【R语言进行数据挖掘】决策树和随机森林
1、使用包party建立决策树
这一节学习使用包party里面的函数ctree()为数据集iris建立一个决策树。属性Sepal.Length(萼片长度)、Sepal.Width(萼片宽度)、Petal.Length(花瓣长度)以及Petal.Width(花瓣宽度)被用来预测鸢尾花的Species(种类)。在这个包里面,函数ctree()建立了一个决策树,predict()预测另外一个数据集。在建立模型之前,iris(鸢尾花)数据集被分为两个子集:训练集(70%)和测试集(30%)。使用随机种子设置固定的随机数,可以使得随机选取的数据是可重复利用的。
观察鸢尾花数据集的结构
str(iris)
设置随机数起点为1234
set.seed(1234)
使用sample函数抽取样本,将数据集中观测值分为两个子集
ind <- sample(2, nrow(iris), replace=TRUE, prob=c(0.7, 0.3))
样本的第一部分为训练集
trainData <- iris[ind==1,]
样本的第二部分为测试集
testData <- iris[ind==2,]
加载包party建立一个决策树,并检测预测见过。函数ctree()提供一些参数例如MinSplit, MinBusket, MaxSurrogate 和 MaxDepth用来控制决策树的训练。下面我们将会使用默认的参数设置去建立决策树,至于具体的参数设置可以通过?party查看函数文档。下面的代码中,myFormula公式中的Species(种类)是目标变量,其他变量是独立变量。
library(party)
符号'~'是连接方程或公式左右两边的符号
myFormula <- Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width
建立决策树
iris_ctree <- ctree(myFormula, data=trainData)
检测预测值
table(predict(iris_ctree), trainData$Species)
显示结果如下:

由上图可知,setosa(山鸢尾)40观测值全部正确预测,而versicolor(变色鸢尾)有一个观测值被误判为virginica(维吉尼亚鸢尾),virginica(维吉尼亚鸢尾)有3个观测值被误判为versicolor(变色鸢尾)。
打印决策树
print(iris_ctree)
plot(iris_ctree)
plot(iris_ctree, type="simple")
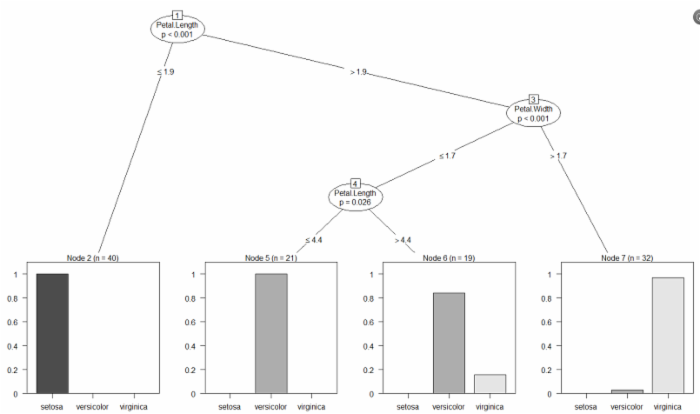
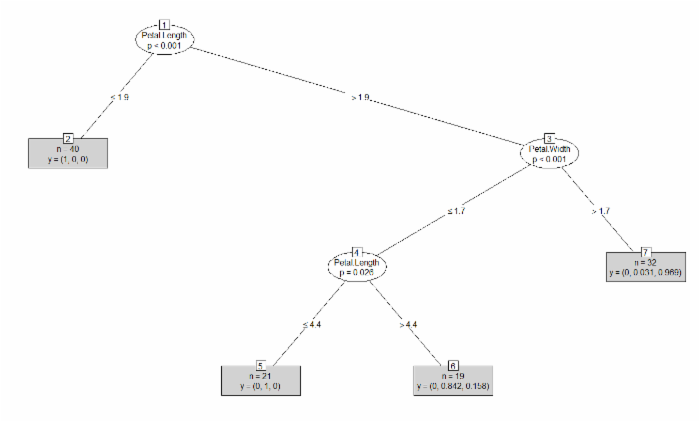
在图1中,每一个叶子的节点的条形图都显示了观测值落入三个品种的概率。在图2中,这些概率以每个叶子结点中的y值表示。例如:结点2里面的标签是“n=40 y=(1,0,0)”,指的是这一类中一共有40个观测值,并且所有的观测值的类别都属于第一类setosa(山鸢尾)。
接下来,需要使用测试集测试决策树。
在测试集上测试决策树
testPred <- predict(iris_ctree, newdata = testData)
table(testPred, testData$Species)
结果如下:

从上图的结果可知,决策树对变色鸢尾和维吉尼亚鸢尾的识别仍然有误判。因此ctree()现在的版本并不能很好的处理部分属性不明确的值,在实例中既有可能被判到左子树,有时候也会被判到右子树上。
2、使用包rpart建立决策树
rpart这个包在本节中被用来在'bodyfat'这个数据集的基础上建立决策树。函数raprt()可以建立一个决策树,并且可以选择最小误差的预测。然后利用该决策树使用predict()预测另外一个数据集。
首先,加载bodyfat这个数据集,并查看它的一些属性。
data("bodyfat", package = "TH.data")
dim(bodyfat)
attributes(bodyfat)
bodyfat[1:5,]
跟第1节一样,将数据集分为训练集和测试集,并根据训练集建立决策树。
set.seed(1234)
ind <- sample(2, nrow(bodyfat), replace=TRUE, prob=c(0.7, 0.3))
bodyfat.train <- bodyfat[ind==1,]
bodyfat.test <- bodyfat[ind==2,]
library(rpart)
编写公式myFormula
myFormula <- DEXfat ~ age + waistcirc + hipcirc + elbowbreadth + kneebreadth
训练决策树
bodyfat_rpart <- rpart(myFormula, data = bodyfat.train,
-
control = rpart.control(minsplit = 10))
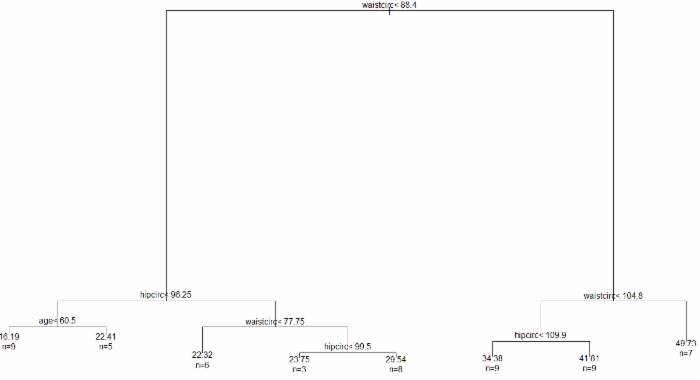
画决策树
plot(bodyfat_rpart)
添加文本标签
text(bodyfat_rpart, use.n=T)
结果如下图所示:
选择预测误差最小值的预测树,从而优化模型。
opt <- which.min(bodyfat_rpart$cptable[,"xerror"])
cp <- bodyfat_rpart$cptable[opt, "CP"]
bodyfat_prune <- prune(bodyfat_rpart, cp = cp)
plot(bodyfat_rpart)
text(bodyfat_rpart, use.n=T)
优化后的决策树如下:
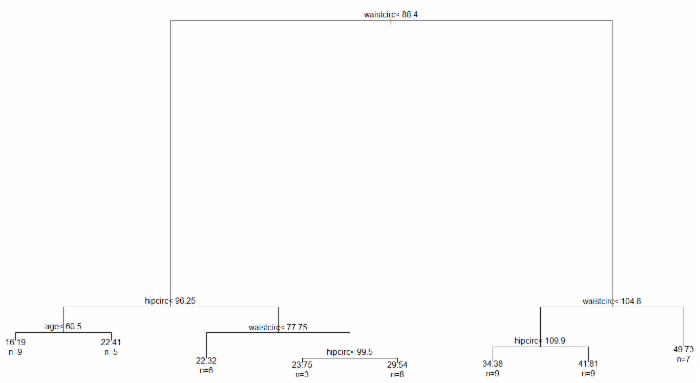
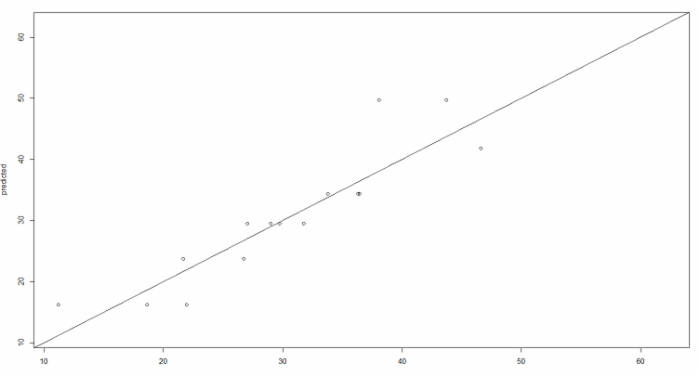
对比结果就会发现,优化模型后,就是将hipcirc<99.5这个分层给去掉了,也许是因为这个分层没有必要,那么大家可以思考一下选择预测误差最小的结果的决策树的分层反而没有那么细。之后,优化后的决策树将会用来预测,预测的结果会与实际的值进行对比。下面的代码中,使用函数abline()绘制一条斜线。一个好的模型的预测值应该是约接近真实值越好,也就是说大部分的点应该落在斜线上面或者在斜线附近。
根据测试集预测
DEXfat_pred <- predict(bodyfat_prune, newdata=bodyfat.test)
预测值的极值
xlim <- range(bodyfat$DEXfat)plot(DEXfat_pred ~ DEXfat, data=bodyfat.test, xlab="Observed",
-
ylab="Predicted", ylim=xlim, xlim=xlim)
abline(a=0, b=1)
绘制结果如下:
3、随机森林
我们使用包randomForest并利用鸢尾花数据建立一个预测模型。包里面的randomForest()函数有两点不足:第一,它不能处理缺失值,使得用户必须在使用该函数之前填补这些缺失值;第二,每个分类属性的最大数量不能超过32个,如果属性超过32个,那么在使用randomForest()之前那些属性必须被转化。
也可以通过另外一个包'cforest'建立随机森林,并且这个包里面的函数并不受属性的最大数量约束,尽管如此,高维的分类属性会使得它在建立随机森林的时候消耗大量的内存和时间。
ind <- sample(2, nrow(iris), replace=TRUE, prob=c(0.7, 0.3))
trainData <- iris[ind==1,]
testData <- iris[ind==2,]
library(randomForest)
Species ~ .指的是Species与其他所有属性之间的等式
rf <- randomForest(Species ~ ., data=trainData, ntree=100, proximity=TRUE)
table(predict(rf), trainData$Species)
结果如下:

由上图的结果可知,即使在决策树中,仍然有误差,第二类和第三类话仍然会被误判,可以通过输入print(rf)知道误判率为2.88%,也可以通过输入plot(rf)绘制每一棵树的误判率的图。最后,在测试集上测试训练集上建立的随机森林,并使用table()和margin()函数检测预测结果。
irisPred <- predict(rf, newdata=testData)table(irisPred, testData$Species)
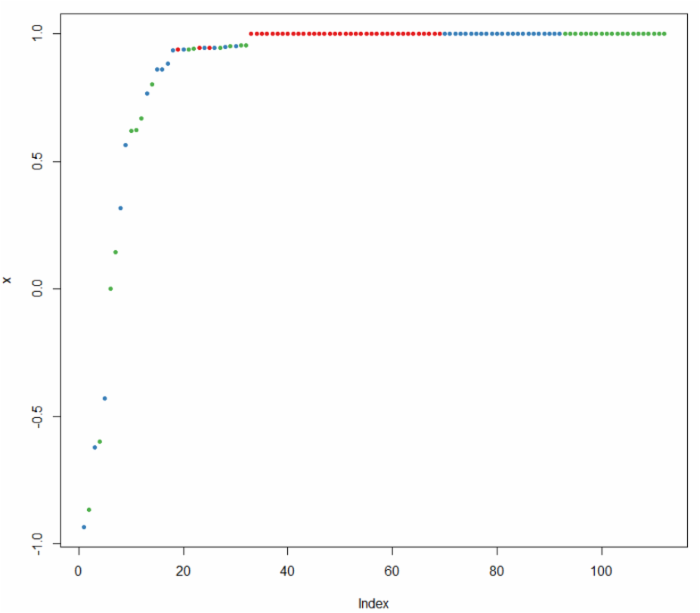
绘制每一个观测值被判断正确的概率图
plot(margin(rf, testData$Species))显示结果如下:

正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

