThriftServer2.startWithContext(hiveContext)
你可以通过JDBC server使用Spark附带的 beeline client或者tableau工具交互查询持续更新的“word_counts”表。
1: jdbc:hive2://localhost:10000> show tables; +--------------+--------------+ | tableName | isTemporary | +--------------+--------------+ | word_counts | true | +--------------+--------------+ 1 row selected (0.102 seconds) 1: jdbc:hive2://localhost:10000> select * from word_counts; +-----------+--------+ | word | count | +-----------+--------+ | 2015 | 264 | | PDT | 264 | | 21:45:41 | 27 |
- Streaming + MLlib
机器学习模型可通过MLlib进行离线生成,能应用于流数据中。例如,在下面的代码用静态数据形成一个KMeans聚类模型,然后使用模型对Kafka数据流进行分类。
// Learn model offline val model = KMeans.train(dataset, ...) // Apply model online on stream val kafkaStream = KafkaUtils.createDStream(...) kafkaStream.map { event => model.predict(featurize(event)) }
我们在Spark Summit 2014 Databricks demo上证明了这种”离线学习在线预测”的方法。自那以后,我们也在MLlib中增加关于流的机器学习算法,这样就能持续形成一些标记数据流。其他的Spark 扩展库也同样能在Spark Streaming上被轻易调用。
性能分析
鉴于Spark Streaming独一无二的设计,那么它运行的速度有多快呢?实际上Spark Streaming的能力体现在批量处理数据以及利用Spark 引擎生成与别的流系统比相当或者 更高的吞吐量 。在延迟方面,Spark Streaming可以实现低至几百毫秒的延迟。开发者有时会问微批处理是否有较多的延迟。在实践中,批处理延迟只是端到端管道延迟的一小部分。无论是在Spark系统还是连续算子系统下,许多应用程序计算结果是根据一个滑动的窗口里所获得的数据流计算得到的,这个窗口的更新也是定时的(例如窗口间隔设为20秒,滑动间隔设为2秒,表示每隔2秒计算更新一次窗口前20秒的信息)。需要管道收集来自多个来源的记录并且等待一个短的时间内处理延迟或无序数据。最后,自动触发算法往往等待一段时间才触发。因此,相比于端到端的延迟,批处理延迟很少会增加很多的费用,因为批处理延迟往往很小。此外,从DStream吞吐量增益上来看一般意味着我们可以用更少的机器去处理同样的工作量,这便是性能上所带来的提升。
Spark Streaming的未来方向
Spark Streaming是Spark中最常用的组件之一,将会有越来越多的有流处理需求的用户踏上Spark的使用之路。一些我们团队正在研究的最高优先级的项目将会在下文中被讨论到。你可以在Spark接来下几个版本中期待这些特性的出现:
- Backpressure–在流作业中可能经常遇到爆发的数据量(例如:在奥斯卡颁奖期间激增的微博量),因此系统必须能够完美的处理好它们。在Spark 1.5版本中,Spark将会增加更好的Backpressure机制,让Spark Streming能动态地控制这种爆发的 摄入率。此功能是我们Databricks与Typesafe的工程师们共同完成的;
- Dynamic scaling –单单控制固定的数据读取ingestion rate不足以去处理更长时间范围的数据变化。(例如:相比于夜间,白天存在持续较高的发微博率)。基于这个处理要求 ,这些变化可以被动态地缩放集群上资源。在Spark Streaming架构中,这是很容易去实现的,因为计算已经被分成一系列小的task,如果集群模式(例如YARN, Mesos, Amazon EC2等等 )需要更多的节点去进行计算,那么它们能动态地分配到一个更大的集群环境。为此我们将增加支持自动化的Dynamic scaling;
- 事件时间和无序数据–实践中,用户有时会记录下无序数据信息,Spark Streaming允许用户通过自定义时间提取函数来支持事件时间排序;
- UI 界面增强–最后,我们希望使开发人员能够轻松调试他们的Streaming applications。基于这个目的,在Spark 1.4中,我们增加 新的可视化Spark Streaming UI ,让开发人员能密切监视他们应用程序的性能。在Spark 1.5中,我们通过展示更多的 输入信息(例如Kafka消息偏移量) 进一步提高了这项功能。
要想了解更多Spark Streaming执行原理和容错模型等相关内容,敬请阅读 official programming guide ,或者 Spark Streaming research paper 。
原文链接: Diving into Spark Streaming’s Execution Model ( 译者/丘志鹏 审校/Wendy 责编/仲浩)
译者简介: 邱志鹏,关注大数据、机器学习。
正文到此结束
热门推荐









相关文章





Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

