聊天机器人与自动问答技术
聊天机器人与自动问答技术
作者:mjs (360电商技术)
引言
最近半年,微软的聊天机器人小冰比较火,有些人对这方面的技术产生了兴趣,恰好之前做过自动问答方面的一些简单工作,这次写一篇应景之作,供 IT 技术男在坐马桶时打发一会时间。
聊天机器人属于自动问答 (Question Answering) 的一个方向,对它的研究很大一部分源自于图灵测试。 1995 年 Dr. Richard 开发设计 了聊天机器人 Alice ,并 于2000 年和 2001 年 获得了 AI 领域的 最高荣誉洛伯纳奖 。国内也有过一些类型产品,比如 2004 年曾登录 MSN 的小 i 机器人。
但无论是在学术界还是产业界,聊天机器人的方向都不受重视,究其原因,从学术的角度讲,核心技术是自动问答,那大家就直接研究自动问答好了;从产业的角度讲,聊天机器人的实用价值有限,除了尝鲜逗乐,谁会去跟一个机器没完没了的聊天呢。如果聊天机器人能回答有实用价值的问题,那就又回到了自动问答上:你只要回答用户的实际问题就可以了,完全可以不理会诸如“我帅吗”、“去你大爷”这样的问题。
那为什么已经消停近 10 年的聊天机器人又火了呢,我猜可能是手机用户多,尝鲜逗乐的人基数大,也可能和某个电商公司上市有关,万事万物都有联系,谁知道呢。
说完了历史,我们开始面对枯燥的技术问题。自动问答是指用户以自然语言提问的形式提出信息查询需求,系统依据对问题的分析,从各种数据资源中自动找出准确的答案。从系统功能上讲,自动问答分为开放域自动问答和限定域自动问答。开放域是指不限定问题领域,用户随意提问,系统从海量数据中寻找答案;限定域是指系统事先声明,只能回答某一个领域的问题,其他领域问题无法回答。
开放域和限定域,两者的难度差别,没做过的人也能想象出来。学术界对开放域自动问答研究的比较多,因为他们的输出成果是发论文,所以专选困难的、别人没做出来的事情做。产业界需要解决实际问题,并且要计算回报是否大于付出的成本,所以他们通常面向自己的领域,做限定域自动问答。目前市场上已经有很多限定域对话系统、基于 FAQ 的问答系统等实际应用。
这里主要从学术角度讲一下开放域自动问答的技术实现。
技术方案
问答系统一般的体系结构
总体来看,一个典型的问答系统一般包含有:问题分析,文档和句段( passage )检索,答案抽取和生成。在该体系结构下,系统接受用户的问题并给出反应的一般过程如下图:
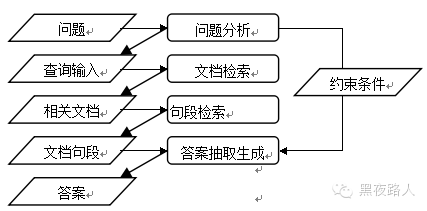
图 1 开放域问答系统一般的体系结构
通过对用户问题的分析,明确其预期的答案类型以及答案与问题中其它词之间的约束关系,为答案抽取提供约束条件;相关文档检索从海量文档集中检索到包含答案的文档;通过文档句段检索,从相关文档中提取出包含答案的文档块,以进一步减少答案抽取所需处理的内容;而利用问题分析阶段产生的各种约束条件,答案抽取和生成模块从文档句段中提取出答案。
问题分析
问题的分类
对问题的分类有不同的维度,可以单纯根据问题类型分。我之前做过一个工作,对 141670 个真实问题进行分析,根据问句的形式和提问的内容将问句分为 10 大类,类型和比列如表 1 所示。
表 1 问句类型和比例
| 类型 | 实体 ( Entity ) | 方式 ( How ) | 判断 ( Judge ) | 原因 ( Why ) | 数字 ( Number ) |
| 比例 | 32.10% | 26.0% | 13.72% | 7.12% | 6.45% |
| 类型 | 人物 ( Human ) | 地点 ( Location ) | 时间 ( Time ) | 定义 ( Definition ) | 其他 ( Other ) |
| 比例 | 5.63% | 2.40% | 2.22% | 1.32% | 2.87% |
从答案类型的角度分,可以把问题分为事实型问题、列举型问题、定义型问题和交互型问题,限于篇幅,这里不对每种问题类型举例。
问题分类可看作是特殊的文本分类。相对于文本,问句一般比较简短,可采用的特征较少,但更容易进行深层的语法和语义分析。现有问题分类的方法主要有两基于规则的方法和基于统计机器学习的方法,这里不做展开介绍。
预期答案与问句词之间的关系获取
不同的答案提取算法,需要不同的答案上下文约束条件。在预期答案与问句关键词的关系方面,现有的表示方法有:
( 1 )简单共现关系。如对预期答案的约束条件就是答案与问句关键词之间的共现关系,以及预期答案所属的命名实体类型。
( 2 ) 句法依存关系。把问句表示成预期答案与问句关键词及这些词汇之间的句法依存关系。
( 3 )浅层语义关系。对问句进行浅层语义分析,将问题表示成核心词与语义角色的集合。
相关文档和文档句段检索
事实型和列举型问题的相关文档检索
为了减少答案抽取所需处理的数据量,需要从海量的文档集中检索出可能包含答案的相关文档。对于问答的检索,需要解决的问题有:检索模型的选择,需要检出的文档数量、查询输入的构造与反馈技术的应用。
检索模型主要有向量空间模型、布尔模型和统计语言模型。 Moldovan 与 Harabagiu 的研究表明,布尔模型更适合于问答系统 [1,2] ,主要是布尔模型更容易构造反馈结构。若检索结果太多,可以增加查询关键词以加强查询条件;若检索结果太少而找不到答案,则可以减少查询关键词。
检出的文档数量上,应该返回尽量多的文档,以确保包含答案的文档在检索结果中。但另一方面,返回太多的检索结果,会导致后续的答案抽取性能下降。原因是返回的结果越多,其中包含的不相关文档也就越多,这反而影响了答案的抽取。
根据问句构造检索的查询输入有很多方法。最简单的是将问句中非停用词作为查询关键词,缺点是,有些不包含关键词的文档却包含答案。因此,需要进行关键词扩展等处理。扩展的方法主要有:
( 1 ) 词干提取 (stemming) 。这个主要适用于英语;
( 2 )伪相关反馈。这个适合数据少的情况,对问答容易产生噪音干扰;
( 3 ) 同义词和语义相关词扩展方法。这是最有效,也是使用最多的方法。主要包括基于特定知识库的扩展、基于检索结果的扩展和基于统计机器学习方法的扩展。
事实型和列举型问题的相关文档句段检索
在检索到的相关文档中,进一步把可能包含答案的文档句段提取出来,以减少答案抽取所需处理的内容。这也是目前很多问答系统采用的方法。
( 1 )句段的切分
进行文档句段检索时,首要的问题是如何将一个文档切成多个句段。有些将相关文档句段定义为一个句子,有些定义为 n 个句子,还有些定义为一个连续的词序列,序列边界可以在一个句子的中间,有些把一个子话题作为一个句段。
( 2 )句段检索方法
最简单的是计算句段和问题之间匹配的词个数,将该数目作为句段的排序权值,还有些是计算问题和句段之间的余弦相似度。和相关文档的检索相类似,很多包含答案的句段,并不一定包含问句关键词,这需要用 WordNet 等同义词资源来对词进行扩展。
( 3 )句段检索的文档范围
参与 TREC 评测的问答系统中,大部分都是先从海量数据集中检索出可能包含答案的文档,然后在这少量的文档中进行句段检索。但有一些系统,是直接在整个原始数据集中进行相关句段检索。
定义型问题的相关文档检索
定义型问题的特点是问题中包含很少的限定信息,因而使查询输入构造更困难。如问题 “ What is the vagus nerve ? ” ,其中的 “ What ” 、 “ is ” 、 “ the ” 三个词都属于检索的停用词,可用的查询关键词只有待定义的目标词 “ vagus nerve ” 。但如果只用定义目标作为查询关键词,则检索时会返回太多的文档,使真正包含定义的文档淹没在检索结果中,最终影响了定义信息的抽取。
因此,定义型问题的文档检索需要有查询扩展。显然,这种扩展必须要利用现有的各种知识资源,如舍费尔德大学的 Gaizauskas 等 [3] 利用了 WordNet 、大英百科全书、 Web 来获取扩展词。扩展时,从 WordNet 中查找对定义目标词的注释, 从百科全书中查找包含定义目标词的句子,从 Web 检索包含满足模式的且包含定义目标词的句子,然后从这些注释或者句子中选择关键词作为对定义目标词的扩展。
答案的抽取和生成
在检索出可能包含答案的文档句段之后,需要将满足约束条件的候选答案抽取出来,并对候选答案进行排序或者去重等处理,生成最终的答案返回给用户。
事实型与列举型问题的答案抽取排序
对于简单事实型问题,一般都是采用某个答案抽取方法,从排好序的相关文档句段中抽取出多个候选答案,然后对这些候选答案进行排序,排名第一的被作为最终答案返回。
对于列举型问题,许多研究都是使用和事实型问题相同的答案抽取和排序方法,只是在返回结果时,将排序分值超过一定阈值的多个候选答案作为最终结果。也有研究利用各种在线知识库和网页中的表格来抽取答案。
对已有答案抽取方法进行总结,可以归类为:
( 1 )基于词袋模型的简单匹配
在文档句段中抽取和预期答案类型相一致的命名实体作为候选答案。对答案排序时,可以综合其所在文档句段的排序和在所有文档句段中出现的次数作为排序分值。
( 2 )基于表层模式匹配
基本思想是,问题的答案和问句关键词之间总有某些特定的表层关系。因此,算法不使用太多深层的语言处理,而是从文档句段中抽取出满足规则模式的候选答案。候选答案的排序要综合考虑所在文档句段的排序分值、规则权值、出现总次数。模式构造方式有手工构造方式和自动学习方式。
( 3 )基于语法结构比较
基本思想是,如果候选句子中的候选答案与问句词之间的语法结构,和在问题中疑问短语与问句词之间的语法结构能良好匹配,则该候选答案很可能是正确答案。比较方法有:基于语法结构模式的匹配;语法结构的严格匹配; 语法结构的统计匹配
( 4 )基于海量数据的冗余特性
基本思想就是在海量的文档集中,总会存在和问题描述方式相近的答案句子;而且一般来说,正确答案与问句关键词在检索结果中共现的次数要相对更多。因此,可以不用复杂的语言处理技术,而使用浅层语言技术辅助简单统计方法就可确定答案,同时取得不错的性能。
Web是海量数据的最好实例。从近几年参与 TREC 问答评测的系统看,几乎都会利用 Web ,同时会明显提高系统性能。
( 5 )基于答案的逻辑推理验证
使用逻辑推理进行答案选择和验证的研究主要在 LCC 公司的 Moldovan 和 Harabagiu 所带领的研究组,他们的系统也在历次 TREC 问答评测中取得了最好的性能。
基本思想是:从相关文档句段中抽取出多个满足问题预期答案类型的命名实体作为候选答案,根据这些候选答案在文档句段和 Web 上出现的次数等因素对它们进行初始排序;然后,利用逻辑推理的方法验证这些候选答案的正确性,验证正确则为最终答案 [4] 。
( 6 )基于多特征的统计机器学习方法
利用特定类型的单一特征总会存在不足。一种方法是将多种特征结合起来,发挥它们在不同条件下各自的优势。
这种类型系统的经典之一是 IBM 的统计问答系统 [5] ,用最大熵模型的概率大小来选择答案。特征包括: 1 )句子特征:问题和候选句间匹配的词和依存弧的分值等; 2 )实体特征:候选句中是否包含期望的命名实体类型; 3 )语言特征:候选答案是否是特定动词的主语或宾语等; 4 )词汇模式特征:候选句是否匹配某种词汇模式; 5 )候选答案的 Web 冗余特征。
定义型问题的答案抽取和生成
从现有的系统看,从相关文档中抽取、生成定义包含这几步: 1) 候选定义句子抽取:从文档中抽取出对目标进行描述、定义的句子; 2) 候选句子排序:对句子的重要程度进行区分; 3) 冗余信息去除:去除和已有句子在描述上重复的句子,去除句子中对目标定义无意义的部分; 4) 定义生成:将没有冗余信息的候选句子组织、综合成流利的定义描述。
( 1 )候选定义句子抽取与排序
抽取候选定义句子时,许多系统都利用规则来识别句子,而规则的设计都是利用各种特定的表征定义型句子的特征 ( 称为定义型语言构造, definitional linguistic contructs) 。这些特征包括:词法 - 语法表层模式 ( 如 “ <TARGET>, the $NNP ” );语法解析树的模式;同位语 (Appositives) ;系动词 (Copulas) ;定语从句 (Relative Clauses) ;谓词和动词短语 (Predicates and Verb Phrases) 。
对候选定义句进行排序时,一般是首先给定义目标构造一个质心向量 (centroid vector) ,然后依据各个候选句和该质心向量的相似度大小对候选句排序。质心向量中的词来源于全部候选句子,是和定义目标紧密相关、在外部资源(如 Web 、在线百科全书、知识辞典)中和定义目标经常共现的词。也有系统利用外部资源中的定义,对和外部定义有较高覆盖度的候选句子增加额外的权值。
( 2 )候选定义句子中冗余信息过滤与去除。
一个是冗余句子过滤,大多是采用多文档文摘中的方法,主要有基于词的句子过滤,和基于 n-gram 覆盖的句子过滤 [6] 。另外一个是冗余短语去除。在候选定义句子中,不可避免会有一些与目标定义无关的短语。采用的去除方法主要也是多文档文摘中已有的方法,如用特定的词法 - 语法特征识别冗余短语,然后将这些短语删除。
交互式问答中的答案抽取与生成
交互式问答的特点就是系统和用户之间有“对话”,这种对话并不只是“用户问”和“系统答”的过程。在交互过程中,一方面,用户输入不仅有特定信息查找的问题,也有属于对话的礼节性语句;另一方面,系统也可以主动提问或者提示,通过协商来明晰用户的真正需求。
聊天机器人是交互式问答的一种主要形式,这个容易理解,大家都熟悉的微软小冰就是聊天机器人。以前的方法主要是模板匹配。如约克大学的 Quarteroni 等 [7] 用 AIML 解释器来实现对话接口管理,对一般礼节性的应答采用模式匹配方法从问 / 答模式库中选择答案。模式库的建立一方面借助人工设计,另一方面利用模拟试验来获取。
AIML(Artificial Intelligence Markup Language),是一种基于 XML 的人工智能标记语言,来源于那个叫 Alice 的聊天机器人。下面是一个 AIML 的例子:
< category >
< pattern > 聊什么呢 </ pattern >
< template > 一起聊电影好吗 </ template >
</ category >
< category >
< pattern > 好 </ pattern >
< that > 一起聊电影好吗 </ that >
< template > 那你喜欢什么电影 </ template >
</ category >
< category >
< pattern > 好 </ pattern >
< template > 什么意思 </ template >
</ category >
另外一种就是基于隐式反馈的答案正确性自动评估。即通过用户后续的反应,对输出结果进行自动评估,然后根据评估结果对后续的检索、答案抽取方法进行调整和改进。还有可以通过“建议”和“提示”问题输出答案。在交互过程中,系统在给出答案的同时,也自动给出一些用户在后续可能会提出的问题,则会显著提高用户的满意度。
总结
上面主要对学术界在自动问答领域所做的研究做了一下概述,产业界的相关工作没有涉及,产业界似乎没有人做过开放域自动问答,主要是对某一领域做限定域自动问答,比如针对自己的业务,做基于 FAQ 的自动问答;或者是针对某一场景做自动语音对话,等等。
但产业界的工作一般不公开,具体是怎么做的,别人也不清楚。另外,我的经验是,产业界通常不会像学术界那样,应用高深的理论和复杂的方法去解决问题,通常是使用简单得不能再简单的方式处理问题,这样做会导致一个结果:虽然做出了一个实用的系统,但是没有什么可说的,或者说出来之后,别人一听就明白了,然后说:“啊,这么简单,你们也没做什么呀”。
就像我之前做过的所谓自动问答:先选出人工事先回答好的问答对存起来,用户提问时,就和问答对的问题做匹配,匹配上了,就返回答案,匹配不上,就去搜索。嗯,就这么简单。
参考文献 :
[1] Moldovan D., Pasca M., Harabagiu S., and Surdeanu M. Performance issues and error analysis in an open-domain question answering system. ACM Transactions on Information Systems, 2003 , 21(2):133--154.
[2] Harabagiu S. , Moldovan D. , Pasca M. , Mihalcea R. , Bunescu R. , Girju R. , Rus V. , and Morarescu P . Falcon: Boosting knowledge for answer engines. In: Proceedings of the Ninth Text REtrieval Conference
[3] Gaizauskas R . , Greenwood M. A. , Hepple M. , Roberts I. , Saggion H . and Sargaison M .The University of Sheffield’s TREC 2003 Q&A Experiments . In: Proceedings of the 12th Text R e trieval
[4] Harabagiu S., Moldovan D. I., Clark C., Bowden M., Hickl A. and Wang P. Employing Two Question Answering Systems in TREC-2005. In: Proceedings of the 14th R e trieval Conference (TREC 2005). Gaithersburg : NIST Special Publication: 2005.
[5] Ittycheriah A., Franz M. , and Roukos S . IBM’s statistical question answering system—TREC-10. In : Proceedings of the 10th Text REtrieval Conference (TREC 2001) . Gaithersburg, Maryland : NIST Special Publication, 2002.
[6] Cui H. , Kan M.-Y. and Chua T.-S. Soft Pattern Matching Models for Definitional Question Answering . to appear in ACM Transactions on Information Systems (TOIS). 2007. http://www.cuihang.com .
[7] Quarteroni S. , Manandhar S. . A Chatbot-based Interactive Question Answering System. Proceedings of the 11th Workshop on the Semantics and Pragmatics of Dialogue. Trento, Italy, 2007. 83–90 .
注:
本文的方法概述主要来自一位做自动问答方向的张姓博士,已经授权本人使用。
本文介绍的方法主要是学术界研究成果,仅供参考,不建议 IT 男深入研究及尝试。
-------------------------------------------------------------------------------------
黑夜路人,一个关注开源技术、乐于学习、 喜欢分享 的程序员
博客: http://blog.csdn.net/heiyeshuwu
微博: http://weibo.com/heiyeluren
微信:heiyeluren2012
想获取更多IT开源技术相关信息,欢迎关注微信!
微信二维码扫描快速关注本号码:

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

