拓扑数据分析与机器学习的相互促进
【编者按】 拓扑数据分析(TDA)和机器学习(ML)的区别与联系让不熟悉TDA的人扑朔迷离,本文通过两个定义,解释了TDA和ML的不同,以及TDA和ML如何相互促进,为何会相互促进,并通过一个设备故障分析的案例(5000个样本,复杂度适中,48个连续特征)来进行证明。
对拓扑数据分析(TDA)不熟悉的人,经常会问及一些类似的问题,如“机器学习和TDA两者之间的区别?”,这种问题的确难以回答,部分原因在于你眼中的机器学习(ML)是什么。
下面是维基百科关于机器学习的说明:
机器学习研究算法学习和构造,能从数据中进行学习并做出预测。这种算法通过从输入实例中建立模型,目的是根据数据做出预测或决策,而不是严格地遵循静态程序指令。
大多数人可能会认为TDA是机器学习的一种形式,但我觉得,在这些领域工作的人可能都不会赞成这一说法。
机器学习的具体实例比任何一个TDA的例子更像机器学习。同样,TDA的实例比任何一个机器学习的例子看起来更像是TDA。
为了解释TDA和ML两者的不同,更重要的是证明TDA和ML是如何相互促进以及为何会相互促进,我将给出两个非常简单的定义,然后用一个真实的实例进行说明。
- 定义 ML :假定一个数据参数模型,并根据数据来学习模型参数的任意方法。
- 定义TDA:只把数据点间的“相似性”概念用来构建数据模型的任意方法。
在这种观点中,ML模型更加具体和详细,而且模型的成功取决于它对未知数据的拟合程度。它的优势是,当数据能很好的拟合模型时,其结果尤为突出——几乎能够完美的理解那些有明显噪声的数据。
TDA的优点是它的通用性。
对于TDA,任何相似性概念都可以拿来使用。相反,对于ML,你需要一个(或更多)强化的相似性概念,与其它任何方法一起发挥作用。
例如,给你一长串的名字,你是无法根据它来预测出身高和体重。你需要更多的信息。
主要因素是拓扑算法对小误差的容忍度很大——即便你的相似性概念在某种程度上存在缺陷,只要它存在“几分相似”,TDA算法一般就会产生一些有用的东西。
TDA方法的通用性还有另一个优于ML技术的地方, 当ML方法拟合效果很好的时候,TDA方法仍然有效——即ML方法经常创建详细的能生成相似性概念的内部状态,使TDA和ML能够更深层次的洞悉数据 。
听起来还不错,但是这通常会走向极端(或者如果你觉得小误差的容忍度偏低,或是模糊度不够),这意味着一切都有可能发生。
那么,来举个特例吧。
随机森林分类器是一个组合学习方法,在训练过程中,建立大量的决策树并在这些“森林”(决策树集合)的基础上使用“多数规则”对非训练数据进行分类。
尽管建立树的过程相当有趣并且也很灵活,但它们没有相关的细节。对于随机森林,你只要记住,它通过把一系列决策树的集合应用到已知数据点上,然后返回一系列的“叶节点”(决策树中,到输入"下落"的叶子)。
在正常的操作下,每棵树的每个叶子节点都有一个相关的类别C,可以解释为“当一个数据点位于树的该节点时,在很大程度上它就属于该类别C”。随机森林分类器通过从每棵树上统计“叶节点类别投票总数”来选出胜出者。尽管在大规模的数据类型上高度有效,但该过程会丢掉大量的信息。
如果你关心的是对数据类别的最佳猜测,那么你不会想看到额外的信息,但有时候你会需要更多的信息。这种“无关的”信息可以转换成一个距离函数,通过把两个数据点之间的距离定义为它们各自“叶节点”之间差异的倍数。
两个数据点的距离函数是一个很好的度量(事实上,是在转换后的数据集上的汉明距离),而且这样我们可以把TDA应用到上面。
例如,让我们来看看从下面链接的样本中随机选取的5000个样本点: https://archive.ics.uci.edu/ml/datasets/Dataset+for+Sensorless+Drive+Diagnosis .
该数据集复杂度适中,有48个连续特征,这些特征似乎是硬盘驱动中无法解释的电流信号。数据还包括一个类别列,它有11个可能的取值,描述的是光盘驱动组件不同的状况(故障模式,也许吧?)。很明显可以在特征列上计算欧几里得距离,然后通过类来给图形着色。由于我们对于特征项一无所知,所以首先要尝试的事情就是查看邻近晶状体情况。其结果是一个普通的斑点。

这让人有些失望!
接着,使用一些内部的调试功能,我看到邻近晶状体的一个散点图,我知道为什么如此糟糕了——它看起来像是一颗圣诞树。
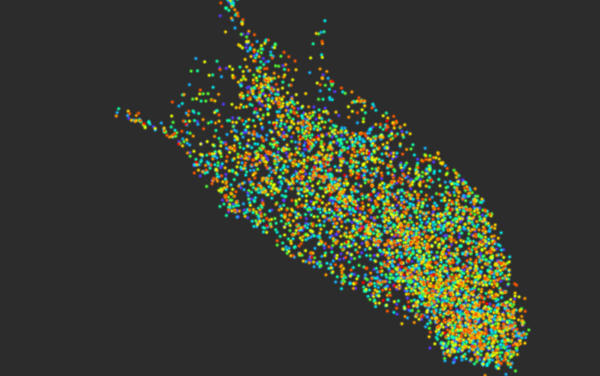
很显然,在欧氏度量中没有类的定位。
然而,如果你在数据集上建立一个随机森林,分类器会有一个非常小的out-of-bag误差,这强烈的表明了分类器性能的可靠性。
因此,我尝试使用随机森林的汉明距离来作图,这种度量下的邻近晶状体如下图所示:

这看起来很不错。只要确定我们也看到了邻近晶状体的散点图就行,上图的结果表明:

很明显,从线图和散点图可以看出,随机森林“看”复杂结构的能力要低于分类的标准水平,并被TDA给证实了。原因就是 RF没有充分使用“不相关的”数据——而TDA充分的利用了这些数据并且从这些信息中得到了大量的好处 。
然而,一些人可能会说,这种结构是虚构的——这也许是我们在系统的某处使用算法人工生成的?在这种数据集下,我们不能真正识别它,因为对于该类别的其它信息我们一无所知。
不过,基于设备老化时收集的数据,我们在消费者数据上使用随机森林来度量分析成千上万的复杂设备可能的故障模式。类别是基于设备因为不同的原因(并不是所有的原因都是由故障导致的)而返厂的事后分析完成的。
在这个例子中,我们发现随机森林度量标准在故障识别层面做的很好,并且我们得到的图片特征和上面这些也相似。更重要的是,我们发现在给定的故障模式中的特定组,有时有不同的原因。
在这些情况下得出的结论是:我们在使用TDA和RF时没有做进一步的空间分解,这些原因可能会更难发现。
我们刚才看到的例子表明,TDA与机器学习可以一起使用,并且得到的效果比使用单个技术更好。
这就是我们所说的 ML&TDA :同时使用更好 。
原文链接: How TDA and Machine Learning Enhance Each Other (译者/刘帝伟 审校/刘翔宇、朱正贵、李子健 责编/仲浩)
译者简介: 刘帝伟,中南大学软件学院在读研究生,关注机器学习、数据挖掘及生物信息领域。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

