你的基础设施是什么版本?
【编者的话】本文是永恒不变的基础设施系列的第一篇,主要是描述了应用程序版本管理以及如何设计状态可知的系统的概念性框架。
我一直认为每个人都应该知道应用程序版本管理的重要性,惊讶于当有人不这么认为。在一个罕见的场合,我就遇到了一些坚称不需要版本管理的人,我盯着他们并且内心咯噔了一下。幸运的是,我是心理健康的人,大多数专家同意版本管理是重要的,只是在方法上意见不一。 应用程序版本管理方案 的辩论就像讨论 tabs vs spaces 或者采用什么方法把厕纸卷起来一样。我花了数小时的时间来辩论 某种类型 的版本管理方法相对于 其他类型 的优点,我在这里要说的是,我不在乎版本管理的风格,我在乎的是什么还没有版本化。
尽管经过多年的集体痛苦尝试获得生产环境中运行的是什么样的代码的可知性(也称为到底是怎么回事),我们的行业还是仅仅处于把相同类型的可知性归咎于基础设施的初级阶段。试想一下,如果你知道软件构件的版本但 没有确定正在运行的底层平台是什么 ,你真的能确定你的应用程序是什么吗?就像将应用程序版本升级到3.x或到4.x,也许是因为你漏掉了某些需要知道的正在确切运行的软件关键部分信息(子版本)。第一个版本号让你朦朦胧胧地知道发生了什么,但就是这样,给我们带来了如下问题:
你能告诉我你的基础设施是什么版本?
能够回答这个问题至少跟能够回答应用程序版本一样重要。
如果你仍然不同意我的观点,也就是为什么你可能想知道你的应用程序基础设施的确切信息,请思考以下问题:
1、你是怎么考虑基础设施的?你的应用程序所运行的平台对你有什么样的意义?
2、当你报告了一个bug之后,你问的第一个问题是什么?
3、你如何知道运行时应用程序使用什么共享库?
4、运行应用程序的框架或服务的版本是什么?
5、操作系统是什么版本?上次打补丁是什么时候?
6、自从安装了之后,操作系统的配置有什么变化?但更好的是,设置时用了什么安装选项?
7、应用程序所连接的数据库的版本是什么?
8、保护您的应用程序所需要的防火墙规则是什么?
9、需要运行什么计划工作来发挥应用程序功能?是否可以从另一个系统中调用?
10、你是否出售(比喻或字面意思)盒装软件产品,以至于无法控制软件在哪里运行?在这种情况下,这篇文章可能不会非常有用,因为你运气太糟糕了,除非你可以在一个容器中运行它,如果你能做到,然后就继续阅读下去。
如果你的答案涉及SSH登录沙盒或检查维基百科,你应该继续阅读下去。
聚集于永恒不变的基础设施
在术语“永恒不变的基础设施”使用之前的二十年里, 软件配置管理 (SCM)是学术和专业人士的研究领域。这门学科非常宽泛,因为它聚集于可配置的软件系统状态的各个方面。然而,基础设施内部的状态变化是非常大的,所以为了公平起见,我们不能忽视SCM社区的努力而就一开始就讨论永恒不变的基础设施。此外,这门学科的创建带来了生产环境应用程序可知性的飞跃,因为它给软件部署带来了一些小小的自我意识,因而基础设施的状态也可以变化了。
我不能确切的找出谁创造了“永恒不变的基础设施”这个术语,但我从 Chad Fowler的2013年 归档没有找到参考,直到 2014年一月,这个术语的搜索才开始大量增长 。我觉得这个术语有一个很好的近似表达但最终按字面意思解释不是那么准确的描述。我不想说,完全不变的基础架构是不可能的,但也有可能底层硬件状态发生变化,所以我不认为在我一生中的任何时候会发生。你可以认为不变性是光谱的一端,一端有一个未知的可能变化的基础设施,在另一端有一个完全可知不变的基础设施。从这个意义上说,不变性可以与可知性可以划等号。因此,如果你不知道状态——你怎么可能声称与前一个状态相比没有变化呢?
所有的基础设施都会在一定程度上改变,否则不会有用。没有 状态变化 ,计算机将会咋样?如果没有输入,拿什么进行计算?鉴于目前软件系统复杂度的状态,实际上没有人能百分百地预测在任何给定的时间比如当一个Web服务调用时系统会运行什么指令?对于由应用程序执行的profile或者指令,当然可以有上百万的参数,但是一个经典的多线程操作系统每天结束的时候都会充满了无用的垃圾信息,我不相信任何一个非学术人员可以对于一个完整系统的实际指令有完整的认知图谱。在我们开始更深入地去查看宇宙射线对于各种系统状态的影响之前,很多事物都是相互作用的。这就是为什么 停机问题 是如此令人困惑。对于我们这个时代的经典系统,你甚至不能确定什么软件实际上正在运行,以及未知的应用什么时候将结束。就是说,我确信在一定的理论意义上我是有技术性错误的,但我相信我实际上是正确的。
现在,如果我们远离不变性的绝对定义,朝向更实用的不变性形式,这意味着什么呢?首先,这意味着更少地讨论计算机学术问题,而是更多地讨论有关创建人类可知系统的工艺技巧。因此,作为基础设施的一种类型,我们可以得出一个对于永恒不变的基础设施的可操作性的定义,既可以将未知状态的改变最小化的基础设施。
在 虚拟机 时代之前,技术上成熟的组织非常小心地标准化应用服务器集群的硬件和操作系统。这原先是一个手动的过程,现在借助于 磁盘镜像工具 或 网络启动技术 变得日益自动化。这些都是巨大的进步,让我们接近了一个更不可变的应用程序主机系统的定义,因为它们提供了关于运行应用程序的系统的初始状态的可预测性。
此时,构建机器的安装脚本基于专门的原语创建,没有标准化。每个公司都有自己的构建系统,随着时间的流逝,从同一个起点开始发展的不同系统会开始慢慢地发散,变得不那么可预测。它们可能有共同的模式,但没有一个明确的版本可控的机制定义基础设施和有争议的磁盘镜像异常。然而,我们也开始看到了更永恒不变的基础设施的先驱者,在用户登录和恢复系统到预定状态之间使用工具来重启系统。
虽然VMware成立于1998, 但直到2001后,我们才开始看到虚拟机在数据中心的广泛使用,这些技术一旦出现,运营效率开始了静悄悄的革命。而通过提升底层硬件的利用率提高性价比(从功耗和能量密度而言),虚拟机也改善了基础设施的可知性,这是通过允许将磁盘镜像的自由交换作为操作系统定义的通用特性来操作的。虚拟机镜像不仅可以提供一个已知的起点比如物理磁盘副本和网络引导配置,还提供了快照副本,让你可以恢复到已知的状态。突然地你可以有效地开发标准化的操作系统镜像从而可以在组织内分享。然而,虚拟机磁盘镜像的大小限制了在开发者之间解决方案的可重用性,这恰恰是运营方的收益之处。
后来,构建和配置虚拟机的工具开始成熟,我们开始看到了各种使用脚本或配置文件来配置虚拟机基础磁盘镜像的工具,诸如 Puppet 、 Chef 和 Vagrant 这样的工具都是按照这个原则工作的。通过对基础虚拟机存储标识符,还需要一些必需的构建步骤为应用程序安装虚拟机,应用程序是版本可控的,这样我们就离永恒不变的基础设施的目标更近了一步。然而,这个模式有一个问题,就是没有办法保证虚拟机赖以运行的基础磁盘镜像针对不同的虚拟机是一致的,除非采用相同的工具集来定义。这导致了在从内部集成的运行VMware的服务器切换到公有云上的生产环境服务器时运行安装脚本失败。由于缺乏可移植性,各个操作系统经常有小的配置差异,所以经常导致很多重大的棘手问题,但这些解决方案的净效益如此之好所以得到了广泛应用。
一个旧的解决方案重出江湖
与此同时,脚本驱动型的配置开始江河日下了,基于云的 PaaS 平台的市场份额日益增长。相对于脚本驱动配置和虚拟磁盘镜像,PaaS承诺可以简化可知的基础设施。你可以开发一个应用程序然后运行在别人的基础设施上。只要你的应用程序符合平台的局限性,你就不必担心底层的基础设施。你可以移动滑块来创建更多的程序运行副本,然后自动添加到负载均衡器。这是一个惊人的承诺——现在我们可以将基础设施外包了。对于简单的应用程序,这种模式过去可以很好的工作,现在仍然可以运转良好。这就是为什么很多创业公司都会在 Heroku 上部署它们的应用的原因所在,在简单的使用案例中,它可以节省你很多时间。然而,一旦你的应用程序开始需要更多的基础设施底层资源,这种模式就无法承受了。大多数PaaS供应商都提供了定制基础部署镜像的方法,但是通常都是缺少文档的,操作繁琐并且只是针对某个具体供应商的。
近年来,容器化作为IaaS和PaaS中间的解决方案获得了发展动力。有一个重要一课就是Docker作为容器的一种实现脱颖而出。 Docker 是由 一家PaaS供应商 DotCloud创造出来从而开启了容器革命。容器化技术已经 存在好多年了 ,从BSD Jails(2000年3月)到Solaris Zones(2004年2月)直到现在的LXC(2014年2月),我们看到了一个奇怪的降级特性集。Jails和Zones是更加成熟的技术,为什么LXC(也就是Docker)却有这么大的影响力呢?可以说是因为Docker是Linux原生的,或者你可以说这是因为Docker关注开发者体验的缘故。我想说的是,成功的关键不仅在于开发者体验,也在于带来了创建操作系统平台的可知性。
对于Docker,你可以绝对肯定底层镜像是不变的,同样的判断,对于虚拟机、Zones和Jails也成立。然而,关键的区别是对于基于不变的基础设施扩展而来的上层每一个变化,都非常容易版本化和易发现。你获得了一个按照Dockerfile格式社区标准化的文件,接着你可以追踪制作平台镜像的构建步骤。每一个构建步骤都有它自己的镜像并且可以和其他开发者共享,这使得另一个潮流可以进入软件开发生命周期(SDLC)。 现在针对运行应用程序的基础设施可以独立于应用程序版本化 ,有着它自己的SDLC和继承模型,并有平台镜像专家在应用范围之外来修改,所有的这些修改都是可知的,并且会被记录下来。

分离基础设施的SDLC和应用程序的SDLC现在非常容易
如果你不知道交付那容器有什么益处?
容器可以缩短基础设施内的不可知的可变的时间,但是它不能解决底层主机平台的可变性问题。我们只是对它的运行有信心,无论什么咒语我们也可以尽我们所能抵御来自于运行容器的主机的恶魔。然而,即使容器是朝着实现永恒不变的基础设施的目标是一个伟大的进步,它只是一个单一的计算单元(即机器),他们没有解决所有依赖系统的交互,比如通过网络或者其他IO通道与其他应用交互。换句话说,版本化容器没有解决一切除非你连接上它,但这是朝准确方向迈出的一步。
在某种程度上,其他系统(不是版本化的应用程序)都是可知的,我们的目标应该是引导它们走向一个一成不变的模式。这意味着我们需要对于系统的每一个模块以及连接这些模块的组件的所有版本有可知性。在这种模式中,你将可以洞察数据存储、网络设置和任何耦合服务的状态。如果你能得到一个连贯的版本标识符,那么你将能够构建一个完整的虚拟数据中心的版本标识符,这是纯粹将单个组件的版本组合之后的散列值。记录版本号并将它们关联到一个版本化的产品就是持续集成和持续交付系统的通常工作。
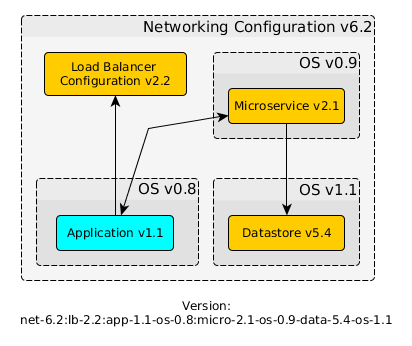
怎么样用版本表示虚拟数据中心可知状态的一个例子
然后,可以通过追踪构建系统的每一个版本号,并最终实现源代码管理,可以在应用程序中直接嵌入版本号,这样错误报告工具可以直接关联整个基础设施已部署的版本。
通过中央版本标识符,你会有一个中央权力机构,在一个抽象边界(虚拟数据中心)内提供每一个单独组件状态的可知性。通过上述的版本ID,如果我想知道Rest框架正在运行的版本和为微服务提供请求服务的端口是什么,办法非常简单,诸如解析版本ID:micro-2.1-os-0.9,然后在源代码管理系统中找到关联的版本。关键点在于你的主版本标识符可以被解析这样就可以找到产品中每个组件的准确版本,因为这些版本信息存储在源代码管理系统中。此外,它应该是可组合的,这样就可以作为另外一个组件版本号的一部分,例如上图中的版本号可以嵌入一个更大的软件系统中。
读者练习
正如我一开始提到的,我对没有版本化的担心甚于正在版本化的。本着这种精神,我已经为你的娱乐准备了一份问卷,然后检查你正在做的每一个练习。
我忘记了什么版本?
☐ 所有从源代码编译而来的并且部署到生产环境中的软件都存储于源代码管理系统中,你是否确定如此?
☐ 所有不从源代码编译而来的软件(第三方二进制包)都有版本标识符。
☐ 我们知道并且可以追踪组件依赖的所有的软件库的版本信息。
☐ 我们有系统设置可以检测收敛的依赖关系,无需这些软件就可以自动升级。
☐ 我们代理所有外部组件系统(比如Maven、Nuget、NPM、CPAN、gems等等),保证添新加库的版本可以被发现和取证分析。
☐ 我们从不在我们的基础设施上执行curl - s http://dodgysite.com/useful-utility.sh | sudo bash,对吧?我们知道下载一个未知的版本会宕掉整个数据中心。
☐ 我们应该明白在基础设施中什么被配置了,什么没有被配置,你确定是否如此?
☐ 我们的构建和编译环境、选项、链接库和优化标志都来源于版本标识符。
☐ 我们知道客户端通讯期待需要的所有API的版本。
☐ 我们知道服务器需要提供的所有的API的潜在版本。
☐ 我们的负载均衡、反向代理、应用交付控制、SSL终端设备或者任何网络基础设施的版本对于其他版本化的产品都是已知和可信的。
☐ 我们为数据存储维护一个清晰的版本schema,了解运行时的数据存储结构,并且可以关联到任何版本的访问器。
☐ 我们的所有防火墙规则都是文档友好和版本化的,这样的话没有人可以在我们应该知道在哪里的地方偷偷摸摸的进行改动。
☐ 我们所有的网络连接都是版本化的,了解什么组件在相互联系,什么组件没有,这样发生变化时可以追踪网络组件是如何耦合的。
☐ 我们知道所有重复性工作的设置,我们确信这些是正确的设置。
☐ 操作系统的每个组件都是可以被清晰鉴定的,版本也是可发现的。
☐ 操作系统的每个组件配置都是版本化的,并且绝对可以确定是从已知状态启动软件的。
☐ 所有的版本标识符都可以关联到源代码管理系统,或者这些标识符对于开发商是可以理解的。
☐ 所有的版本标识符都应该存储在对于开发者、运营和产品经理有用的地方,这样任何人都可以知道在生产、试运行或者测试环境中运行的版本是什么。
☐ 所有特定用途的硬件被记录在案,底层硬件系统可以在前后一致的状态中重建,不过这并不重要,因为我们可以使用容器或虚拟化技术。
☐ 如果我们使用容器或者虚拟化,底层的虚拟化或容器化框架设置应该是文档友好的并且可被引用的。
☐ 当构建操作系统镜像时,我们使用的框架应该是允许版本化的,并且可以将与部署相关的版本信息通过某种方式存储下来。
☐ 对于下载并安装在操作系统镜像上的二进制发行包需要检查其散列值。
☐ 我们需要允许进行产品调试分析和测试的系统设置,这样的话我们就不必违反版本化的核心原则(比如开发人员在生产环境中没有SSH终端来打开源代码来诊断问题)。这些系统可以是金丝雀部署工具(比如Distelli)、适合生产的分析工具(比如Dtrace)或者应用程序性能监控工具(比如New Relic)。
☐ 当我们的软件dump时,我们知道版本信息并且可以准确地在源代码或者二进制发行包内找出原因。
☐ 我们知道是谁在什么时候在哪里改了什么东西。
我想我在写上述这些列表的时候有一些职业回溯,因为它涉及到了一些痛苦的自我反省(请不要批判我的GitHub账号!)。
长久地注视那些你还没有检查的列表选项,它们是否重要?如果不将它们与版本化关联,会有什么风险?没有版本化会有什么益处?
一旦你有了一个良好的对于收集的版本的处理方式,在一个对于你的组织有用的地方存储版本标识符是很重要的。在Git里通过文本文件可以告知你什么将会被推送到试运行或者生产环境,这个文件非常有用,但更重要的是,有这样一个系统存在。
下一步
我已经针对如何尽可能的设计一个拥有可知状态的系统制定了概念性的框架,自然地,下一个问题就是:我们怎样构建它?设置需要多少工作?对于可知性和生产力如何权衡?是否可以使用已有的项目来设置?
在关于永恒不变的基础设施系列的第二部分,我讲会回答上述这些问题并且深入探讨你该做些什么使其工作在云端。
原文链接: What Version is Your Infrastructure?
(翻译:胡震)
================================================================================
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

