ML Pipelines:Spark 1.2中一个用于MLlib的High-Level API
在每次版本更新中,除下新算法和性能升级,Databricks在MLlib的易用性上同样投入了大量精力。类似Spark Core,MLlib提供了3个编程语言的API:Python、Java和Scala。除此之外,MLlib同样提供了代码示例,以方便不同背景用户的学习和使用。在Spark 1.2中,通过与AMPLab(UC Berkeley)合作,一个 pipeline API被添加到MLlib,再次简化了MLlib的建立工作,并添加了针对ML pipelines的调优机制。
实际应用中,一个ML pipeline往往包括一系列的阶段,比如数据预处理、特征提取、模型拟合及可视化。举个例子,文本分类可能就会包含文本分割与清洗、特征提取,并通过交叉验证训练一个分类模型。虽然当下每个步骤都有许多库可以使用,但是将每个步骤连接起来却并不是件容易的事情,特别是在大规模场景下。当下,大部分的库都不支持分布式计算,或者他们并不支持一个原生的pipeline建立和优化。不幸的是,这个问题经常被学术界所忽视,而在工业界却又不得不重点讨论。
本篇博文将简述Databricks和AMPLab在ML pipeline(MLlib)所做的工作,其中有些设计由 scikit-learn项目 和一些前期 MLI工作 启发而来。
Dataset Abstraction
在新的pipeline设计时,数据集通常由Spark SQL的SchemaRDD以及ML pipeline的一系列数据集转换表现。每个转换都会摄入一个输入数据集,并输出一个已转换数据集,同时输出数据集将成为下一个步骤的输入数据集。之所以使用Spark SQL,主要考虑到以下几个因素:数据导入/输出、灵活的列类型和操作,以及执行计划优化。
数据的输入和输出是一个ML pipeline的起点和终点。MLlib当下已为数种类型提供了实用的输入和输出工具,其中包括用于分类和回归的LabeledPoint、用于协同过滤的Rating等。然而真实的数据集可能会包含多种类型,比如用户/物品 ID、时间戳,亦或是原始记录,而当下的工具并没有很好地支持所有这些类型。同时,它们还使用了从其他ML库中继承的无效率文本存储格式。
通常主流的ML pipeline都会包含特征转换阶段,你可以把特征转换看成在现有列上加上一个新列。举个例子,比如:文本分词将文档拆成大量词,而tf-idf则将这些词转换为一个特征向量。在这个过程中,标签会被加工用于模型拟合。同时,在实际过程中,更复杂的特征转换也经常会出现。因此,数据集需要支撑不同类型的列,包括密集/稀疏向量,以及为现有列建立新列的操作。

在上面这个例子中,id、text以及words在转换中都会被转入。在模型拟合中,它们是不需要的,但是在预测和模型校验时它们又会被用到。如果预测数据集只包含predicted labels,那么它们不会提供太多的信息。如果我们希望检验预测结果,比如检验false positives,那么结合predicted labels 、原始输入文本及tokenized words则是非常有必要的。这样一来,如果底层执行引擎经过优化,并且只加载所需列将是很必要的。
幸运的是,Spark SQL已经提供了大多数所期望的功能,机构不需要再重新开始。Spark支持从Parque读取SchemaRDDs,并支持将SchemaRDDs写入对应的Parque。Parque是一个非常有效的列存储格式,可以在RDDs和SchemaRDDs之间自由转换,它同时还支持Hive和Avro这样的外部数据源。使用Spark SQL,建立(说声明可能更为准确)新列将非常便捷和友好。SchemaRDD实体化使用了lazy模式,Spark SQL可以基于列的需求来优化执行计划,可以较好的满足用户需求。SchemaRDD支持标准的数据类型,为了让其可以更好地支持ML,技术团队为其添加了对向量类型的支持(用户定义类型),同时支持密集和稀疏特征向量。
下面是一段Scala代码,它实现了ML数据集导入/输出,以及一些简单的功能。在Spark知识库“examples/”目录下,你发现一些更加复杂的数据集示例(使用Scala和Python)。在这里,我们推荐用户阅读 Spark SQL’s user guide 以查看更多SchemaRDD详情,以及它所支撑的操作。
val sqlContext = SQLContext(sc) import sqlContext._ // implicit conversions // Load a LIBSVM file into an RDD[LabeledPoint]. val labeledPointRDD: RDD[LabeledPoint] = MLUtils.loadLibSVMFile("/path/to/libsvm") // Save it as a Parquet file with implicit conversion // from RDD[LabeledPoint] to SchemaRDD. labeledPointRDD.saveAsParquetFile("/path/to/parquet") // Load the parquet file back into a SchemaRDD. val dataset = parquetFile("/path/to/parquet") // Collect the feature vectors and print them. dataset.select('features).collect().foreach(println) Pipeline
新的Pipeline API位于名为“spark.ml”的包下。Pipeline由多个步骤组成, 这些步骤一般可分为两个类型: Transformer和Estimator。Transformer会摄入一个数据集,并输出一个新的数据集。比如,分词组件就是一个Transformer,它会将一个文本数据集转换成一个tokenized words数据集。Estimator首先必须满足输入数据集,并根据输入数据集产生一个模型。举个例子,逻辑归回就是一个Estimator,它会在一个拥有标签和特征的数据集上进行训练,并返回一个逻辑回归模型。
Pipeline建立起来比较简单:简单的声明它的步骤,配置参数,并将在一个pipeline object中进行封装。下面的代码演示了一个简单文本分类pipeline,由1个分词组件、1个哈希Term Frequency特征抽取组件,以及1个逻辑回归。
val tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words") val hashingTF = new HashingTF() .setNumFeatures(1000) .setInputCol(tokenizer.getOutputCol) .setOutputCol("features") val lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.01) val pipeline = new Pipeline() .setStages(Array(tokenizer, hashingTF, lr)) Pipeline的本身就是个Estimator,因此我们可以轻松的使用。
val model = pipeline.fit(trainingDataset)
拟合模型包括了分词组件、哈希TF特征抽取组件,以及拟合逻辑回归模型。下面的图表绘制了整个工作流,虚线部分只在pipeline fitting中发生。
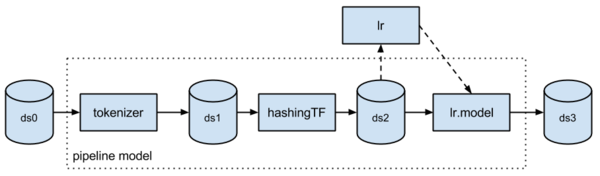
这个拟合Pipeline模型是个Transformer,可以被用于预测、模型验证和模型检验。
model.transform(testDataset) .select('text, 'label, 'prediction) .collect() .foreach(println) 在 ML算法上,有一个麻烦的事情就是它们有许多hyperparameters需要被调整。同时,这些hyperparameters与被MLlib优化的模型参数完全不同。当然,如果缺乏数据和算法上的专业知识,我们很难发现这些hyperparameters组合的最优组合。然而,即使有专业知识,随着pipeline和hyperparameters规模的增大,这个过程也将变得异常复杂。而在实践中,hyperparameters的调整却通常与最终结果戚戚相关。举个例子,在下面的pipeline中,我们有两个hyperparameters需要调优,我们分别赋予了3个不同的值。因此,最终可能会产生9个不同的组合,我们期望从中找到一个最优组合。
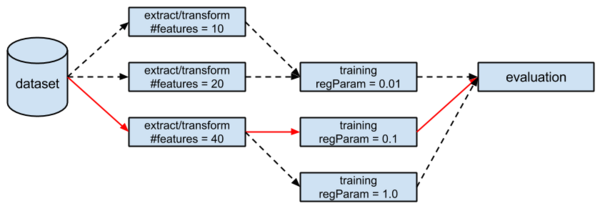
在这里,spark支持hyperparameter的交叉验证。交叉验证被作为一个元方法,通过用户指定参数组合让其适合底层Estimator。这里的Estimator可以是一个pipeline,它可以与 Evaluator组队并输出一个标量度量用于预测,比如精度。调优一个Pipeline是非常容易的:
// Build a parameter grid. val paramGrid = new ParamGridBuilder() .addGrid(hashingTF.numFeatures, Array(10, 20, 40)) .addGrid(lr.regParam, Array(0.01, 0.1, 1.0)) .build() // Set up cross-validation. val cv = new CrossValidator() .setNumFolds(3) .setEstimator(pipeline) .setEstimatorParamMaps(paramGrid) .setEvaluator(new BinaryClassificationEvaluator) // Fit a model with cross-validation. val cvModel = cv.fit(trainingDataset)
当然,在一个ML pipeline中,用户可以嵌入自己的transformers或者estimators是非常重要的(建立在用户已经实现了pipeline接口的情况下)。这个API让MLlib外部代码的使用和共享变得容易,我们建议用户去阅读 spark.ml user guide 以获得关于pipeline API的更多信息。
结语
本篇博文介绍了Spark 1.2中引入的ML pipeline API,以及这个API的运行原理——需要由 SPARK-3530、SPARK-3569、 SPARK-3572、SPARK-4192和SPARK-4209多个JIRAs完成。我们建议用户阅读JIRA页面上公布的设计文档以获得更多消息和设计选择。需要提及的是,Pipeline API的开发并没有全部完成。同时,在Pipeline API之外,还有一些相关的工作需要完成,比如:SPARK-5097,需要添加一个data frame APIs到SchemaRDD;SPARK-4586,需要一个ML pipeline Python API;SPARK-3702,用于学习算法和模型的类层次结构。
原文链接: ML Pipelines: A New High-Level API for MLlib (编译/仲浩 审校/钱曙光)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

