解读Etsy如何利用热力学帮你找到适合“极客”的东西
Etsy的用户喜爱这个市集,货品丰富且数量繁多。不过对于那些自己也不清楚要找什么的用户来说,东西太多太杂反而更让人困扰。7月份,我们更新了UI界面,将搜索的热门品类放在顶级分类中。针对类似“礼物”这样的查询,用户都能获得相关的搜索结果了。会进行这样宽泛搜索的用户通常并不确定自己具体要找什么东西,所以很有可能空手而归。我们的团队主管Gio上个月发布了一篇博文,描述了我们修改UI的动机与过程,对了解这个项目的背景会有所帮助。本文着重于描述在对“泛类”进行分类查询的启发式搜索上,我们是如何进行开发与迭代的。
下图是Etsy网站针对“极客礼品”的一个搜索:

量化“宽泛”
在对团队以外的人描述工作内容时,总会被质疑:如何利用机器学习技术从代码上来确定哪类查询属于宽泛?尽管我们可以利用类似“点击”这样复杂的线下信号或者购买行为,来学习哪类查询应当触发分类界面,但实际上却是基于对单次访问的完整评估统计,其中只运用到针对搜索结果集的基本统计。
坚持较为简单的标准有几大好处:通过避开了针对具体商品查询的行为信号,我们的方法一开始就适用于所有语言和长尾查询,调试时性能很高也相当简单,也很稳定并易于维护,同时对于外部的依赖或者移动部件也很少。下文会解释具体的工作方式,并在过程中对本文标题进行论证。
下面用“极客”作为泛类查询的案例,在搜索什么物品上,这个词提供的信息甚少:珠宝是搜索“极客”的顶级分类,不过顶级分类中还有多个其他分类。
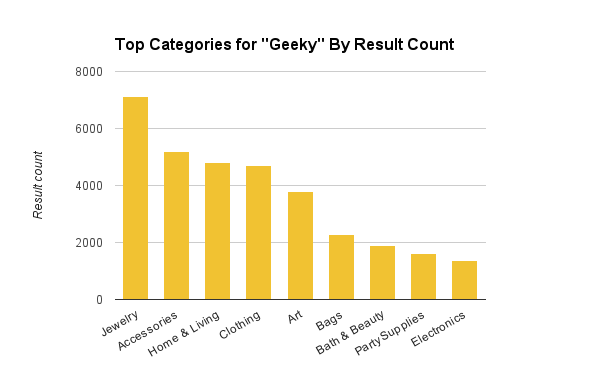
根据搜索结果统计,搜索“极客”的顶级分类
对照“极客杯子”搜索结果的类型分布——可以想见结果会集中在家居分类。
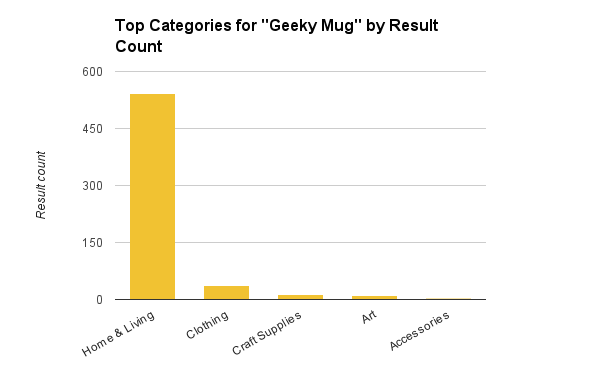
根据搜索结果统计,“极客杯子”的顶级分类
简单来讲,我们使用的算法是衡量查询所返回的商品品类广度的。搜索“极客”得到的分布结果显示了用户可能找到所需物品的顶级分类涵盖之广,从元素周期表图样的领结到饰有π图案的杯子都有涉猎。而搜索“极客杯子”的结果则集中在一个分类中,不应触发分类界面。

查询“极客”显示出的分类
做做算术题
为了量化这些商品的“广度”,我们从计算查询所返回的各个顶级分类结果的数量开始,得到了商品在各个分类中的概率。鉴于结果中有20%属于珠宝分类,15%属于配件分类,那么珠宝和配件分类的概率值分别就是两成与一点五成。我们将这些值代入香农公式(即熵公式):
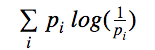
香农公式
根据公式可以得出概率分布的紊乱程度。本质上相当于计算一个物理系统的热力学熵,概念模型十分类似。
为了达到我们的目的,以rt作为结果总值,ri作为分类i的值。下面方程式的概率将会是ri/rt,而搜索结果集的类型分布熵可以表达为:
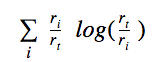
搜索结果集的熵
这样一来,无需线下信号,我们就可以确定何时该显示多个分类了。这并不代表我们在开发过程中完全不使用数据。为了确定显示多个分类的阀值,我们查看了大量查询样本,并确立了相当自由的分隔判断(即使用低阀值)。一旦从给真实用户展示新界面的AB实验中得到结果,我们希望看到低阀值查询方式对用户行为的影响,并根据数字对边缘值进行优化。不过这是个一次性的分析,由于网站分类变化很少,我们期望阀值也在长时间内维持静态。
再次升级
宽泛的查询在顶级分类中未必有很高的熵。毫无疑问,针对“极客珠宝”的搜索结果基本都在珠宝分类,但还返回了其他一些分类的结果。我们希望指引用户进入更具体的子类,比如耳饰项链这样的。因此我们引入了第二轮针对查询的熵计算,这一轮并不像顶级分类那么宽泛。过程如下:如果结果集在顶级分类中没有触发很高的熵,我们确定结果最多子类的熵值(即子分类的熵),并在结果值超过熵限的情况下显示那些子分类。
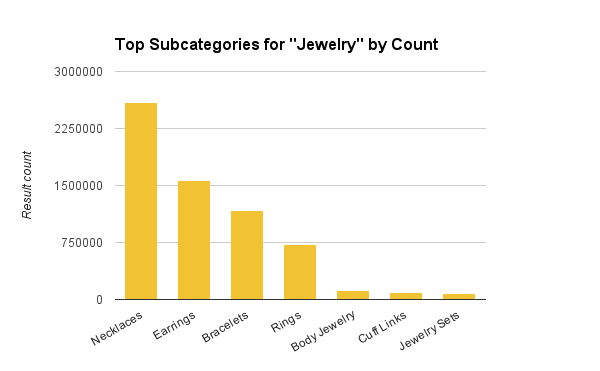
“珠宝”的顶级子分类
上图显示查询“珠宝”的结果中,珠宝顶级分类之下不同子类的分布情况。这一方法让我们得以在类似案例中深入顶级分类,坚持基于分类计数来确定单次访问。

“极客珠宝”的查询结果子类
迭代熵
测试这个办法的时候,类似“鞋子”这样的查询并未如预计那样在鞋子分类获得高熵值,而是在顶级分类中获得了高熵值。

查询“鞋子”的顶级分类
查询“鞋子”所返回的物品很显然涵盖了多项分类,从而触发了顶级分类组出现,尽管在鞋子分类中搜索到的结果明显很多。
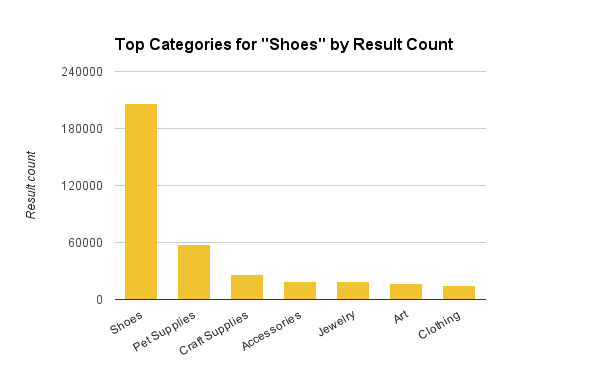
根据结果统计,查询“鞋子”的顶级分类
更普遍的情况下,网站的商品会趋于集中在更热门的分类中。在结果集中很可能出现配件分类物品远多于鞋子分类物品的情况,这是由于前者比后者要超出一个数量级。我们使用熵计算来计算概率时,希望能补偿全球商品分布不均这一情况。
主动搜索所返回的各个分类的商品数量,除以该分类的总商品数,得出的数字就是我们认为的分类与查询之间的亲和关系。尽管查询“鞋子”时,只有不到50%的搜索结果是属于鞋子分类,但鞋子分类100%都是搜索“鞋子”所出现的查询结果,因此该分类的亲和关系要比它结果集的原始分享高出许多。
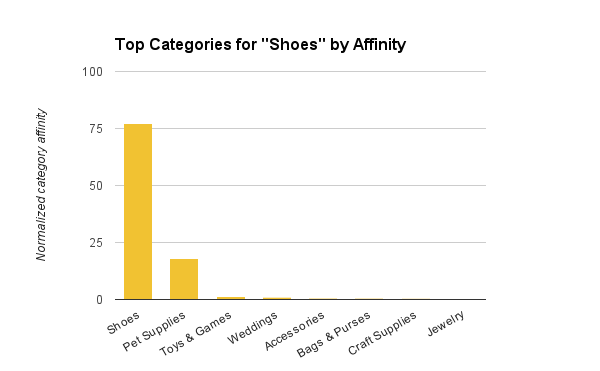
根据亲和力得出的“鞋子”顶级分类
将亲和力值标准化得出一个值,并将这些标准带入第一个迭代中所使用的同一个香农公式。标准化的步骤确保我们能够对大小不同的各搜索结果集的熵值进行对比。用ri代表i分类中主动搜索的商品数量,ti代表该分类中的总商品数量,分类i的亲和力值ai就是简单的ri/ti。用s代表从a0到ai的所有亲和力值的总和,以亲和力为基础的熵值将是:
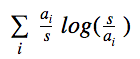
一个搜索结果集的亲和力为基础的熵值
根据贝叶斯定理,原始结果计数值与亲和力值都计算出了相关概率,表明了搜索返回的给定分类清单。区别在于:亲和力公式相当于一个普通品类的事先分布,而原始公式则相当于网站上所能观测到的商品类型分布。通过控制Etsy各分类商品分布的不平衡性,以亲和力为基础的熵值解决了我们的“鞋子”问题,并改进了系统质量。

根据受众改进关于“极客鞋子”的查询
保持简单性
尽管现在的熵迭代比一开始要复杂一些,不过仍旧避开了复杂的线下计算与对外部基础架构的依赖。大数据信号可以相当强大,不过所花费的构建成本对于一个广泛功能的查询分类器来说没什么必要。
在面对用户的层面上,让Etsy搜索功能更好用正是我多年来的夙愿与努力。对搜索者来说,在我们返回热门分类中数以百万的各类商品海洋中寻找想要的东西很令人沮丧。如果再用热力学比喻一下的话,帮助用户找到高熵值的结果集,我们战胜了Etsy搜索的热寂,完全酷毙了。
原文链接: How Etsy Uses Thermodynamics to Help You Search for “Geeky” (译者/孙薇 审校/赵屹华、朱正贵、李子健 责编/周建丁)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

