评判云服务靠谱程度
本文依据孙宇聪在 SegmentFault D-Day 北京场的演讲内容整理,并授权首发于“高效运维”公众号。10月11日,SegmentFault 将在上海举办D-Day,围绕 Docker 主题。Coding.net WebIDE 项目负责杜万将受邀参与分享《Docker Container 磁盘容量限制》。了解更多可 点击这里
云服务真的靠谱吗?
相信对这个问题每个人心里都有不同的答案。我今天想讲的是如何客观的去回答这个问题, 其中结合了 Coding 的一些实践和思考。

广义范围的“靠谱” 有几个比较重要的点。
第一个点就是 Availability (可用性) ,24x7随时可用。一个靠谱的云服务一定是可用性非常高的。
第二点是 Access Control ,可控性一定要好,非云服务你可以上个锁,云服务如何能做到可控性很好,很难。
第三点是 灾难恢复 ,是软件就会有问题。怎么样积极的面对这个问题,这是任何一个云厂商都要诚实面对的问题。
可用性
首先第一点我们看来讲一下可用性,可用性只有一个评判标准,就是 SLA,Service Level Agreement,更多的时候是 SLO, 只是 Objective。 一个东西是不是高可用,那么就问他几个九,敢不敢拿出来说一下。
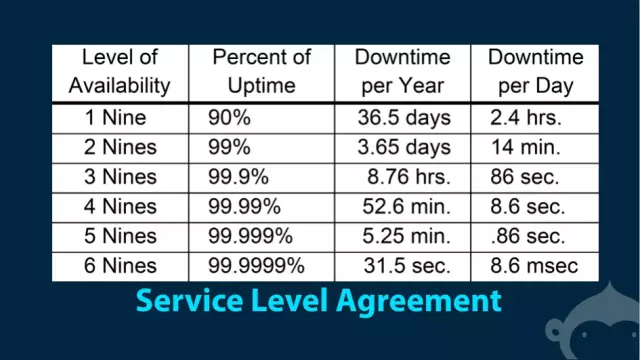
实实在在的看着这个图说话,3个9基本上是国内云服务的基础线。也就是说**云服务至少要做到3个9才称为基本上可用**,是合格性产品。如果是做不到这个,你的东西就只是玩具,快回去好好把技术内功修炼修炼再出来刷脸。从3个9迈向4个9,也就是99.99%的可用性,每年只有52.6分钟的时间是不可用的。
以前的谷歌搜索可用度大概是全球5个9到6个9之间,每一个小节点都是5个9不到6个9之间。想想吧,这其实是很可怕的一个概念。**因为这里包含了可能发生的一切事故**,不管什么不可抗力,都是扯淡。地震、洪水、台风、大楼震塌了,也是5分钟内恢复服务。
相比之下,大部分国内的IDC机房都是按照99%设计的,一年至少3天是不可用,这3天给你花在元旦一天,春节一天,国庆一天,省点时间给你机动(笑)。这里不可用就是不可用,求爷爷告奶奶也照样不能用。
所以说 SLO 直接反映一个云服务的靠谱程度:
从99%到3个9,是基本可以靠堆人和运气解决的;
从3个9到4个9,考验的是运维自动化的能力,灾备的能力;
从4个9往上基本考验的是服务基础架构、业务设计的能力。
我们也在3个9到4个9之间努力, 这个还是很有难度的。如果一个云服务厂商在注释里加了句“不可抗力排除在外”,这是非常不合适的。
那么如何提升可用性:
Design For Redundancy, 第一是一定要做到所谓的**“无状态微服务”**,去掉单点故障。 首先是“微服务”, 一个服务分解的越简单,出错的面就越小,失败模式就越固定 。然后是“无状态”,这样才可以做到无限扩展。 这个很难的, 很多时候最后拆来拆去都发现有一个数据库在最后,这个数据库就做不到无状态,永远只能有一个数据库,一个数据库实例在那摆着,可用性永远上不去。
有了无状态的微服务这种架构,还要做到 N+2 。很多时候很多厂商连N都不知道(因为从没有做过压力测试,性能分析),何谈N+2?
Design For Gradual Deployment, 第二就是要**支持灰度发布**。一个服务要前进,任何软件组件都要改,都会改。更新操作会直接提高你系统出问题的可能性。想要提高可用性,**必须将发布的代价降低**。只有能够做到说我上线一个新功能,只给某几个用户用,其他的用户不受这个影响。这样才能提高你整个系统作为一个整体的可用性,
Design for Clustering: 第三点是要**区分 Cluster management 和 App Managment 的概念, 把资源的调配和服务调配分开。**

Design for Automation,最后一点是**自动化**。一个靠谱的云服务,从设计之初就把人的因素排除在运行之外。整个系统应该是全自动化运行的,不需要你人来干预。云服务初期买了二三台个服务器,服务器放在那,有人天天盯着它才正常运行,这还有可能,上了规模之后显然是不可能的。这是最关键的一点。任何一个云服务到现在内部都是非常复杂的,他就像这个漫画里边这样,每一个人操作它的时候,面前有无数的按钮,无数的可能性。除了问题之后,如果让一个人马上搞清楚弄明白立刻解决,这是不可能的,只能自动化。
而且其实更多的时候都是人的操作带来的问题,更新一个软件,更新一个服务器都不可避免的有人要参与。如果不做自动化,早晚会出问题。

任何的靠谱的云服务厂商至少要做到以下几点:
第一个SLA一定要达到4个9,你达不到这个4个9基本上相当于你这个服务就是一个玩具,根本没有办法依赖你。
第二个是一个数量级,甚至两个数量级以上的预研。
第三就是 Automation 自动化。这就是实践中的一个经验。
可控性
接下来我们看一下可控性。 一提 Access Control 最关键的一点是要 Defense in Depth 。就好比你想一下从自己家到公司办公室要经过多少层门,每个门的存在就是一层防御,每个门有不同的开锁方式能挡住不同的人。
云服务也是一样的,Access Control 做得越好,这个云服务越安全。首先从**最基础的 Physical Security 开始**。 有一句话说的好,任何软件上的花招都抵不过一个螺丝刀。评判一个云服务是否靠谱,先看他们是否做好了 Physical Security,如果没做, 这个服务就是瞎扯。如果一个云服务想过这个问题,说明他真正的认识到安全的重要性了。 什么机柜上锁,指纹识别,声纹识别,脸型识别,虹膜识别,姿态识别什么什么的,怎样也不嫌多。(笑)

那么接下来, 我们看一下逻辑上的Access Control机制。
第一点:秘密的管理。
任何云服务都有一堆秘密,这个秘密可能是服务器Root密码,也可能是交换机的密码什么的,这些东西怎么去保管,怎么去分发,直接体现了一个云服务厂商的靠谱程度。
任何一个云服务厂商正常运转不可能把秘密都寄托在单个人身上,也不可能让全公司人全都知道。秘密管理怎么来做,这是一个很关键一点。Coding 使用的是 GPG Multi-recipent 加密,如果另外一个厂商能把这个事情跟你讲清楚,这个云服务才靠谱。
第二点:审核记录.
任何云服务要看他的靠谱程度, 就问他有没有, 如何实现的审核记录系统。 审核记录应该是独立于其他所有业务组件之外一个关键组件 ,他应该记录了你这个系统里面发生的所有的事情。审核记录是唯一、真实、可靠的数据来源。
第三点:运营系统的权限分级。
任何一个云服务厂商都有这个运营后台,这个运营后台肯定做一个权限分析,哪些人可以看到统计分析,我们网站有多少新用户,趋势是什么样的。有些东西是敏感数据,除了我们运维有限几个人,没有人能够访问用户的数据,再细节的东西,都是**严格把控**的,公司大部分人都绝对没有任何的 Code Access。
Access Control 做到这里就行了么?还差得远,想要做的好, 还有以下几点:
第一点:Fine-grained/Rolebased Access Control.
很多云服务,从外面看起来碉堡了,但是只要接入公司网络上就可以随便改数据库(笑)。如果一个公司认为他内网绝对安全,那么他的服务就是绝对不靠谱。Accesss Control 首先要做到角色为基础,**每个角色给固定的 ACCESS 权限**,第二点,必须**更细粒度**,具体到每一个 HTTP handler, 每一个 RPC 都要权限校验,否则就是正在瞎扯。
第二点:Identity Delegation。
大部分的云服务的设计都是一堆超级管理员进程,这些超级管理员进程可以改一切数据,做一切事。每个bug都会影响到整个服务的数据安全。 Identity Delegation就是改变了这个事情,在入口处(和用户直接接触处)发了一个令牌,**以后所有的操作都带着这个令牌去操作用户数据**,没有令牌就改不了。 这样大大降低了某个bug影响所有用户数据的可能性。
第三点: Application Level Encryption
其实大家都知道,加密很损耗性能,但是如果哪个云服务厂商没有做数据加密,就说明你对这个数据真的是关心不够,基本属于耍流氓。

第四点:对应用层漏洞的关注度
我在这里介绍一下,OWASP,是一个开源网站,里面有所有市面上一些常见的网络应用的安全漏洞列表,如何去处理,如何去防范它。这里列出了十大关键问题,如果你不知道这个列表, 那就说明你对安全的关注还不够,赶紧上这个网站去看看。Coding 跟乌云,FreeBuf 都有合作,体系化,系统化的去解决这个问题。如果哪个厂商不关注这个事情,这个云服务就是不合格的。
灾难恢复
最后讲一讲 Disaster Recovery一个云服务, 你问他你这个东西好用吗,好用,安全吗?安全。出问题怎么办,不知道,没人跟你说的明白。这是典型的不靠谱。
0 - 15 min:
如果一个云服务挂了,从故障开始到十五分钟结束还没有恢复,排除大型灾难的可能性 ,基本可以认为他们不靠谱。
零到十五分钟这个时间,是一个很大的关键时间点,他基本上是人力的极限,从出问题收到自动化报警,然后赶紧电脑打开,连上VPN,发现问题,处理问题,做到最快15分钟基本上可以说是极限了。
就算你的运维团队都是24小时不合眼电脑不离身,15分钟内恢复服务也需要两个关键点:**第一常驻,第二热备。**
常驻热备灾难恢复系统,也就是说你必须有一套一模一样的系统随时跑着,生产系统挂了,自动切换到备用系统上。常驻热备,是**随时随地可以切换,随时随地可以开始服务,能完全接管不受影响。**
你一台机器的电被拔了,硬盘挂了,宇宙射线击中了你的CPU,你也可以自动无缝切换。
大家还记得前一段雷击、挖光缆的事情吗,很多人说被雷击了我就挂了这很正常。其实用户管你什么原因, 你挂了就是挂了,为什么没有常驻热备系统?为什么会挂?小服务更应该有这个能力,双系统跨云部署,有了这个才有能力做 Master Slave Automated Failover。靠谱的云服务厂商才会给你讲到这一点。
15 min - 3 hour:
这里的3个小时是个虚数,根据你的业务重要程度你可以自行定义。 3个小时是什么的意思呢,不管你什么样的问题,如果你三个小时之内修不好,你的网站就消失了。大家对你这个云服务的厂商的能力的信任程度就基本归0 了。 想想如果 Coding 突然挂了,突然不能访问了,再回来的时候基本就告别互联网了,对大家的打击、损失是无法承受的。
十五分钟到三个小时,这是我们目前定的一个标准,不管什么灾难,三个小时之内如果恢复不了服务,说明我们工作做得不到位。达到这一点没有捷径,唯一的一点就是要有**应急备案,要随时演练**。
我们随时假定一个场景,外星人入侵了,搞坏了XXX(笑), 你们给我模拟恢复一下 Coding 的系统。这是比较高级大的演练。平时也有小的演练,三五个人聚在一起。如果有一台机器重启不起来怎么办?所有的都是 Operational Readiness Drill 平时不断的练,不断的有准备。
要做到这一点:Immutable Infrastruture。**可重现部署**。
很多云,包括 Coding 以前也是这样,我开一个新机器以后,一些人装了一些软件。之后辞职了,突然有一天这个机器挂了就没招了。除了把这台机器修好了,什么也做不了。想要灾难恢复,你就要把这个东西做到可重现。**要清晰的知道这个机器上,装了什么东西,为什么装这个东西。**
做不到这一点的云服务厂商,没有资格说我们是一个靠谱的云服务。
最后再说一下**备份系统**。备份系统好像是个挺简单的东西,跑起来,平时也不怎么用管,然后他就解决问题了吗?!说的好像备份系统一定备份了你想要的数据, 就算他备份了全部数据,好象就是百分之百不会丢东西的一样。
每一个备份系统都有一个叫 Durability 指标 。也就是备份系统的靠谱程度。不管什么媒介,都有可能挂掉,写到硬盘上,硬盘可能坏,写到磁带上,磁带也会坏, 写到纸上,纸都可能烂掉。就算这些都不坏,你也可能宇宙射线来了,打了一下这个硬盘。硬盘受什么强磁场某一个位置就变了,你整个东西还是访问不了。这些东西不考虑,硬说一个备份系统百分之百可靠,这都是自欺欺人。
Coding 原来也没有好的备份系统,我们最近在搞 AWS Glacier,它有一个大的磁带库,你把东西存进去的话,自动转存到磁盘、磁带上,定期维护。 AWS Glacier 有一个算法,每个硬盘大概多长时间坏一次,每个磁带多长时间坏一次。最后得出来他们的Durability 可以做到11个9。
如果一个云厂商连这样一个系统都不舍得去关注的话,你对用户的数据太不在乎了。
有了备份,最最重要的还是恢复。 如果一个备份系统不能随时演习细粒度的恢复,那他就是没用的,关键时刻他一定掉链子,想都不用想。
最后的最后, 很多人说这么多云服务哪家靠谱,哪家安全。我觉得只能和大家共勉啦,Coding 做得还不够多,很多东西都是在探索中,希望跟大家一起多交流,把云服务搞得更靠谱。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

