针对 Linux on z Systems 的内联汇编基础知识
简介
2015 年发布的 IBM XL C/C++ for Linux on z Systems 编译器 1.1 版,支持将用户的汇编器指令直接合并到 C/C++ 程序中(内联汇编)。这使得高级用户能够更灵活地在芯片级别访问指令。借助内联汇编,软件工程师能够为 C/C++ 程序中最注重性能的部分编写汇编器代码。这可以进一步加速应用程序的执行,充分发挥程序员的独创性。
本文的目的是介绍 IBM XL for Linux on z Systems 编译器所支持的内联汇编的基础知识。高级特性将在文章 针对 Linux on z Systems 的内联汇编高级特性 中讨论。本文的内容在涉及一般性寄存器的汇编器指令范围内。矢量寄存器和浮点寄存器将作为单独的一期文章进行介绍。本文的目标读者是对超越 Linux on z Systems 编译器所提供的优化程度,调优其高性能应用程序中最注重性能的代码部分感兴趣的高级软件工程师。
回页首
汇编器指令和内联汇编语句
内联汇编语句依赖于平台
每个内联汇编语句封装了 0 条或更多条汇编指令。汇编器指令是硬件级指令,是硬件架构专用的。不同平台上的指令可能完全不同,甚至在它们执行类似性质的操作时也是如此。例如,一个在 IBM Power Architecture® 上的两个寄存器的内容中执行的算术加指令会接受 R1、R2 和 R3 3 个操作数。
caxo. R3, R2, R1
此运算会将存储在寄存器 R1 和 R2 中的值相加,然后将结果保存到寄存器 R3。它还会更新条件寄存器的内容和定点异常寄存器中的运算状态。
但是,在 IBM z Systems 上,相应的指令仅接受两个操作数,如下所示:
AR R2, R1
此指令将存储在寄存器 R1 中的值与寄存器 R2 中的值相加,然后将结果存回到寄存器 R2 中。该指令更新程序状态字 (PSW) 中有关该运算和溢出的状态的 4 位条件代码值。z Systems 处理器上没有条件寄存器。
请注意,如果安装了不同的操作数工具,z Systems 上的 ARK 和 AGRK 指令会接受 3 个操作数。
要确保应用程序的可移植性,内联汇编语句中的代码节必须受到特定于 z Systems 的正确宏的保护。IBM XL 编译器定义的所有宏的列表,可通过使用 –qshowmacros –P 选项编译 C 代码的任何部分来获得。这会将所有宏定义发出到经过预处理的输出中。
构造一个内联汇编语句
内联汇编是用户嵌入到 C/C++ 程序中的语句,用于告诉编译器将指定的汇编器指令内联到生成的代码中。一个内联汇编语句的主要组成部分如下:
- 一个关键字:
asm、__asm或__asm__,用于标记汇编语句的开头 - 一个可选的关键字 volatile ,用于向编译器告知汇编代码块的易变性
- 一个或多个将内联到代码中的汇编器指令,也被称为代码格式字符串
- 一个显示汇编器指令输出的输出操作数列表
- 一个包含汇编指令输入的输入操作数列表
- 一个可选的 clobber 列表,用于向编译器告知寄存器、条件代码和受编译器指令影响的内存的信息
图 1 概括了一个内联汇编语句的主要组成部分。可以在本文后面的章节中找到大多数主要组成部分的详细信息。
图 1. 一个一般化的内联汇编语句

回页首
内联汇编语句的汇编器指令的操作数
一个内联汇编语句包含 0 条或更多汇编器指令。指令的操作数(如果有)必须是文字或参数。当操作数是参数时,它必须来自组合操作数列表。该参数使用 % 符号和它在列表上的位置编号(从 0 开始)来标识。图 2 形象地描绘了如何基于输出和输入操作数列表来标识操作数。
图 2. 组合操作数列表
内联汇编要求与程序剩余部分的所有连接都通过输出和输入操作数列表来建立。不支持不通过操作数列表直接引用外部符号。
回页首
编译器添加指令来支持用户的汇编器指令
用户无需直接操作代码中的汇编器指令,内联汇编特性允许用户在操作数列表中的符号上应用所需的汇编器指令,同时没有安排支持性运算的负担。编译器准备必要的运算来方便汇编器指令的运行。例如,如果想要的运算是将两个变量相加,那么用户可以调用一个相加指令(例如 AR),将这两个变量用作两个操作数。其他任务由编译器处理,比如选择寄存器来执行作业,将值加载到寄存器中,在完成运算后将值存回到内存位置。
在以下清单中,同一个程序有两个版本: example01.c 没有内联汇编语句, example02.c 有一条内联汇编语句。
清单 1. example01.c 是一个没有内联汇编语句的 C 程序
#include <stdio.h> int main () { int array[] = { 1, 2, 3 }; printf ( "array = [ %d, %d, %d ]/n", array[0], array[1], array[2]); printf ( "array = [ %d, %d, %d ]/n", array[0], array[1], array[2]); return 0; } example01.c程序的第 4 和 5 行是等同的。此示例中使用它们作为标记,演示编译器在处理内联汇编语句时完成的准备工作。 example02.c 程序通过在 example01.c 的第 4 和 5 行之间添加一条内联汇编语句来创建。该语句使用一个相加指令 (AR) 来将 array[2] 的值与 array[1] 的值相加。
清单 2. exmple02.c 是一个有一条内联汇编语句的 C 程序
#include <stdio.h> int main () { int array[] = { 1, 2, 3 }; printf ( "array = [ %d, %d, %d ]/n", array[0], array[1], array[2]); asm ("AR %0, %1 /n" :"+r"(array[1]) :"r"(array[2]) ); printf ( "array = [ %d, %d, %d ]/n", array[0], array[1], array[2]); return 0; } AR 指令将它的操作数的和存储到第一个操作数中:它将 %0 (array[1]) 与 %1 (array[2]) 相加,然后将结果存回到 %0 (array[1]) 中。在运行时期间, example02.c 应打印出数组,其中第 2 个元素 (array[1]) 为 5,如清单 3 所示。
清单 3. 运行 example02.c
xlc –o example02 ./example02.c ./example02 array = [ 1, 2, 3] array = [ 1, 5, 3] <- The 2nd element of the array becomes 5, which is the sum of 2+3
将两种情况下生成的汇编代码并排放在一起,可以清楚地看到编译器为支持 example02.c 的第 5 行到第 7 行的内联汇编语句而做了什么。 example01.c 和 example02.c 的汇编文件可通过使用 –S 选项编译程序来生成。
清单 4. 使用 –S 选项创建汇编文件
xlc –c –S example01.c example02.c
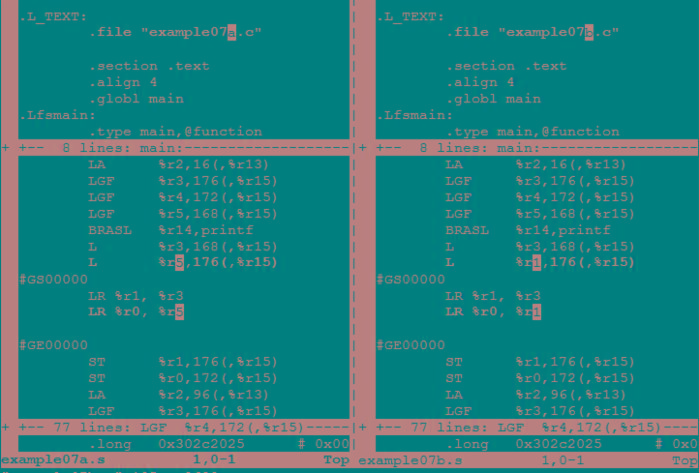
图 3 对比了编译器为程序 example01.c 和 example02.c 生成的汇编文件。在图 3 中可以看到, example01.s (图 3 的左侧)和 example02.s (图 3 的右侧)之间的区别表明,编译器在代码的内联指令 AR %r0, %r1 之前放入了额外的运算。它选择通用寄存器(r0 和 r1),并在调用 AR 指令之前向它们载入合适的值。它还在运算 AR 指令后,将计算的值存回到数组中。需要这些支持性指令,内联汇编语句才能成功运行。
图 3. 编译器添加来支持 AR 的支持性运算
请参阅表 1,了解突出显示的代码段中的运算的详细信息。
表 1. 编译器为内联汇编语句执行的运算
| C 代码 | 汇编器代码 | 运算 |
|---|---|---|
| printf ( "array = [ %d, %d, %d ]/n", array[0], array[1], array[2]); | BRASL %r14,printf | 准备完成,在第 4 行上调用 printf |
| (编译器添加的指令) | L %r1,184(,%r15) | 将 array[2] 的值加载到寄存器 r1 |
| MVC 168(4,%r15),180(%r15) | 将 array[1] 的值复制到位置 r15+168 | |
| L %r0,168(,%r15) | 将 array[1] 的值(现在位于位置 r15+168)加载到 r0 | |
| asm ("AR %0, %1 /n" :"+r"(array[1]) :"r"(array[2]) ); | #GS00000 | 开始内联用户的汇编器指令 |
| AR %r0, %r1 | 内联用户的汇编器指令 | |
| #GE00000 | 结束内联用户的汇编器指令 | |
| (编译器添加的指令) | ST %r0,168(,%r15) | 将 r0 (array[1]) 存回到位置 r15+168 |
| MVC 180(4,%r15),168(%r15) | 将位置 r15+168 上的值复制到位置 r15+180(array[1] 已更新) | |
| printf ( "array = [ %d, %d, %d ]/n", array[0], array[1], array[2]); | LA %r2,16(,%r13) | 准备第二次调用 printf |
| … | … | … |
回页首
约束、修饰符、输出和输入操作数列表,以及 clobber 列表
每个输出操作数都包含一对 约束 和( C/C++ 表达式 )。一个输出操作数必须伴随有一个 修饰符 。一个输入操作数还包含一对 约束 和( C/C++ 表达式 ),但它没有 修饰符 。Clobber 列表会告知编译器,汇编器指令是否会影响输入和输出操作数列表中未列出的任何实体。输出、输入和 clobber 列表可以是空的。在列表上有两个或更多成员时,成员之间用逗号分隔。
约束
约束是一个文字字符串,用于描述它伴随的操作数类型。约束必须与汇编器指令要求的操作数类型相匹配。本文中介绍了一些最常用的约束。在编译器的未来版本中,支持的约束可能会增加。请参阅编译器手册来了解每款产品的最新、全面的支持约束列表。
a、d 和 r 约束用于通用寄存器
约束 a 、 d 和 r 用于要求一个通用寄存器作为操作数的汇编器指令。在 C/C++ 程序中, a 、 r 和 d 约束表示整数符号。例如,在清单 5 中, example03.c 程序的内联汇编语句使用 LPGFR 指令来将一个整数变量的正值加载到自身中,实际上可以将任何整数变量转换为它的绝对值。因为变量 a 是一个整数,而且 LPGFR 指令接受通用寄存器作为它的操作数,所以使用 a 、 d 和 r 中的任何一个作为 LPGFR 的约束都是合法的。
清单 5. example03.c - 对通用寄存器使用 a、d 和 r 约束
#include<stdio.h> int abs_a(int a){ asm (" LPGFR %0, %0/n" :"+a"(a) ); //a constraint return a; } int abs_d(int a){ asm (" LPGFR %0, %0/n" :"+d"(a) ); //d constraint return a; } int abs_r(int a){ asm (" LPGFR %0, %0/n" :"+r"(a) ); //r constraint return a; } int main() { int x = -5; printf( "Absolute value of %d is %d (a constraint)/n", x, abs_a(x) ); printf( "Absolute value of %d is %d (d constraint)/n", x, abs_d(x) ); printf( "Absolute value of %d is %d (r constraint)/n", x, abs_r(x) ); x = 12; printf( "Absolute value of %d is %d (a constraint)/n", x, abs_a(x) ); printf( "Absolute value of %d is %d (d constraint)/n", x, abs_d(x) ); printf( "Absolute value of %d is %d (r constraint)/n", x, abs_r(x) ); } 在执行期间,程序 example03.c 打印 -5 和 12 的绝对值。
备注:在 IBM z/Architecture® 上,r0 无法用于寻址。因为这个原因,约束 “a”(address 的缩写)可用于除 r0 外的所有通用寄存器中。
用于最多 2 字节的常量值的 I、J 和 K 约束
I、J 和 K 约束可用于要求立即操作数的汇编器指令。在 C/C++ 程序中, I 、 J 和 K 约束表示最多 16 位的整数常量或字符常量。例如,在清单 6 中,程序 example04.c 的内联汇编语句在处理 MVI(立即传送)时使用约束 I 、 J 和 K 中的每一个作为 1 字节字符,在处理 AHI(立即添加半字)时用作 2 字节整数。 I 、 J 和 K 的这种用法是合法的,因为 MVI 指令要求 1 字节的立即值,AHI 指令要求 2 字节的常量整数。
清单 6. 具有 I、J 和 K 约束的 example04.c
#include<stdio.h> int main() { char text[]=”ibm”; asm(“MVI %0,%1/n”:”=m”(text[0]):”I”(‘I’)); //I for 1-byte char asm(“MVI %0,%1/n”:”=m”(text[1]):”J”(‘B’)); //J for 1-byte char asm(“MVI %0,%1/n”:”=m”(text[2]):”K”(‘M’)); //K for 1-byte char printf (“Expected IBM , got %s/n”, text); int x = 0; asm(“AHI %0,%1/n”:”+r”(x):”I”(0x1FFF)); //I for 2-byte int asm(“AHI %0,%1/n”:”+r”(x):”J”(0x1FFF)); //J for 2-byte int asm(“AHI %0,%1/n”:”+r”(x):”K”(0x1FFF)); //K for 2-byte int printf (“Expected 0x5FFD, got 0x%X/n”, x); return 0; } 运行时,程序 example04.c 打印出预期的值。
用于最多 4 字节的常量值的 g、i 和 n 约束
g 、 i 和 n 约束可用于要求一个立即操作数(immediate operand)的汇编器指令。在 C/C++ 程序中, g 、 i 和 n 约束可用于表示最多 32 位的整数或字符常量。例如,在清单 7 中,程序 example05.c 的内联汇编语句在处理 MVI 时使用约束 g 、 i 和 n 作为 1 字节字符,在处理 AHI 时将它们用作 2 字节整数,在处理 AFI(立即添加全字)时将它们用作 4 字节整数。约束 g 、 i 和 n 的这种用法是合法的,因为 MVI 指令要求一个 1 字节立即值,AHI 指令要求一个 2 字节常量整数,AFI 指令要求一个 4 字节常量整数。
清单 7. example05.c 演示了 g、i 和 n 常量的用法
#include<stdio.h> int main() { char text[]="xlc"; asm("MVI %0,%1/n":"=m"(text[0]):"i"('X')); //i for 1-byte char asm("MVI %0,%1/n":"=m"(text[1]):"n"('L')); //n for 1-byte char asm("MVI %0,%1/n":"=m"(text[2]):"g"('C')); //g for 1-byte char printf ("Expected XLC, got %s/n", text); int x = 0; asm("AHI %0,%1/n":"+r"(x):"i"(0x1FFF)); //i for 2-byte int asm("AHI %0,%1/n":"+r"(x):"n"(0x1FFF)); //n for 2-byte int asm("AHI %0,%1/n":"+r"(x):"g"(0x1FFF)); //g for 2-byte int printf ("Expected 0x5FFD, got 0x%X/n", x); x = 0; asm("AFI %0,%1/n":"+r"(x):"i"(0x1FFFFFF)); //i for 4-byte int asm("AFI %0,%1/n":"+r"(x):"n"(0x1FFFFFF)); //n for 4-byte int asm("AFI %0,%1/n":"+r"(x):"g"(0x1FFFFFF)); //g for 4-byte int printf ("Expected 0x5FFFFFD, got 0x%X/n", x); return 0; } 在运行的时候,程序 example05.c 会打印出预期的值。
用于内存约束的 Q、g、m 和 o
Q 、 g m 和 o 约束可用作汇编器指令的内存操作数,它们要求使用 D(X, B) 格式的操作数,其中 D 是置换运算,X 是索引,B 是基址寄存器。在 C/C++ 程序中, Q 、 g m 和 o 约束可用于表示整数符号。例如,在清单 8 中,程序 example06.c 的内联汇编语句在处理 ST(存储)指令时,使用约束 Q 、 g m 和 o 中的每一个作为内存约束来更新数组的元素。
清单 8. example06.c 演示了 Q、g、m 和 o 约束的使用
#include <stdio.h> int main () { int a[] = { 1, 2, 3, 4 }; int b[] = { 10, 20, 30, 40 }; printf ( "a = [ %d, %d, %d, %d ]/n", a[0], a[1], a[2], a[3] ); asm ("ST %1,%0/n":"=Q"(a[0]):"r"(b[0])); //Q as memory constraint asm ("ST %1,%0/n":"=g"(a[1]):"r"(b[1])); //g as memory constraint asm ("ST %1,%0/n":"=m"(a[2]):"r"(b[2])); //m as memory constraint asm ("ST %1,%0/n":"=o"(a[3]):"r"(b[3])); //o as memory constraint printf ( "a = [ %d, %d, %d, %d ]/n", a[0], a[1], a[2], a[3] ); return 0; } 0、1、……、9 是匹配约束
0, 1, …, 9是一些匹配约束,用于告诉编译器向输入操作数和 带编号的 输出操作数分配同样的寄存器。因此,这些匹配约束只能用于输入操作数上。这在一个操作使用前一个操作的结果作为输入时尤为重要。没有匹配约束,编译器就不知道必须为输出和输入操作数使用同一个寄存器。匹配约束的一种示例用法将在文章 针对 Linux on z Systems 的内联汇编高级特性 中详细介绍。
修饰符
修饰符添加来向编译器告知相应操作数的更多信息。在编译器的未来版本中,受支持的修饰符可能会增加。请参阅编译器手册,了解每款产品的修饰符的完整列表。对于当前的 Linux on z Systems 编译器,支持以下修饰符。
- 修饰符 “ = ” 表示操作数对此指令而言是只写的。之前的值已丢弃,被替换为输出数据。
- 修饰符 “ + ” 表示操作数可由指令读取和写入。
- 修饰符 “&” 表示操作数可在指令完成之前使用输入操作数来修改。
- 修饰符 “%” 向指令声明此操作数和后一个操作数将交换。这意味着具有 “%” 修饰符的操作数和下一个操作数的顺序可在生成该指令时安全地交换。相应地,“%” 修饰符不能在最后一个操作数上指定。“%” 修饰符的用途是向编译器提供优化代码的机会。如果编译器可以证明两个操作数的交换顺序会带来一定的性能提升,那么它可以继续处理这些交换的操作数。
“=”(只写)和 “+” (读和写)修饰符很重要。错误地指定这两个修饰符可能导致意外的结果。为了演示这些修饰符的影响,清单 9 中的 C 程序 example08a.c 使用了 “=” 修饰符,而它应该使用 “+” 。
清单 9. 包含错误的输出修饰符的 example08a.c
#include <stdio.h> int main () { int a = 10, b = 200; printf ("INITIAL: a = %d, b = %d/n", a, b ); // Modifier “=” is used for a asm ("AR %0, %1/n" :"=r"(a) :"r"(b)); printf ("RESULT : a = %d, b = %d/n", a, b ); return 0; } 该程序的意图是将变量 a 和 b 的和赋给 a 。它使用了 AR 指令来实现该用途。该 AR 指令将两个操作数中的值相加,然后将和存回到第一个操作数。因此,它在第一个操作数上同时执行了 读 和 写 操作。通过指定 “=” 修饰符,用户会通知编译器第一个操作数(变量 a )只需执行 写 操作。这会误导编译器,example08a.c 代码会被错误地执行。
清单 10. 使用错误的输出修饰符的结果
xlc -o example08a ./example08a.c ./example08a INITIAL: a = 10, b = 200 RESULT : a = 200, b = 200 <- a is supposed to be 210
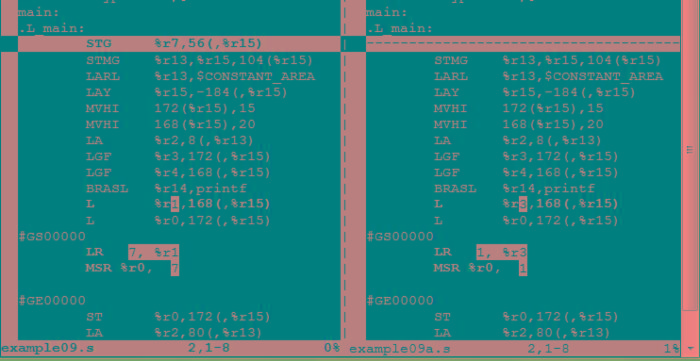
使用正确的修饰符 “+” 将生成正确的结果。图 4 演示了编译器为两种情况生成的代码中的区别,左边是错误的修饰符用法,右边是正确的修饰符用法。
图 4. 使用不同的修饰符时生成的代码中的区别

生成的汇编代码中的区别表明,使用只读修饰符 “=” 确实误导了编译器。在左侧面板中可以看到,编译器在寄存器 r0 上调用 AR 指令 [ AR %r0, %r1 ] 之前,省略了加载到该寄存器的操作 [ L %r0,172(,%r15) ] 。因此,r0 没有使用变量值 a 来参与 AR 指令,而是使用了它刚好包含的值。这就解释了为什么 “=” 修饰符会生成错误的结果。另一方面,使用正确的修饰符 “+” (如右侧面板中所示)将会避免此问题。在使用寄存器 r0 之前,编译器将正确的值加载到其中 [ L %r0,172(,%r15) ] 。
避免使用错误的修饰符的惟一方式是,在使用相应汇编器指令之前,参阅它们的定义。有关的更多细节,可以参阅 z/Architecture 操作原理 (IBM 出版物编号 SA22-7832-10)。还可以在参考资料部分找到官方版本的链接。
输出操作数列表
输出操作数列表包含 0 个或多个输出操作数。在没有输出操作数时,该列表是空的。在这种情况下,输出操作数列表会在内联汇编语句中精简相应的 “:”。列表中的输出操作数用逗号进行分隔。每个操作数包含一个强制修饰符(“+” 或 “=”)、一个约束和一个包含在括号中的 C/C++ 表达式。C/C++ 表达式的值用作内联汇编语句中的汇编器指令的输出操作数。输出操作数必须是可修改的 I 值。
输入操作数列表
输入操作数列表包含 0 个或多个输入操作数。在没有输入操作数时,该列表是空的。在这种情况下,输入操作数列表会在内联汇编语句中精简相应的 “:”。列表中的输入操作数用逗号进行分隔。每个操作数包含一个约束和一个包含在括号中的 C/C++ 表达式。C/C++ 表达式的值用作内联汇编语句中的汇编器指令的输入操作数。
clobber 列表
clobber 列表是 (a) 内存、(b) 条件代码和 (c) 寄存器名称的一个逗号分隔列表。clobber 列表上的所有值都必须放在双引号中并用逗号分隔。clobber 列表的用途是向编译器告知汇编器指令可能在输出操作数列表或输入操作数列表中未列出的实体上进行的更新。
(a) 在 clobber 列表上指定内存
如果属于一个内联汇编语句的汇编器指令可从输入和输出操作数列表中未列出的实体读取或写入, 内存 必须添加到语句的 clobber 列表中。一个示例是访问输入操作数所指向的内存的汇编器指令。这样做是为了确保编译器不会在其他内存引用之间转移汇编器指令,而且在完成汇编语句后使用的数据是有效的。但是,将 内存 添加到 clobber 列表中,会导致许多不必要的重载,并减少硬件预取的优势。出于这个原因, 内存 应添加到 clobber 列表中,并小心预防可避免的性能代偿。
(b) 在 clobber 列表上指定条件代码
Compare 、 Add 和 Subtract 等许多汇编器指令都会更新条件代码。用户应通过将 “ cc ” 添加到 clobber 列表,向编译器告知此事实。有关修改条件代码的汇编器指令的完整列表,请参阅 z/Architecture 操作原理 。
(c) clobber 列表上的寄存器名称
如果汇编器指令使用或更新未在输出和输入操作数列表中列出的寄存器,用户必须在 clobber 列表中列出所有受影响的寄存器。根据来自 clobber 列表的信息,编译器会帮助执行内联汇编语句的运算。如果汇编语句使用了一个未在 clobber 列表中列出的结存期,那么编译器不会知道使用了它。编译器可能将该寄存器用于其他用途。因此,计算的值可能是错误的。
请注意,编译器保留了一些寄存器来执行它自己的运算。不允许将保留的寄存器加入 clobber 列表。表 2 列出了在使用 IBM XL 编译器时一些寄存器的指定用法。
表 2. IBM XL on z Systems 编译器对寄存器的指定用法
| 寄存器名称 | 特殊用法 | 是否可由用户使用? |
|---|---|---|
| r2、r3 | 参数,返回值 | 是,可小心使用 |
| r4、r5、r6 | 参数 | 是,可以小心使用 |
| r13 | 文字池的基址寄存器 | 否 |
| r14 | 返回地址 | 是,可小心使用 |
| r15 | 堆栈指针 | 否 |
clobber 列表的示例用法将在文章 针对 Linux on z Systems 的内联汇编高级特性 中详细介绍。
回页首
结束语
内联汇编为用户提供了一种将汇编器指令直接合并到 C/C++ 程序中的途径。此特性使高级用户能够通过为特定的代码节设计汇编器指令来进一步提高应用程序的性能。IBM XL 编译器执行了一些高度复杂的任务,以便在每个优化级别上优化生成的代码。出于这个原因,要使用内联 ASM 加速性能,需要用户深入理解目标代码的执行。仔细分析对嵌入式编译器指令的性能的影响,再结合全面的规划和测试,是所实现性能提升的前提条件。
本文仅讨论针对 Linux on z Systems 的内联汇编的基础知识。高级特性将在文章 针对 Linux on z Systems 的内联汇编高级特性 中介绍。
回页首
致谢
感谢 Visda Vokhshoori 和 Nha-Vy Tran 在创作本文期间提供的建议。
回页首
参考资料
- 访问 IBM XL C/C++ for Linux on z Systems 产品,了解有关的更多信息。
- 建立联系。加入 RationalC/C++ Cafe 社区。
回页首
参考资料
- z/Architecture 操作原理 ,IBM 出版物编号 SA22-7832-10
- IBM z/Architecture 参考摘要 ,出版物编号 SA22-7871-08
- 用于 XL C/C++ for Linux on z Systems 的内联汇编语句,V1.1 ,2015 年 6 月 1 日检索
- 访问 developerWorksLinux 专区,了解关于 Linux 的更多信息,获取技术文档、how-to 文章、培训、下载、产品信息以及其他资源。
- 加入 developerWorks 中文社区 。查看开发人员推动的博客、论坛、组和维基,并与其他 developerWorks 用户交流。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

