基于Hadoop集群的大规模分布式深度学习

英文原文: Large Scale Distributed Deep Learning on Hadoop Clusters
前言
在过去的十年里,Yahoo 一直持续投资建设和扩展 Apache Hadoop 集群,到目前为止共有超过 4 万台服务器和 600PB 数据分布在 19 个集群上。正如在 2015 Hadoop 峰会上介绍的,我们在自己的服务器上开发了可扩展的机器学习算法,用于分类、排序和计算词向量。目前,Hadoop 集群已成为 Yahoo 大规模机器学习的首选平台。

深度学习(Deep Learning, DL)是雅虎很多产品的核心技术需求。在 2015 RE.WORK 深度学习峰会上,Yahoo Flickr 团队( Simon Osindero 和 Pierre Garrigues )阐述了深度学习如何被应用于场景检测、物体识别和计算美学。机器学习帮助 Flickr 自动完成给用户图片打标签,使得 Flickr 终端用户能够方便的管理和查找图片。
为使深度学习技术惠及更多的 Yahoo 产品,最近我们把此项技术迁移到自己的 Hadoop 集群上。基于 Hadoop 的深度学习主要有这些优点:
- 深度学习过程可以直接在我们存储数据的 Hadoop 集群上完成。避免了数据在 Hadoop 集群和深度学习集群之间的不必要传输。
- 深度学习可以被定义为一流的 Apache Oozie 工作流,使用 Hadoop 进行数据处理和 Spark 管道进行机器学习。
- YARN 支持深度学习。一个集群上可以同时进行多项深度学习实验。与传统方法相比,新方法事半功倍。在过去,我们有些项目组靠“记事本”手工调度 GPU 资源,这是很痛苦的,而且只对少数用户有效。
基于 Hadoop 的深度学习是深度学习的一个创新方法。业界现有的方法要求使用专用的集群,而基于 Hadoop 的深度学习不仅能达到专用集群的效果,还额外多出上述几项优点。
增强 Hadoop 集群
为了支持深度学习,我们在 Hadoop 集群上添加 GPU 节点。每个节点有 4 块 Nvidia Tesla K80 运算卡 ,每块卡配置 2 个 GK210 GPU。这些节点的处理能力是我们 Hadoop 集群所使用的传统 CPU 的 10 倍。
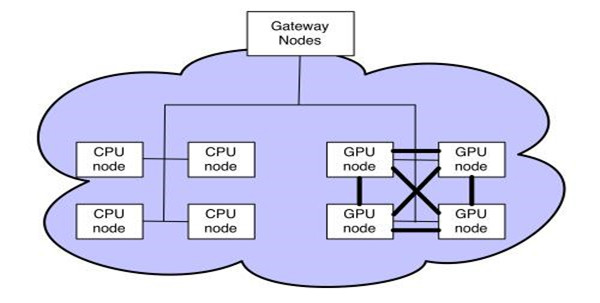
在 Hadoop 集群上,GPU 节点有两个独立网络接口,Ethernet 和 Infiniband。Ethernet 作为对外通信的主要接口,Infiniband 在 GPU 之间提供 10 倍以上速率的数据传输,并且支持通过 RDMA 直接访问 GPU 内存。
通过利用 YARN 最近推出的节点标签功能( YARN-796 ),我们可以在 jobs 中声明容器是在 CPU 还是 GPU 节点加载。GPU 节点的容器能使用 Infiniband 以极高的速度交换数据。
分布式深度学习:Caffe-on-Spark
为了在这些强化的 Hadoop 集群上支持深度学习,我们基于开源软件库开发了一套完整的分布式计算工具,它们是 Apache Spark 和 Caffe 。我们可以利用下面的命令行向集群 GPU 节点提交深度学习计算任务。
spark-submit –master yarn –deploy-mode cluster
–files solver.prototxt, net.prototxt
–num-executors <# of EXECUTORS>
–archives caffe_on_grid.tgz
–conf spark.executorEnv.LD_LIBRARY_PATH=“./caffe_on_grid.tgz/lib64”
–class com.yahoo.ml.CaffeOnSpark caffe-on-spark-1.0-jar-with-dependencies.jar
-devices <# of GPUs PER EXECUTOR>
-conf solver.prototxt
-input hdfs://<TRAINING FILE>
-model hdfs://<MODEL FILE>
在上述命令行中,用户可以指定使用的 Spark executor 个数(–num-executors),每个 executor 分配的 GPU 个数(-devices),HDFS 上存放训练数据的路径,以及模型在 HDFS 上的存储路径。用户使用标准 Caffe 配置文件来确定 Caffe 算法和深度网络的拓扑结构(ex.solver.prototxt, net.prototxt)。
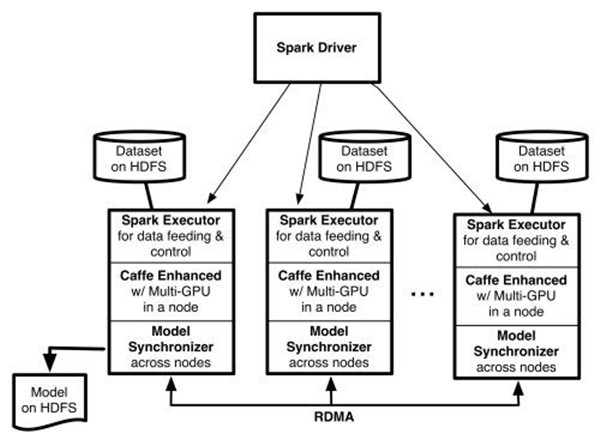
如上图所示,在 YARN 的 Spark 加载了一些 executor。每个 executor 分配到一个基于 HDFS 的训练数据分区,然后开启多个基于 Caffe 的训练线程。每个训练线程由一个特定的 GPU 处理。使用反向传播算法处理完一批训练样本后,这些训练线程之间交换模型参数的梯度值。这些梯度值在多台服务器的 GPU 之间以 MPI Allreduce 形式进行交换。我们升级了 Caffe,以支持在一台服务器上使用多个 GPU,并以 RDMA 协议来同步 DL 模型。
Caffe-on-Spark 让我们集 Caffe 与 Spark 二者之长处,将其应用于大规模深度学习,使深度学习任务如其它 Spark 应用一样易于操作。集群中的多个 GPU 被用于训练基于 HDFS 大规模数据集的模型。
性能测试
Caffe-on-Spark 支持(a)多个 GPU,(b)多台机器进行深度学习。为了体现我们方法的优势,我们在 ImageNet 2012 数据集上进行性能对比测试。
首先,我们在单个 Spark executor 中分别使用 1 个、2 个、4 个、8 个 GPU 对 AlexNet 数据集进行深度学习。如下图所示,训练时间随着 GPU 数量增加而缩短。当 GPU 数量为 4 个时,我们仅花费单个 GPU 所需时间的 15/43=35% 就能取得 50% 的准确率。所有上述执行过程的批大小均为 256。使用 8 个 GPU 相比 4 个 GPU 性能并没有显著提升。因为每个 GPU 处理的数据量太少而无法充分地利用硬件性能。

随后,我们又在 GoogLeNet 数据集上进行了分布式性能对比测试,该测试比 AlexNet 的测试更深,且使用了更多的卷积运算,因此需要更强的计算能力。在每一轮运算中,我们给每个 GPU 分配的批大小为 32,当有n个 GPU 参与运算时,32n 是最有效的大小。我们的分布式算法旨在生成模型并且达到和单个 GPU 相当的准确率。使用 4 台服务器(4x8 个 GPU)训练,能在 10 小时内使 top-5 准确率超过 80%(20% 的误差)。注意 1 个 GPU 训练 40 小时后也只能达到 60% 的 top-5 准确率(40% 的误差)。

GoogLeNet 规模随着 GPU 数量的增加而扩大。对于 60% 的 top-5 准确率(40% 的误差),8 个 GPU 能比 1 个 GPU 提速 680%。下表显示了达到 70% 和 80% top-5 准确率的速度提升幅度。如果我们仔细调整批数据大小(并不是将批大小都设为 32n),速度还能提升更多。
开源资源
秉承 Yahoo 的开源承诺,我们向 github.com/BVLC/caffe 上传了一部分代码:
#2114 …允许 Caffe 在单台计算机上使用多个 GPU
#1148 …支持计算机之间以 RDMA 协议传输数据
#2386 …提升了 Caffe 的数据管道和预取技术
#2395 …增加计时信息
#2402 …更改 Caffe 的 IO 依赖为可选
#2397 …重构 Caffe 的解法代码
在接下来几周的后续文章中,我们将分享 Caffe-on-Spark 的具体设计和实现细节。如果社区有足够的兴趣,我们也许会开源实现的代码。请将您的想法告知我们 bigdata@yahoo-inc.com
总结
这篇文章初步描述了将 Apache Hadoop 生态系统和深度学习集成在同一个异构(GPU+CPU)集群的做法。早期的性能对比结果使我们倍受鼓舞,并计划在 Hadoop、Spark 和 Caffe 投入更多精力来使得深度学习在我们的集群上更加有效。我们期待和开源社区的朋友们在相关领域的并肩作战。
译者/赵屹华审校/刘帝伟、朱正贵、李子健责编/周建丁
译者简介:赵屹华,搜狗算法工程师,关注大数据和机器学习。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

