【源】从零自学Hadoop(07):Eclipse插件
阅读目录
- 序
- Eclipse
- Eclipse插件
- 新建插件项目
- 系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
上一篇,我们的第一个Cluster搞定了,按平常的搭建集群来说,应该是至少3个DataNode的,应为默认的一份HDFS文件分成3份,所以最少也得3个DataNode的服务器,但由于本机就一块硬盘,内存也不大,所以,勉强的用2份。
在这里我们开始使用MyCluster了,有个Eclipse的插件用上去后,对HDFS文件的处理就比较方便了,我们开始吧!
Eclipse
我们直接去官网下个Eclipse,不要太旧的就行了。为了大家的方便,下面放一个官网的地址。
http://www.eclipse.org/downloads/
Eclipse插件
一:原因:
为什么要用这个插件了?有什么好处了?
因为我们待分析的文件需要从客户端通过rpc传到NameNode,所以在linux中,是找不到这个文件的,相当于是做了个隔离,所以用个插件就很方便的上传这些文件了,还可以查看目录结构,文件内容。分析后结果也是很方便的查看的到。
二:地址
https://github.com/winghc/hadoop2x-eclipse-plugin
在Release中,我们可以看到有3个编译好的jar包。都是2.0以上的版本,所以对于hadoop2.0以上的都可以用。
三:安装
将插件放入eclipse的插件目录,“eclipse/plugins”。
重启Eclipse
进入Windows->Preferences
选择Hadoop的路径

四:查Hadoop配置信息
首先,我们得知道我们的NameNode和HDFS的地址。
我们进入ambari登陆页面。
选中HDFS->Config,圈中的就是HDFS的地址。
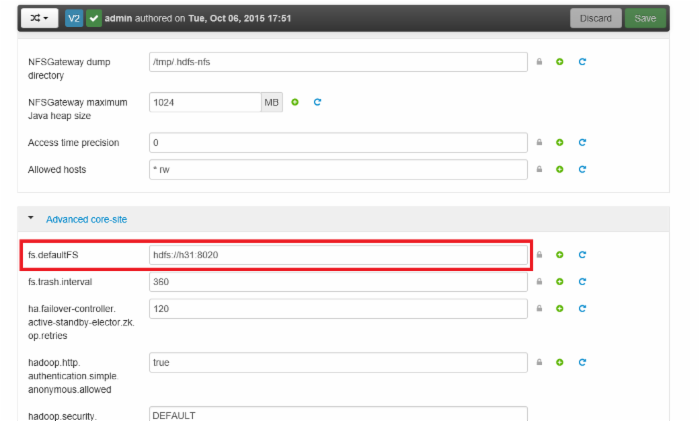
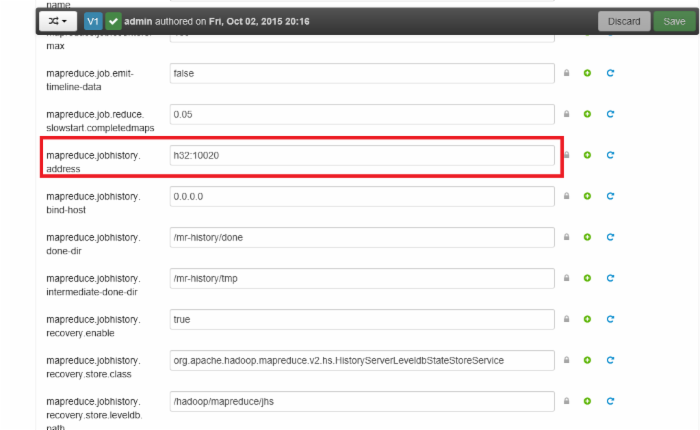
选中MapReduce2->Config,圈中的就是MapReduce地址
五:配置
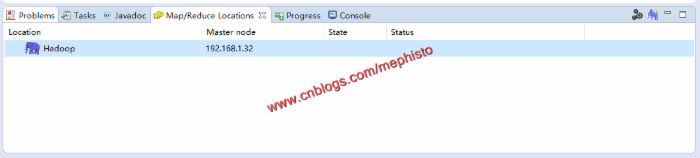
打开Eclipse插件,右键新建一个Hadoop location
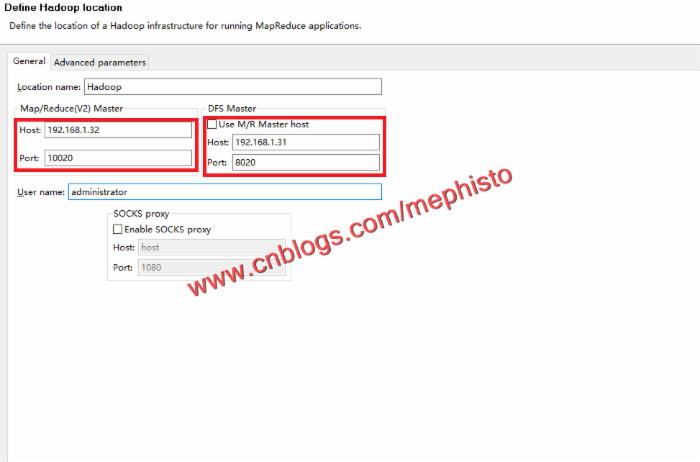
编辑圈中的地方。
六:连接
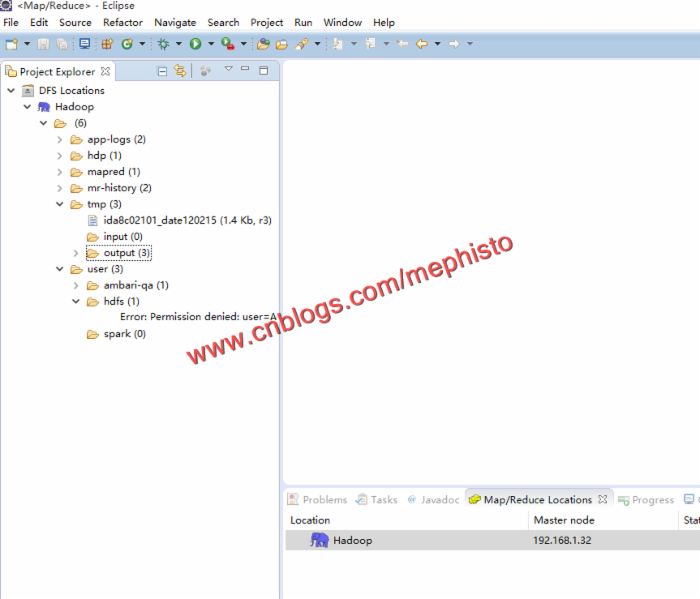
双击DFS Locations_>Hadoop
就可以看到如下的目录结构
新建插件项目
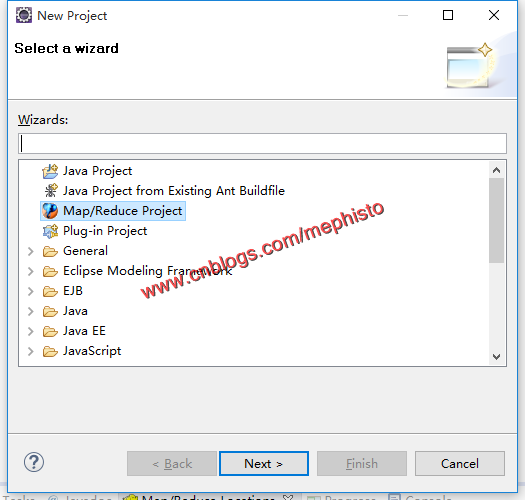
一:新建项目
打开File->New Project->Map/Reduce Project
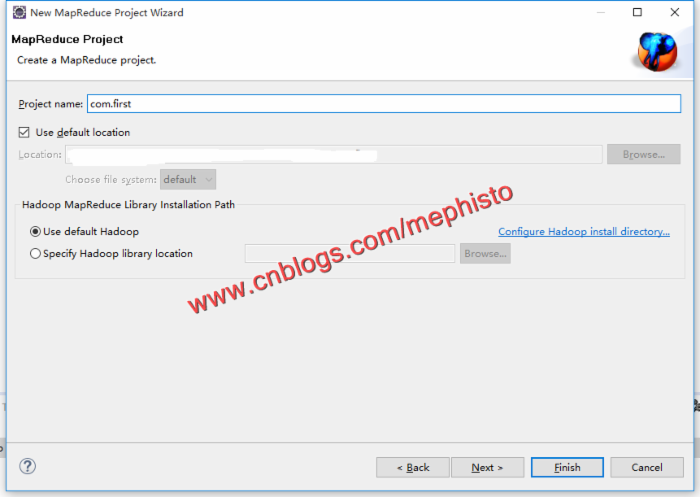
下一步,输入项目名称。
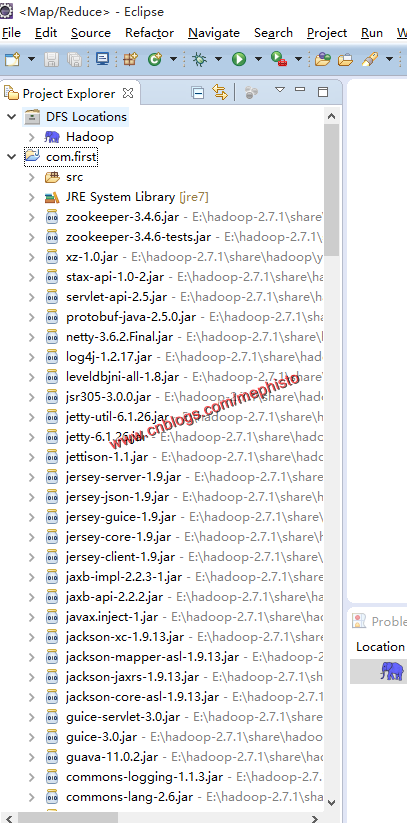
点击完成,我们可以看到一个简易的Map/Reduce项目完成。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。
系列索引
【源】从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

