如何利用“图计算”实现大规模实时预测分析
一、何为“图计算”
相比起“Hadoop、Spark”这种流行的大数据处理平台,说起“图计算”,可能许多人还比较陌生。甚至有人会误把它当成专门进行“图像”处理的技术。 首先我们互联网上通常的定义来说明一下图计算:
“图计算”是以“图论”为基础的对现实世界的一种“图”结构的抽象表达,以及在这种数据结构上的计算模式。通常,在图计算中,基本的数据结构表达就是:
G = (V,E,D) V = vertex (顶点或者节点) E = edge (边) D = data (权重)。比如说:对于一个消费者的原始购买行为,有两类节点:用户和产品,边就是购买行为,权重是边上的一个数据结构,可以是购买次数和最后购买时间。对于许多我们面临的物理世界的数据问题,都可以利用图结构的来抽象表达:比如社交网络,网页链接关系,用户传播网络,用户网络点击、浏览和购买行为,甚至消费者评论内容,内容分类标签,产品分类标签等等。
图数据结构很好的表达了数据之间的关联性( dependencies between data ),关联性计算是大数据计算的核心——通过获得数据的关联性,可以从噪音很多的海量数据中抽取有用的信息。比如,通过为购物者之间的关系建模,就能很快找到口味相似的用户,并为之推荐商品;或者在社交网络中,通过传播关系发现意见领袖。但现有的并行计算框架像MapReduce还无法满足复杂的关联性计算。比如,笔者曾经发现有公司利用MapReduce进行社交用户推荐,对于5000万注册用户,50亿关系对,利用10台机器的集群,需要超过10个小时的计算。
最近有许多新型的基于图的计算平台和引擎出现,来应对这种复杂的需求。比如开始有专注与图结构化存储与查询的图数据库 Neo4j,infinitegraph等。Google为了应对图计算的需求,推出了新的“计算框架”——Pregel。CMU给出了一个开源的版本——GraphLab,虽然二者都是对于复杂机器学习计算的处理框架,用于迭代型(iteration)计算,但是二者的实现方法却采取了不同的路径——Pregel是基于大块的消息传递机制,GraphLab是基于内存共享机制。同样的,最近非常火的“Spark”也有支持图计算机器学习的模块——GraphX,可以实现复杂的图数据挖掘。
二、业务挑战
时趣 SocialTouch 是数据驱动的移动营销解决方案提供商。所涉及的客户数据源涵盖了自媒体行为,关系,内容。企业内部营销,销售,售后数据,以及其他第三方和广告投放数据。数据来源结构复杂。数据的应用类型也比较多样化,主要包括:消费者画像,交互式消费者洞察分析,潜在消费群体挖掘,个性化内容等等。因此,从业务出发面临许多现实的技术挑战:
1、大数据量:SocialTouch提供的是SaaS 模式的数据管理平台,那么对于不同的应用,可能会用到不同的算法策略。而一家客户的数据平均都在100T以上,同时还在持续增加。如何利用不同的算法策略在同样的数据结构之上进行计算,而不是为了使用不同的算法需要修改和迁移海量的数据。需要我们采取一致性的数据结构。
2、动态变化:营销的核心是研究“人”,而对人的描述的主要数据是行为数据。SocialTouch通常会根据客户的需求,持续采集消费者的行为数据。而用户行为往往是实时动态发生,因此需要数据与模型也能够实时更新。
3、实时性:对于数据分析人员来说,往往许多分析的维度不是事先预定的,需求总是不断在变化。能够进行交互式的数据的钻取,无疑有助于更好的发现营销“真相”。因此,对于大数据量的实时计算就成为了一个挑战。同时,基于消费者个体画像和当前的“上下文”触发的个性化营销也是移动营销的主流需求。因此,这就需要服务器端在毫秒级别内给出个性化的预测结果。目前针对复杂机器学习的“图计算”虽然可以支持“批处理”模式的迭代计算,比如著名的PageRank模型。但对于实时分析和预测,并不是最好的解决方法。
4、关联性:对于营销来说“预测性”分析不仅仅是发现营销的好坏,更重要的是发现为何好,以进行优化。比如“归因分析”和“相似人群”等预测性模型,都需要关联计算的支持。而且,这种关联性计算也对实时性有一定的要求。虽然一些图数据库可以支持图数据结构的读取访问,但对于大数据量的关联计算支持较差。
三、CrowdGraph——从业务出发的选择
为了应对以上业务需求。SocialTouch从构建大数据架构开始,就启动研发了专利技术——CrowdGraph,专业应对消费者行为数据处理的实时图计算引擎。并成功应用于SocialTouch BI,社会化聆听,数据管理平台等产品中。下图给出了CrowdGraph的逻辑架构:

整体架构从逻辑上划分为4层, 分别为应用服务层,计算查询层,索引管理层和索引层。应用服务层提供稳定高效的网络服务和相关的Query解析,查询计算层负责 查找、筛选、分组过滤、游走等算法。索引管理层主要负责索引段的管理和适配,保证索引的灵活使用。索引分为vertex和edge两种类型,vertex、edge的属性支持Scheme定义,索引建立支持采用hadoop离线完成。 整体上索引和算法是核心。
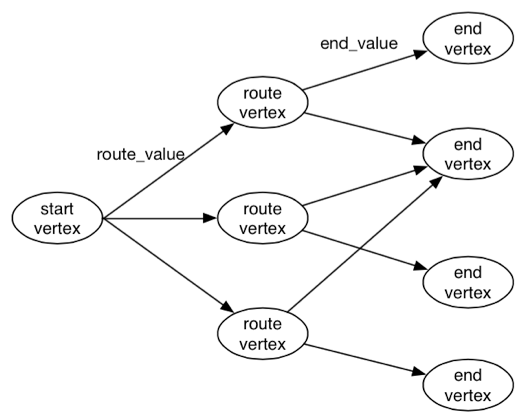
以微博用户的影响力标签计算为例子,只需要简单的三步:
第一步:用户以等边上概率游走到粉丝,根据粉丝属性值计算此步游走的权重。
第二步:粉丝以等边概率游走到标签,根据标签的属性值计算此步的权重。
第三步:对相同相同标签所在的路径的权值累加后,对候选标签进行排序、过滤。
在实践应用中,GrowdGraph主要用于存储各种对象(用户,信息(商品页面,广告页面)之间的互动关系,经过测试,它具有以下特点:
- 高性能与实时:由于本身就是专为挖掘关系设计的数据系统, CrowdGraph预先建立和存储了对象关系数据,同时考虑了块读取和内存加速,所以与关系型数据库相比,具有更高的查询性能和无法比拟的计算性能,比如计算超过百万潜在的消费者的属性分布,只需要秒级返回结果,是传统数据库查询的60—1200倍。
- 灵活性:与传统BI系统和数据仓库相比,由于CrowdGraph不必预先设计表格的结构,所以可以动态的插入任意关系类型,非常适合存储动态变化的信息(如人的行为)。
- 抽象性: CrowdGraph高度抽象了各种关系,不必定义结构,就可以可以很好的表达人的行为,属性,社会活动,广告点击,内容浏览和商品交易等各种抽象关系。
- 精准性:与其他开源的图数据库不同, CrowdGraph中间包括了相关算法框架层,可以直接支持实时聚类,归因分析,贝叶斯网络等模型。同时避免直接访问抽象的数据,可以提供面向业务逻辑的精准预测服务。
四、结束语
图是一种抽象人类行为的方法,就像一句谚语所说“知道的越多,未知的就更多。对人类的行为的分析不是一个简单的“分类”问题,而是一种概率预测和排序问题。图计算的应用才刚刚开始,随着大数据研究和应用的发展,我们相信更多的支持“图计算”的系统会被大量使用。如果你有兴趣参与其中,希望和我们一起探讨。
作者简介:王绪刚 时趣首席科学家,日本富山大学 工学博士。
(责编/夏梦竹)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

