Iowait的成因、对系统影响及对策
什么是iowait?
顾名思义,就是系统因为io导致的进程wait。再深一点讲就是:这时候系统在做io,导致没有进程在干活,cpu在执行idle进程空转,所以说iowait的产生要满足两个条件,一是进程在等io,二是等io时没有进程可运行。
Iowait是如何计算的?
先说说用户如何看到iowait吧
我们通常用vmstat就能看到iowat,图中的wa就是(标红)

这个数据是vmstat经过计算文件/proc/stat中的数据获得,所以说大家看到的是能够大概反应一个系统iowait水平的数据表象。关于/proc/stat中的数据都代表了什么意思,大家自己google吧,不再赘述。
那/proc/stat文件中的这些数据是从哪来的呢?
Kernel中有个proc_misc.c文件会专门输出这些数据,这个文件对应的函数是show_stat
部分代码:
for_each_possible_cpu(i) { intj; user = cputime64_add(user, kstat_cpu(i).cpustat.user); nice = cputime64_add(nice, kstat_cpu(i).cpustat.nice); system= cputime64_add(system, kstat_cpu(i).cpustat.system); idle = cputime64_add(idle, kstat_cpu(i).cpustat.idle); iowait = cputime64_add(iowait, kstat_cpu(i).cpustat.iowait); irq = cputime64_add(irq, kstat_cpu(i).cpustat.irq); softirq = cputime64_add(softirq, kstat_cpu(i).cpustat.softirq); steal = cputime64_add(steal, kstat_cpu(i).cpustat.steal); for(j = 0 ; j < NR_IRQS ; j++) sum += kstat_cpu(i).irqs[j]; } …. seq_printf(p, "/nctxt %llu/n" "btime %lu/n" "processes %lu/n" "procs_running %lu/n" "procs_blocked %lu/n", nr_context_switches(), (unsigned long)jif, total_forks, nr_running(), nr_iowait()); … 这部分代码会输出你在/proc/stat中看到的数据,通过代码我们得知iowait来自iowait = cputime64_add(iowait, kstat_cpu(i).cpustat.iowait);
那么 cpustat.iowait是谁来修改的呢?我们找到了这个函数account_system_time
voidaccount_system_time(structtask_struct *p, inthardirq_offset, cputime_t cputime) { structcpu_usage_stat *cpustat = &kstat_this_cpu.cpustat; structrq *rq = this_rq();//在smp环境下获取当前的run queue cputime64_t tmp; p->stime = cputime_add(p->stime, cputime); /* Add system time to cpustat. */ tmp = cputime_to_cputime64(cputime); if(hardirq_count() - hardirq_offset)//在做硬中断 cpustat->irq = cputime64_add(cpustat->irq, tmp); elseif(softirq_count())//在做软中断 cpustat->softirq = cputime64_add(cpustat->softirq, tmp); elseif(p != rq->idle)//程序在正常运行,非idle cpustat->system= cputime64_add(cpustat->system, tmp); elseif(atomic_read(&rq->nr_iowait) > 0)//既不做中断,而且在idle,那么就是iowait cpustat->iowait = cputime64_add(cpustat->iowait, tmp); else cpustat->idle = cputime64_add(cpustat->idle, tmp); /* Account for system time used */ acct_update_integrals(p); } 我们可以看出,当某个cpu产生iowait时,那么这个cpu上肯定有进程在进行io,并且在等待io完成(rq->nr_iowait>0),并且这个cpu上没有进程可运行(p == rq->idle),cpu在idle。
谁在产生iowait?
那么是谁修改了rq->nr_iowait呢?
重点终于来了,呵呵。
void__sched io_schedule(void) { structrq *rq = &__raw_get_cpu_var(runqueues); delayacct_blkio_start(); atomic_inc(&rq->nr_iowait); schedule(); atomic_dec(&rq->nr_iowait); delayacct_blkio_end(); } long__sched io_schedule_timeout(longtimeout) { structrq *rq = &__raw_get_cpu_var(runqueues); longret; delayacct_blkio_start(); atomic_inc(&rq->nr_iowait); ret = schedule_timeout(timeout); atomic_dec(&rq->nr_iowait); delayacct_blkio_end(); returnret; } 所以产生iowait的根源被我们找到了,就是函数io_schedule, io_schedule_timeout,顾名思义,这两个函数是用来做进程切换的,而且切换的原因是有io。只不过io_schedule_timeout还给出了一个sleep的时间,也就是timeout。
systemtap来跟一下到底是谁在什么时候调用了这两个函数?在这里我们以引擎为例子,trace进程searcher_server
Stap脚本Block.stp:(只截取了部分程序)
probe io_schedule = kernel.function("io_schedule"){ #if(tid() == target_pid){ if(isinstr(execname(),"searcher_server")){ stat[execname(), tid(), probefunc()]++; count++; printf("trace time:%s/n", ctime(gettimeofday_s())); print_stack(backtrace()); } } probe io_schedule_timeout = kernel.function("io_schedule_timeout"){ #if(tid() == target_pid){ if(isinstr(execname(),"searcher_server")){ stat[execname(), tid(), probefunc()]++; count++; printf("trace time:%s/n", ctime(gettimeofday_s())); print_stack(backtrace()); } } probe io_schedule, io_schedule_timeout{ } probe begin{ printf("begin %s/n", ctime(gettimeofday_s())); if($# == 2){ if(@1 == "pid") target_pid = strtol(@2, 10) if(@1 == "name") target_name = @2 printf("pid:%d name:%s/n", target_pid, target_name); }else{ printf("arguments error/n"); exit(); } } probe end{ printf("end %s/n", ctime(gettimeofday_s())); } probe timer.ms(1000){ printf("%s running.../n", ctime(gettimeofday_s())); foreach([proc, tid, func] in stat- limit 100){ printf("%s:%d=>%s %d/n", proc, tid, func, stat[proc,tid,func]); } deletestat; printf("%s average schedule times:%d/n", ctime(gettimeofday_s()), count); count = 0; } 程序的大意就是在1S内,统计哪个进程分别调用了多少次这两个函数。并且把调用时的堆栈print出来,这样能更清楚地看到到底是哪个系统调用跑到了这个地方。
在最正常的状态下,跑一下机器:
此时新 引擎 searcher QPS有1500+,cpu busy有88%,iowait几乎为0,内存在mmap时全部用MAP_LOCKED被锁在内存中
sudo stap block.stp pid 5739 -DMAXSKIPPED=1000000 Fri Jul 6 05:57:21 2012 average schedule times:0 Fri Jul 6 05:57:22 2012 running... Fri Jul 6 05:57:22 2012 average schedule times:0 Fri Jul 6 05:57:23 2012 running... Fri Jul 6 05:57:23 2012 average schedule times:0 Fri Jul 6 05:57:24 2012 running... Fri Jul 6 05:57:24 2012 average schedule times:0 Fri Jul 6 05:57:25 2012 running... Fri Jul 6 05:57:25 2012 average schedule times:0 …
跑了一会发现并没有调用到io schedule,这也符合我们的预期。我们再一边跑dd一边stap抓取
sudo stap block.stp pid 5739 -DMAXSKIPPED=1000000 > directdd
起两个dd进程,写10G的数据,不走page cache,direct写
dd if=/dev/zero of=a count=20000000 oflag=direct
dd if=/dev/zero of=b count=20000000 oflag=direct
一共写20G
-
Searcher表现:
-
被block的线程堆栈:
Cpu busy & iowait

Latency:
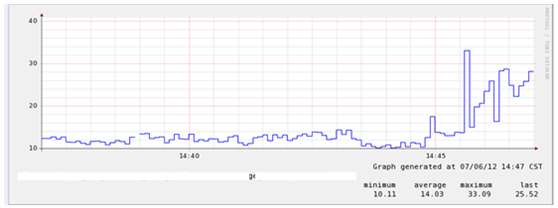
可以看出direct dd产生的iowait极小,最高才1.4左右,但是对searcher却也造成了不小的影响,通过vmstat的结果来看,当执行dd之后进程上下文切换从2W+飙到了8W+,被block的searcher线程为个位数。

写log
trace time:Fri Jul 6 06:46:23 2012 0xffffffff8006377c : io_schedule+0x1/0x67 [kernel] 0xffffffff800153e7 : sync_buffer+0x3b/0x3f [kernel] 0xffffffff800639e6 : __wait_on_bit+0x40/0x6e [kernel] 0xffffffff80063a80 : out_of_line_wait_on_bit+0x6c/0x78 [kernel] 0xffffffff8003a9d3 : sync_dirty_buffer+0x96/0xcb [kernel] 0xffffffff8000fd42 : generic_file_buffered_write+0x1cc/0x675 [kernel] 0x00000ffffffff800 trace time:Fri Jul 6 06:46:23 2012 0xffffffff8006377c : io_schedule+0x1/0x67 [kernel] 0xffffffff80028a90 : get_request_wait+0xd8/0x11f [kernel] 0xffffffff8000bfff : __make_request+0x33d/0x401 [kernel] 0xffffffff8001c049 : generic_make_request+0x211/0x228 [kernel] 0xffffffff80033472 : submit_bio+0xe4/0xeb [kernel] 0xffffffff8001a793 : submit_bh+0xf1/0x111 [kernel] 0x00000ffffffff800
被block的频率
grep -E 'run|ks_searcher'directdd | more searcher_server:21001=>io_schedule 1 searcher_server:20813=>io_schedule 1 Fri Jul 6 06:46:20 2012 running... Fri Jul 6 06:46:21 2012 running... Fri Jul 6 06:46:22 2012 running... Fri Jul 6 06:46:23 2012 running... Fri Jul 6 06:46:24 2012 running... searcher_server:20813=>io_schedule 2 searcher_server:21014=>io_schedule 1 Fri Jul 6 06:46:25 2012 running... Fri Jul 6 06:46:26 2012 running... Fri Jul 6 06:46:27 2012 running... Fri Jul 6 06:46:28 2012 running... Fri Jul 6 06:46:29 2012 running...
经stap追查发现,切换次数的增加都是由于direct dd导致的:由于是direct写,所以每写一次都要做io schedule
0xffffffff80062391 : schedule+0x1/0xcd4 [kernel] 0xffffffff800637ba : io_schedule+0x3f/0x67 [kernel] 0xffffffff800f281b : __blockdev_direct_IO+0x8bc/0xa35 [kernel] 0xffffffff800c4c91 : generic_file_direct_IO+0xff/0x119 [kernel] 0xffffffff8001edd1 : generic_file_direct_write+0x60/0xf2 [kernel] 0xffffffff8001646e : __generic_file_aio_write_nolock+0x2b8/0x3b6 [kernel]
小结:
Searcher latency上升和searcher相对温和的io schedule、进程切换都有关系,但是这时的主因应该是进程切换,进程切换还会造成频繁的进程迁移,TLB flush ,Cache pollution。
再做一次新的实验,把dd的direct flag去掉,让page cache生效
Searcher的运行环境和运行压力和上同
Searcher表现:
Cpu busy & iowait:
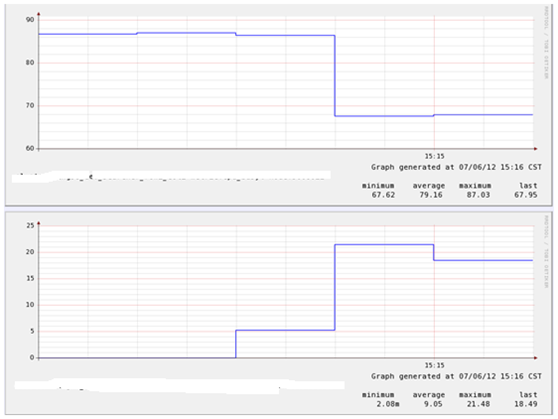
Latency:

可以看出带page cache的dd对searcher影响更大,我们先看一下vmstat抓取到的数据
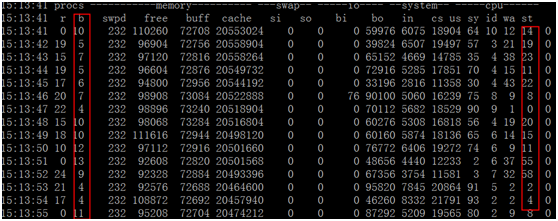
平均被block的线程数据很多,甚至在某个时刻可以运行的线程数量为0
searcher被block时的堆栈:
block layer写请求
trace time:Fri Jul 6 07:13:45 2012 0xffffffff8006377c : io_schedule+0x1/0x67 [kernel] 0xffffffff80028a90 : get_request_wait+0xd8/0x11f [kernel] 0xffffffff8000bfff : __make_request+0x33d/0x401 [kernel] 0xffffffff8001c049 : generic_make_request+0x211/0x228 [kernel] 0xffffffff80033472 : submit_bio+0xe4/0xeb [kernel] 0xffffffff8001a793 : submit_bh+0xf1/0x111 [kernel] 0x00000ffffffff800
Sync buffer
trace time:Fri Jul 6 07:13:46 2012 0xffffffff8006377c : io_schedule+0x1/0x67 [kernel] 0xffffffff800153e7 : sync_buffer+0x3b/0x3f [kernel] 0xffffffff800639e6 : __wait_on_bit+0x40/0x6e [kernel] 0xffffffff80063a80 : out_of_line_wait_on_bit+0x6c/0x78 [kernel] 0xffffffff8003a9d3 : sync_dirty_buffer+0x96/0xcb [kernel] 0xffffffff8001cdc3 : mpage_writepages+0x1bf/0x37e [kernel] 0x00000ffffffff800
此时的dirty ratio已大于40%,需要做blk_congestion_wait,这个可以算是最严厉的惩罚了。。
trace time:Fri Jul 6 07:13:48 2012 0xffffffff800631bb : io_schedule_timeout+0x1/0x79 [kernel] 0xffffffff8003b426 : blk_congestion_wait+0x67/0x81 [kernel] 0xffffffff800c7e68 : balance_dirty_pages_ratelimited_nr+0x17d/0x1fa [kernel] 0xffffffff8000fd81 : generic_file_buffered_write+0x20b/0x675 [kernel] 0xffffffff8001651f : __generic_file_aio_write_nolock+0x369/0x3b6 [kernel] 0xffffffff8002157b : generic_file_aio_write+0x65/0xc1 [kernel] 0x00000ffffffff800
Searcher用到的某些页被刷出去,需要sync page read
trace time:Fri Jul 6 07:13:49 2012 0xffffffff8006377c : io_schedule+0x1/0x67 [kernel] 0xffffffff80028936 : sync_page+0x3e/0x43 [kernel] 0xffffffff800638fe : __wait_on_bit_lock+0x36/0x66 [kernel] 0xffffffff8003fbad : __lock_page+0x5e/0x64 [kernel] 0xffffffff800139f8 : find_lock_page+0x69/0xa2 [kernel] 0xffffffff800c45a5 : grab_cache_page_write_begin+0x2c/0x89 [kernel] 0x00000ffffffff800
被block的频率:
searcher_server:21010=>io_schedule 3 searcher_server:21003=>io_schedule 1 Fri Jul 6 07:14:39 2012 running... searcher_server:21010=>io_schedule 7 Fri Jul 6 07:14:40 2012 running... searcher_server:21008=>io_schedule 1 Fri Jul 6 07:14:41 2012 running... Fri Jul 6 07:14:42 2012 running... searcher_server:21004=>io_schedule 1 Fri Jul 6 07:14:43 2012 running... searcher_server:21014=>io_schedule 11 searcher_server:21015=>io_schedule 1 searcher_server:21008=>io_schedule 1 Fri Jul 6 07:14:44 2012 running... Fri Jul 6 07:14:45 2012 running... Fri Jul 6 07:14:46 2012 running... searcher_server:21003=>io_schedule 2 Fri Jul 6 07:14:47 2012 running... Fri Jul 6 07:14:48 2012 running... Fri Jul 6 07:14:49 2012 running...
小结:
当带page cahce进行dd时,很容易就能达到10%的background dirty ratio和40%的dirty ratio,达到40%的时候buffered write就变成了sync write。经stap trace发现每次blk_congestion_wait都要耗时100ms左右,也就是说一个线程要被block 100ms,很致命。
为了减少io的影响,我们把log给禁掉
再做一次实验
Searcher表现:
Cpu busy & iowait
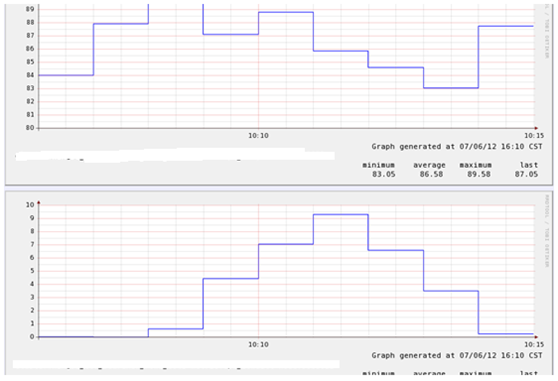
Latency:
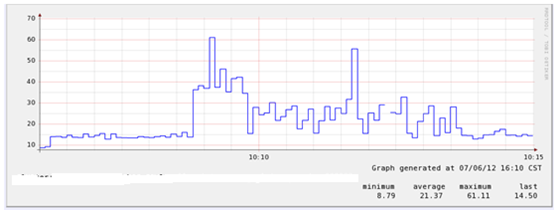
把写log关掉之后竟然还有iowait,是谁造成的呢?
Searcher被block时的堆栈:
trace time:Fri Jul 6 02:08:28 2012 0xffffffff8006377c : io_schedule+0x1/0x67 [kernel] 0xffffffff80028936 : sync_page+0x3e/0x43 [kernel] 0xffffffff800638fe : __wait_on_bit_lock+0x36/0x66 [kernel] 0xffffffff8003fbad : __lock_page+0x5e/0x64 [kernel] 0xffffffff80013881 : filemap_nopage+0x268/0x360 [kernel] 0xffffffff8000898c : __handle_mm_fault+0x1fa/0xf99 [kernel] 0x00000ffffffff800
我们的内存都被mlock了,竟然还有sync page,为啥呢?
用blktrace和debugfs追了一下,发现竟然是一个算法数据的问题
/path/of/data
原来是这个文件的数据被dd给刷出去了,导致还要重新read到内存
然后写了个程序把这个数据也lock到内存中
./lock /path/of/data
Lock数据再重新跑dd with page cache
Searcher 表现:
Cpu busy & iowait:

Latency:
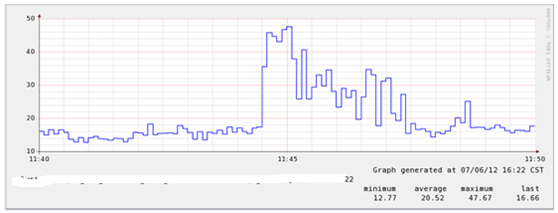
可以看到,iowait水平又降低了不少,那么此时此刻,谁还在制造iowait呢?
Searcher被block时的堆栈:
trace time:Fri Jul 6 03:45:04 2012 0xffffffff800631bb : io_schedule_timeout+0x1/0x79 [kernel] 0xffffffff8003b426 : blk_congestion_wait+0x67/0x81 [kernel] 0xffffffff800ca438 : try_to_free_pages+0x252/0x2d7 [kernel] 0xffffffff8000f40d : __alloc_pages+0x1cb/0x2ce [kernel] 0xffffffff80008e62 : __handle_mm_fault+0x6d0/0xf99 [kernel] 0xffffffff80066b25 : do_page_fault+0x4cb/0x830 [kernel] trace time:Fri Jul 6 03:45:04 2012 0xffffffff800631bb : io_schedule_timeout+0x1/0x79 [kernel] 0xffffffff8003b426 : blk_congestion_wait+0x67/0x81 [kernel] 0xffffffff800ca438 : try_to_free_pages+0x252/0x2d7 [kernel] 0xffffffff8000f40d : __alloc_pages+0x1cb/0x2ce [kernel] 0xffffffff8002600b : tcp_sendmsg+0x567/0xb0e [kernel] 0xffffffff80037c60 : do_sock_write+0xc6/0x102 [kernel]
原来是内存很少了,导致申请内存时要走到try_to_free_pages(平时极少走到),走到这一步说明系统内存已经少的可怜。但是没办法,谁让searcher还要去malloc呢,这些malloc来自两部分:1,mempool申请的内存,其实这个是完全可以抹掉的 2,算法so中STL部分用到的内存。
小结:
关掉log,将数据都lock在内存中,降低了iowait的水平,但是要让searcher不受影响,还要做更多的工作,比如不申请内存。
如何消除searcher(或应用系统)的iowait?
1,没有io
不写log,或者把写log的事情交给一个专门线程来做,searcher不做buffered write;不做disk read,尤其是sync page这类操作。
2,全内存且不申请内存
用到的数据read once,全内存且lock住;把mempool做到完美,起码做到99%的case不做内存申请。
3,尽量减少其他应用的io影响
其实就是能将dd的负面影响降到最少,如用cgroup;在scp多个大文件的时候,在传输过程中及时清理每个大文件的page cache,将系统的dirty ratio维持在10%以下,尤其是不能达到40%。
工具连接:
Systemtap
Blktrace+Blkparse+Debugfs 结合使用,会找到每次io对应的磁盘块所属inode,还可以查看块内容
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

