化繁为简——分解复杂的SQL语句 - 潇湘隐者
今天同事咨询一个SQL语句,如下所示,SQL语句本身并不复杂,但是执行效率非常糟糕,糟糕到一塌糊涂(执行计划也是相当复杂)。如果查询条件中没有NOT EXISTS部分,倒是不要一秒就能查询出来。
SELECT * FROM dbo.UVW_PDATest a WITH(NOLOCK)WHERE Remark='前纺' AND Operation_Name='粗纱' AND One_Status_Code='0047' AND a.Createtime >='2015-9-23'AND NOT EXISTS ( SELECT 1 FROM dbo.UVW_PDATest c WITH(NOLOCK) WHERE a.Task_NO =c.Task_NO AND c.One_Status_Code='0014' )
为什么如此简单的SQL语句,执行效率却一塌糊涂呢,因为UVW_PDATest是一个视图,而且该视图是由8个表关联组成。
SELECT ..........From dbo.PDA_TB_Produce a With(Nolock) Join dbo.DctOperationList b With(Nolock) On a.Operation_Code=b.Operation_Code Join dbo.DctOneStatusList c With(Nolock) On a.One_Status_Code=c.One_Status_Code Left join dbo.DctTwoStatusList d With(Nolock) On c.One_Status_Code=d.One_Status_Code and a.Two_Status_Code=d.Two_Status_Code left Join dbo.DctMachineList e With(Nolock) On a.Operation_Code=e.Operation_Code and a.Machine_Code=e.Machine_Code left Join dbo.DctOperationList f With(Nolock) On a.Next_Operation_Code=f.Operation_Code Join dbo.DctUserList g With(Nolock) On a.User_ID_Operating=g.User_ID Join dbo.DctUserList h With(Nolock) On a.User_ID=h.User_ID
刚开始我想从索引上去优化,加上一两个索引后发现其实并无多大益处。为什么性能会如此糟糕呢?原因是什么呢?
大量复杂的Join
该类查询模式包含了大量连接,尤其是连接条件是不等连接,由于统计信息随着表连接的增多精度逐渐下降,这会导致低效的查询性能。解决这类情况可以通过分解查询,并将中间解决存入临时表解决。 具体参考博客: 什么情况下应该分解复杂的查询来提升性能
于是我拆分上面SQL语句(如下所示),先将执行结果保存到临时表,然后关联取数,结果一秒钟的样子就执行出来了。真可谓是化繁为简。
SELECT Task_NO INTO #TMP_MID_UVW_PDATestFROM dbo.UVW_PDATest c WITH(NOLOCK) WHERE One_Status_Code='0014' and Remark='前纺' AND Operation_Name='粗纱' SELECT * INTO #TMP_UVW_PDATestFROM dbo.UVW_PDATest a WITH(NOLOCK)WHERE Remark='前纺' AND Operation_Name='粗纱' AND One_Status_Code='0047' AND Create_Date>='2015-9-23' ; SELECT * FROM #TMP_UVW_PDATest a WHERE NOT EXISTS(SELECT 1 FROM #TMP_MID_UVW_PDATest c WHERE a.Task_NO =c.Task_NO ); DROPTABLE#TMP_UVW_PDATestDROP TABLE #TMP_MID_UVW_PDATest
第二个案例是ORACLE数据库的一个优化案例,具体SQL语句如下所示,执行时间非常长,一般都是二十多秒左右。
SELECT A.SC_NO, A.MRP_GROUP_CD, A.DIMM_ID, A.JOB_ORDER_NO, DECODE(SIGN(A.DEMAND_QTY),-1,0,A.DEMAND_QTY) AS DIFF_QTY, A.ASSIGNED_TYPE FROM ( SELECT CC.SC_NO, BB.MRP_GROUP_CD, BB.DIMM_ID, BB.JOB_ORDER_NO, NVL (SUM (BB.DEMAND_QTY), 0) - NVL(SUM(REC.RECV_QTY),0) AS DEMAND_QTY, CASE WHEN DD.REQ_DATE<TRUNC(SYSDATE) THEN 'AH' ELSE 'AS' END AS ASSIGNED_TYPE FROM MRP_JO_DEMAND BB, PO_HD CC , ( SELECT JOB_ORDER_NO, DIMM_ID, SUM(RECV_QTY) AS RECV_QTY FROM MRP_AGPO_SCHD_RECV_SPECIFIC GROUP BY JOB_ORDER_NO, DIMM_ID ) REC, MRP_JO_ASSIGN DD WHERE BB.JOB_ORDER_NO=CC.PO_NO AND BB.JOB_ORDER_NO=REC.JOB_ORDER_NO(+) AND BB.DIMM_ID=REC.DIMM_ID(+) AND BB.JOB_ORDER_NO = DD.JOB_ORDER_NO(+) AND BB.DIMM_ID = DD.DIMM_ID(+) AND BB.MRP_GROUP_CD=DD.MRP_GROUP_CD(+) AND EXISTS ( SELECT 1 FROM MRP_DIMM AA WHERE AA.MRP_GROUP_CD=BB.MRP_GROUP_CD AND AA.DIMM_ID=BB.DIMM_ID AND AA.JOB_ORDER_NO=BB.JOB_ORDER_NO ) GROUP BY CC.SC_NO, BB.MRP_GROUP_CD, BB.DIMM_ID, BB.JOB_ORDER_NO, DD.REQ_DATE ) A, INVSUBMAT.INV_MRP_JO_AVAILABLE_V B WHERE A.JOB_ORDER_NO = B.JOB_ORDER_NO AND A.MRP_GROUP_CD = B.MRP_GROUP_CD AND A.DIMM_ID = B.DIMM_ID AND NVL (A.DEMAND_QTY, 0) < NVL (B.AVAILABLE_QTY, 0) AND NVL (B.AVAILABLE_QTY, 0)>0 ORDER BY A.MRP_GROUP_CD, A.DIMM_ID, A.JOB_ORDER_NO;

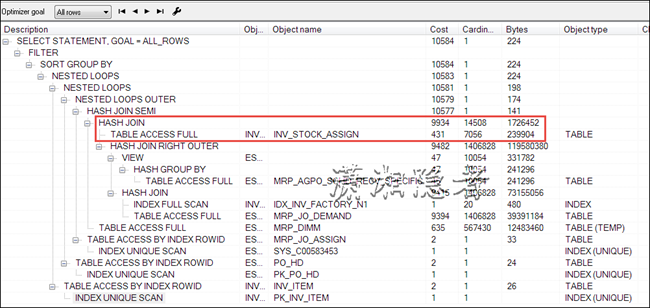
查看执行计划,你会发现COST主要耗费在HASH JOIN上。如下截图所示,表INV_STOCK_ASSIGN来自于视图INVSUBMAT.INV_MRP_JO_AVAILABLE_V。
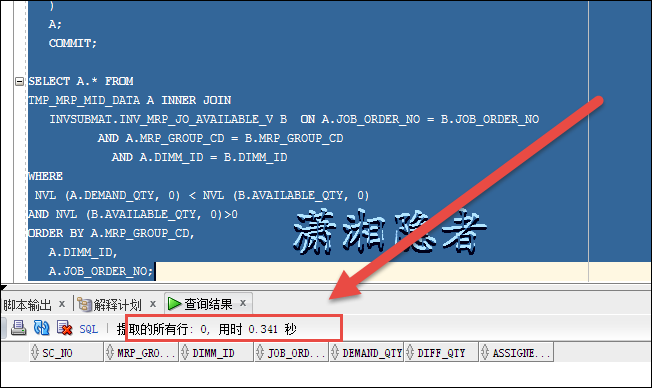
将上面复杂SQL拆分后,执行只需要不到一秒解决,如下截图所示,速率提高了几十倍。优化往往有时候很复杂,有时候也很简单,就是将复杂的语句拆分成简单的SQL语句,性能的提升有时候确实令人吃惊!
CREATE GLOBAL TEMPORARY TABLE TMP_MRP_MID_DATA( SC_NO VARCHAR2(20) , MRP_GROUP_CD VARCHAR2(10) , DIMM_ID NUMBER, JOB_ORDER_NO VARCHAR2(20) , DEMAND_QTY NUMBER , DIFF_QTY NUMBER , ASSIGNED_TYPE VARCHAR(2)) ON COMMIT PRESERVE ROWS; INSERT INTO TMP_MRP_MID_DATASELECT A.SC_NO, A.MRP_GROUP_CD, A.DIMM_ID, A.JOB_ORDER_NO, A.DEMAND_QTY, DECODE(SIGN(A.DEMAND_QTY),-1,0,A.DEMAND_QTY) AS DIFF_QTY, A.ASSIGNED_TYPE FROM ( SELECT CC.SC_NO, BB.MRP_GROUP_CD, BB.DIMM_ID, BB.JOB_ORDER_NO, NVL (SUM (BB.DEMAND_QTY), 0) - NVL(SUM(REC.RECV_QTY),0) AS DEMAND_QTY, CASE WHEN DD.REQ_DATE<TRUNC(SYSDATE) THEN 'AH' ELSE 'AS' END AS ASSIGNED_TYPE FROM MRP_JO_DEMAND BB INNER JOIN PO_HD CC ON BB.JOB_ORDER_NO=CC.PO_NO LEFT JOIN ( SELECT JOB_ORDER_NO, DIMM_ID, SUM(RECV_QTY) AS RECV_QTY FROM MRP_AGPO_SCHD_RECV_SPECIFIC GROUP BY JOB_ORDER_NO, DIMM_ID ) REC ON BB.JOB_ORDER_NO=REC.JOB_ORDER_NO AND BB.DIMM_ID=REC.DIMM_ID LEFT JOIN MRP_JO_ASSIGN DD ON BB.JOB_ORDER_NO = DD.JOB_ORDER_NO AND BB.DIMM_ID = DD.DIMM_ID AND BB.MRP_GROUP_CD=DD.MRP_GROUP_CD INNER JOIN MRP_DIMM AA ON AA.MRP_GROUP_CD=BB.MRP_GROUP_CD AND AA.DIMM_ID=BB.DIMM_ID AND AA.JOB_ORDER_NO=BB.JOB_ORDER_NO GROUP BY CC.SC_NO, BB.MRP_GROUP_CD, BB.DIMM_ID, BB.JOB_ORDER_NO, DD.REQ_DATE ) A; COMMIT; SELECT A.* FROMTMP_MRP_MID_DATA A INNER JOIN INVSUBMAT.INV_MRP_JO_AVAILABLE_V B ON A.JOB_ORDER_NO = B.JOB_ORDER_NO AND A.MRP_GROUP_CD = B.MRP_GROUP_CD AND A.DIMM_ID = B.DIMM_ID WHERENVL (A.DEMAND_QTY, 0) < NVL (B.AVAILABLE_QTY, 0) AND NVL (B.AVAILABLE_QTY, 0)>0 ORDER BY A.MRP_GROUP_CD, A.DIMM_ID, A.JOB_ORDER_NO;
小结:
1:越是复杂的SQL语句,优化器越是容易选择一个糟糕的执行计划(优化器之所以难以选定最优的执行计划,是因为优化器要平衡选定最优执行路径的代价,不能一味为了选择最优执行计划,而将复杂SQL的所有执行路径都计算对比一遍,往往只能有选择性的选取一些执行路径计算对比,否则开销太大。而越是复杂的SQL,可选择的执行路径就是越多。
说得有点绕口,还是打个比方,比如你从广州到北京,如果就只有飞机(直飞),火车(直达)、汽车(直达)三种选择,那么想必你能很快给出一个最优的路线(例如,最快的是飞机、最省钱的是火车),但是如果飞机、火车、汽车都不能直达:假如火车票没有了直达,你必须中途转几次、飞机票也没有直达了,你需要转机,那么此时选择性复杂的情况,你就必须花费不少时间才能制定一个最优的计划了。 如果在复杂一点的情况,你从中国去美国,是不是有N种路径? 如果全部计算对比一遍各种可能的路径,估计你小脑袋不够用………………
2:执行计划是可以被重用的,越简单的SQL语句被重用的可能性越高。而复杂的SQL语句只要有一个字符发生变化就必须重新解析,然后再把这一大堆垃圾塞在内存里。可想而知,数据库的效率会何等低下。
3:如果SQL语句过分复杂,要么是业务有问题,要么是模型设计不当。可以说复杂的SQL反映出系统设计方面有不少问题和缺陷。
本文链接: 化繁为简——分解复杂的SQL语句 ,转载请注明。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

