浅谈 Java 字符串
我们先要记住三者的特征:
- String 字符串常量
- StringBuffer 字符串变量(线程安全)
- StringBuilder 字符串变量(非线程安全)
一、定义
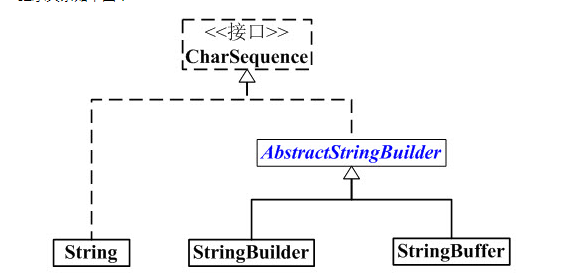
查看 API 会发现,String、StringBuffer、StringBuilder 都实现了 CharSequence 接口,内部都是用一个char数组实现,虽然它们都与字符串相关,但是其处理机制不同。
- String:是不可改变的量,也就是创建后就不能在修改了。
- StringBuffer:是一个可变字符串序列,它与 String 一样,在内存中保存的都是一个有序的字符串序列(char 类型的数组),不同点是 StringBuffer 对象的值都是可变的。
- StringBuilder:与 StringBuffer 类基本相同,都是可变字符换字符串序列,不同点是 StringBuffer 是线程安全的,StringBuilder 是线程不安全的。
使用场景
使用 String 类的场景:在字符串不经常变化的场景中可以使用 String 类,例如常量的声明、少量的变量运算。
使用 StringBuffer 类的场景:在频繁进行字符串运算(如拼接、替换、删除等),并且运行在多线程环境中,则可以考虑使用 StringBuffer,例如 XML 解析、HTTP 参数解析和封装。
使用 StringBuilder 类的场景:在频繁进行字符串运算(如拼接、替换、和删除等),并且运行在单线程的环境中,则可以考虑使用 StringBuilder,如 SQL 语句的拼装、JSON 封装等。
分析
在性能方面,由于 String 类的操作是产生新的 String 对象,而 StringBuilder 和 StringBuffer 只是一个字符数组的扩容而已,所以 String 类的操作要远慢于 StringBuffer 和 StringBuilder。
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于 生成了一个新的 String 对象 , 然后将指针指向新的 String 对象 。所以经常改变内容的字符串最好不要用 String ,因为 每次生成对象都会对系统性能产生影响 ,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的 。
而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。
而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中, String 效率是远要比 StringBuffer 快的:
String S1 = “This is only a" + “ simple" + “ test"; StringBuffer Sb = new StringBuilder(“This is only a").append(“ simple").append(“ test");
你会很惊讶的发现,生成 String S1 对象的速度简直太快了,而这个时候 StringBuffer 居然速度上根本一点都不占优势。其实这是 JVM 的一个把戏,在 JVM 眼里,这个
String S1 = “This is only a" + “ simple" + “test";
其实就是:
String S1 = “This is only a simple test";
所以当然不需要太多的时间了。但大家这里要注意的是,如果你的字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:
String S2 = "This is only a"; String S3 = "simple"; String S4 = "test"; String S1 = S2 +S3 + S4;
这时候 JVM 会规规矩矩的按照原来的方式去做。
又及:
关于 equal 和 ==
== 用于比较两个对象的时候,是来check 是否两个引用指向了同一块内存。

这个输出就是false

这个输出是true
一个特殊情况 :

这是因为:
字符串缓冲池:程序在运行的时候会创建一个字符串缓冲池。
当使用 String s1 = “xyz”; 这样的表达是创建字符串的时候(非new这种方式),程序首先会在这个 String 缓冲池中寻找相同值的对象,
在 String str1 = “xyz”; 中,s1 先被放到了池中,所以在 s2 被创建的时候,程序找到了具有相同值的 str1
并将 s2 引用 s1 所引用的对象 “xyz”
equals()
equals() 是object的方法,默认情况下,它与== 一样,比较的地址。
但是当equal被重载之后,根据设计,equal 会比较对象的value。而这个是java希望有的功能。String 类就重写了这个方法 
结果返回true
总的说,String 有个特点: 如果程序中有多个String对象,都包含相同的字符串序列,那么这些String对象都映射到同一块内存区域,所以两次new String(“hello”)生成的两个实例,虽然是相互独立的,但是对它们使用hashCode()应该是同样的结果。Note: 字符串数组并非这样,只有String是这样。即hashCode对于String,是基于其内容的。
public class StringHashCode { public static void main(String[] args) { //输出结果相同 String[] hellos = "Hello Hello".split(" " ); System.out.println(""+hellos[0].hashCode()); System.out.println(""+hellos[1].hashCode()); //输出结果相同 String a = new String("hello"); String b = new String("hello"); System.out.println(""+a.hashCode()); System.out.println(""+b.hashCode()); } } 结论
String 类是final类,不可以继承。对String类型最好的重用方式是组合 而不是继承。String 有length()方法,数组有length属性
String s = new String(“xyz”); 创建了几个字符串对象?两个对象,一个静态存储区“xyz”, 一个用new创建在堆上的对象。
String 和 StringBuffer,String Builder区别?
在大部分情况下 StringBuffer > String
Java.lang.StringBuffer 是线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。在程序中可将字符串缓冲区安全地用于多线程。而且在必要时可以对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。
StringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。
例如,如果 z 引用一个当前内容是 “start”的字符串缓冲区对象,则此方法调用 z.append(“le”) 会使字符串缓冲区包含 “startle”( 累加); 而 z.insert(4, “le”) 将更改字符串缓冲区,使之包含 “starlet”。
在大部分情况下 StringBuilder > StringBuffer
java.lang.StringBuilder 一个可变的字符序列是 JAVA 5.0 新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步,所以使用场景是单线程。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的使用方法基本相同。
源码
String,StringBuffer,StringBuilder都实现了CharSequence接口。
public class StringHashCode { public static void main(String[] args) { //输出结果相同 String[] hellos = "Hello Hello".split(" " ); System.out.println(""+hellos[0].hashCode()); System.out.println(""+hellos[1].hashCode()); //输出结果相同 String a = new String("hello"); String b = new String("hello"); System.out.println(""+a.hashCode()); System.out.println(""+b.hashCode()); } } String的源码
public final class String{ private final char value[]; // used for character storage private int the hash; // cache the hash code for the string } 成员变量只有两个:
final的char类型数组
int类型的hashcode
构造函数
public String() public String(String original){ this.value = original.value; this.hash = original.hash; } public String(char value[]){ this.value = Arrays.copyOf(value, value.length); } public String(char value[], int offset, int count){ // 判断offset,count,offset+count是否越界之后 this.value = Arrays.copyOfRange(value, offset, offset+count); } 这里用到了一些工具函数
copyOf(source[],length); 从源数组的0位置拷贝length个;
这个函数是用 System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)) 实现的。
copyOfRange(T[] original, int from, int to) 。
构造函数还可以用StringBuffer/StringBuilder类型初始化String,
public String(StringBuffer buffer) { synchronized(buffer) { this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); } } public String(StringBuilder builder) { this.value = Arrays.copyOf(builder.getValue(), builder.length()); } 除了构造方法,String类的方法有很多,
length , isEmpty ,可以通过操作value.length来实现。
charAt(int index) :
通过操作value数组得到。注意先判断index的边界条件
public char charAt(int index) { if ((index < 0) || (index >= value.length)) { throw new StringIndexOutOfBoundsException(index); } return value[index]; } getChars方法
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) { //边界检测 System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); } equals方法,根据语义相等(内容相等,而非指向同一块内存),重新定义了equals
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; } 如果比较的双方指向同一块内存,自然相等;(比较==即可)
如果内容相等,也相等,比较方法如下:
首先anObject得是String类型(用关键字instanceof)
然后再比较长度是否相等;
如果长度相等,则挨个元素进行比较,如果每个都相等,则返回true.
还有现成安全的与StringBuffer内容比较
contentEquals(StringBuffer sb) ,实现是在sb上使用同步。
compareTo() :
如果A大于B,则返回大于0的数;
A小于B,则返回小于0的数;
A=B,则返回0
public int compareTo(String anotherString) { int len1 = value.length; int len2 = anotherString.value.length; int lim = Math.min(len1, len2); char v1[] = value; char v2[] = anotherString.value; int k = 0; while (k < lim) { char c1 = v1[k]; char c2 = v2[k]; if (c1 != c2) { return c1 - c2; } k++; } return len1 - len2; } regionMatches :如果两个字符串的区域都是平等的,
public boolean regionMatches(int toffset, String other, int ooffset, int len) { //判断边界条件 while (len-- > 0) { if (ta[to++] != pa[po++]) { return false; } } } public boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) { while (len-- > 0) { char c1 = ta[to++]; char c2 = pa[po++]; if (c1 == c2) { continue; } if (ignoreCase) { // If characters don't match but case may be ignored, // try converting both characters to uppercase. // If the results match, then the comparison scan should // continue. char u1 = Character.toUpperCase(c1); char u2 = Character.toUpperCase(c2); if (u1 == u2) { continue; } // Unfortunately, conversion to uppercase does not work properly // for the Georgian alphabet, which has strange rules about case // conversion. So we need to make one last check before // exiting. if (Character.toLowerCase(u1) == Character.toLowerCase(u2)) { continue; } } return false; } return true; } startsWith(String prefix, int toffset)
startsWith(String prefix)
endsWith(String suffix)
{ return startsWith(suffix, value.length - suffix.value.length); } substring(int beginIndex,int endIndex)
除了条件判断:
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
字符串连接 concat(String str)
int otherLen = str.length(); if (otherLen == 0) { return this; } int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen); str.getChars(buf, len); return new String(buf, true); 对于StringBuffer和StringBuilderStringBuffer 和 StringBuilder 都是继承于 AbstractStringBuilder, 底层的逻辑(比如append)都包含在这个类中。
public AbstractStringBuilder append(String str) { if (str == null) str = "null"; int len = str.length(); ensureCapacityInternal(count + len);//查看使用空间满足,不满足扩展空间 str.getChars(0, len, value, count);//getChars就是利用native的array copy,性能高效 count += len; return this; } StringBuffer 底层也是 char[], 数组初始化的时候就定下了大小, 如果不断的 append 肯定有超过数组大小的时候,我们是不是定义一个超大容量的数组,太浪费空间了。就像 ArrayList 的实现,采用动态扩展,每次 append 首先检查容量,容量不够就先扩展,然后复制原数组的内容到扩展以后的数组中。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

