Docker源码分析(七):Docker Container网络 (上)
1.前言(什么是Docker Container)
如今,Docker技术大行其道,大家在尝试以及玩转Docker的同时,肯定离不开一个概念,那就是“容器”或者“Docker Container”。那么我们首先从实现的角度来看看“容器”或者“Docker Container”到底为何物。
逐渐熟悉Docker之后,大家肯定会深深得感受到:应用程序在Docker Container内部的部署与运行非常便捷,只要有Dockerfile,应用一键式的部署运行绝对不是天方夜谭; Docker Container内运行的应用程序可以受到资源的控制与隔离,大大满足云计算时代应用的要求。毋庸置疑,Docker的这些特性,传统模式下应用是完全不具备的。然而,这些令人眼前一亮的特性背后,到底是谁在“作祟”,到底是谁可以支撑Docker的这些特性?不知道这个时候,大家是否会联想到强大的Linux内核。
其实,这很大一部分功能都需要归功于Linux内核。那我们就从Linux内核的角度来看看Docker到底为何物,先从Docker Container入手。关于Docker Container,体验过的开发者第一感觉肯定有两点:内部可以跑应用(进程),以及提供隔离的环境。当然,后者肯定也是工业界称之为“容器”的原因之一。
既然Docker Container内部可以运行进程,那么我们先来看Docker Container与进程的关系,或者容器与进程的关系。首先,我提出这样一个问题供大家思考“容器是否可以脱离进程而存在”。换句话说,能否创建一个容器,而这个容器内部没有任何进程。
可以说答案是否定的。既然答案是否定的,那说明不可能先有容器,然后再有进程,那么问题又来了,“容器和进程是一起诞生,还是先有进程再有容器呢?”可以说答案是后者。以下将慢慢阐述其中的原因。
阐述问题“容器是否可以脱离进程而存在”的原因前,相信大家对于以下的一段话不会持有异议:通过Docker创建出的一个Docker Container是一个容器,而这个容器提供了进程组隔离的运行环境。那么问题在于,容器到底是通过何种途径来实现进程组运行环境的“隔离”。这时,就轮到Linux内核技术隆重登场了。
说到运行环境的“隔离”,相信大家肯定对Linux的内核特性namespace和cgroup不会陌生。namespace主要负责命名空间的隔离,而cgroup主要负责资源使用的限制。其实,正是这两个神奇的内核特性联合使用,才保证了Docker Container的“隔离”。那么,namespace和cgroup又和进程有什么关系呢?问题的答案可以用以下的次序来说明:
(1) 父进程通过fork创建子进程时,使用namespace技术,实现子进程与其他进程(包含父进程)的命名空间隔离;
(2) 子进程创建完毕之后,使用cgroup技术来处理子进程,实现进程的资源使用限制;
(3) 系统在子进程所处namespace内部,创建需要的隔离环境,如隔离的网络栈等;
(4) namespace和cgroup两种技术都用上之后,进程所处的“隔离”环境才真正建立,这时“容器”才真正诞生!
从Linux内核的角度分析容器的诞生,精简的流程即如以上4步,而这4个步骤也恰好巧妙的阐述了namespace和cgroup这两种技术和进程的关系,以及进程与容器的关系。进程与容器的关系,自然是:容器不能脱离进程而存在,先有进程,后有容器。然而,大家往往会说到“使用Docker创建Docker Container(容器),然后在容器内部运行进程”。对此,从通俗易懂的角度来讲,这完全可以理解,因为“容器”一词的存在,本身就较为抽象。如果需要更为准确的表述,那么可以是:“使用Docker创建一个进程,为这个进程创建隔离的环境,这样的环境可以称为Docker Container(容器),然后再在容器内部运行用户应用进程。”当然,笔者的本意不是想否定很多人对于Docker Container或者容器的认识,而是希望和读者一起探讨Docker Container底层技术实现的原理。
对于Docker Container或者容器有了更加具体的认识之后,相信大家的眼球肯定会很快定位到namespace和cgroup这两种技术。Linux内核的这两种技术,竟然能起到如此重大的作用,不禁为之赞叹。那么下面我们就从Docker Container实现流程的角度简要介绍这两者。
首先讲述一下namespace在容器创建时的用法,首先从用户创建并启动容器开始。当用户创建并启动容器时,Docker Daemon 会fork出容器中的第一个进程A(暂且称为进程A,也就是Docker Daemon的子进程)。Docker Daemon执行fork时,在clone系统调用阶段会传入5个参数标志CLONE_NEWNS、CLONE_NEWUTS、CLONE_NEWIPC、CLONE_NEWPID和CLONE_NEWNET(目前Docker 1.2.0还没有完全支持user namespace)。Clone系统调用一旦传入了这些参数标志,子进程将不再与父进程共享相同的命名空间(namespace),而是由Linux为其创建新的命名空间(namespace),从而保证子进程与父进程使用隔离的环境。另外,如果子进程A再次fork出子进程B和C,而fork时没有传入相应的namespace参数标志,那么此时子进程B和C将会与A共享同一个命令空间(namespace)。如果Docker Daemon再次创建一个Docker Container,容器内第一个进程为D,而D又fork出子进程E和F,那么这三个进程也会处于另外一个新的namespace。两个容器的namespace均与Docker Daemon所在的namespace不同。Docker关于namespace的简易示意图如下:

图1.1 Docker中namespace示意图
再说起cgroup,大家都知道可以使用cgroup为进程组做资源的控制。与namespace不同的是,cgroup的使用并不是在创建容器内进程时完成的,而是在创建容器内进程之后再使用cgroup,使得容器进程处于资源控制的状态。换言之,cgroup的运用必须要等到容器内第一个进程被真正创建出来之后才能实现。当容器内进程被创建完毕,Docker Daemon可以获知容器内进程的PID信息,随后将该PID放置在cgroup文件系统的指定位置,做相应的资源限制。
可以说Linux内核的namespace和cgroup技术,实现了资源的隔离与限制。那么对于这种隔离与受限的环境,是否还需要配置其他必需的资源呢。这回答案是肯定的,网络栈资源就是在此时为容器添加。当为容器进程创建完隔离的运行环境时,发现容器虽然已经处于一个隔离的网络环境(即新的network namespace),但是进程并没有独立的网络栈可以使用,如独立的网络接口设备等。此时,Docker Daemon会将Docker Container所需要的资源一一为其配备齐全。网络方面,则需要按照用户指定的网络模式,配置Docker Container相应的网络资源。
2.Docker Container网络分析内容安排
Docker Container网络篇将从源码的角度,分析Docker Container从无到有的过程中,Docker Container网络创建的来龙去脉。Docker Container网络创建流程可以简化如下图:

图2.1 Docker Container网络创建流程图
Docker Container网络篇分析的主要内容有以下5部分:
(1) Docker Container的网络模式;
(2) Docker Client配置容器网络;
(3) Docker Daemon创建容器网络流程;
(4) execdriver网络执行流程;
(5) libcontainer实现内核态网络配置。
Docker Container网络创建过程中,networkdriver模块使用并非是重点,故分析内容中不涉及networkdriver。这里不少读者肯定会有疑惑。需要强调的是,networkdriver在Docker中的作用:第一,为Docker Daemon创建网络环境的时候,初始化Docker Daemon的网络环境(详情可以查看《Docker源码分析》系列第六篇),比如创建docker0网桥等;第二,为Docker Container分配IP地址,为Docker Container做端口映射等。而与Docker Container网络创建有关的内容极少,只有在桥接模式下,为Docker Container的网络接口设备分配一个可用IP地址。
本文为《Docker源码分析》系列第七篇——Docker Container网络(上)。
3.Docker Container网络模式
正如在上文提到的,Docker可以为Docker Container创建隔离的网络环境,在隔离的网络环境下,Docker Container独立使用私有网络。相信很多的Docker开发者也是体验过Docker这方面的网络特性。
其实,Docker除了可以为Docker Container创建隔离的网络环境之外,同样有能力为Docker Container创建共享的网络环境。换言之,当开发者需要Docker Container与宿主机或者其他容器网络隔离时,Docker可以满足这样的需求;而当开发者需要Docker Container与宿主机或者其他容器共享网络时,Docker同样可以满足这样的需求。另外,Docker还可以不为Docker Container创建网络环境。
总结Docker Container的网络,可以得出4种不同的模式:bridge桥接模式、host模式、other container模式和none模式。以下初步介绍4中不同的网络模式。
3.1 brdige桥接模式
Docker Container的bridge桥接模式可以说是目前Docker开发者最常使用的网络模式。Brdige桥接模式为Docker Container创建独立的网络栈,保证容器内的进程组使用独立的网络环境,实现容器间、容器与宿主机之间的网络栈隔离。另外,Docker通过宿主机上的网桥(docker0)来连通容器内部的网络栈与宿主机的网络栈,实现容器与宿主机乃至外界的网络通信。
Docker Container的bridge桥接模式可以参考下图:
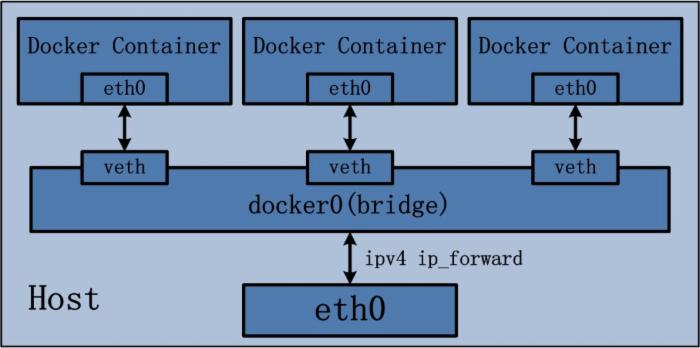
图3.1 Docker Container Bridge桥接模式示意图
Bridge桥接模式的实现步骤主要如下:
(1) Docker Daemon利用veth pair技术,在宿主机上创建两个虚拟网络接口设备,假设为veth0和veth1。而veth pair技术的特性可以保证无论哪一个veth接收到网络报文,都会将报文传输给另一方。
(2) Docker Daemon将veth0附加到Docker Daemon创建的docker0网桥上。保证宿主机的网络报文可以发往veth0;
(3) Docker Daemon将veth1添加到Docker Container所属的namespace下,并被改名为eth0。如此一来,保证宿主机的网络报文若发往veth0,则立即会被eth0接收,实现宿主机到Docker Container网络的联通性;同时,也保证Docker Container单独使用eth0,实现容器网络环境的隔离性。
Bridge桥接模式,从原理上实现了Docker Container到宿主机乃至其他机器的网络连通性。然而,由于宿主机的IP地址与veth pair的 IP地址均不在同一个网段,故仅仅依靠veth pair和namespace的技术,还不足以是宿主机以外的网络主动发现Docker Container的存在。为了使得Docker Container可以让宿主机以外的世界感知到容器内部暴露的服务,Docker采用NAT(Network Address Translation,网络地址转换)的方式,让宿主机以外的世界可以主动将网络报文发送至容器内部。
具体来讲,当Docker Container需要暴露服务时,内部服务必须监听容器IP和端口号port_0,以便外界主动发起访问请求。由于宿主机以外的世界,只知道宿主机eth0的网络地址,而并不知道Docker Container的IP地址,哪怕就算知道Docker Container的IP地址,从二层网络的角度来讲,外界也无法直接通过Docker Container的IP地址访问容器内部应用。因此,Docker使用NAT方法,将容器内部的服务监听的端口与宿主机的某一个端口port_1进行“绑定”。
如此一来,外界访问Docker Container内部服务的流程为:
(1) 外界访问宿主机的IP以及宿主机的端口port_1;
(2) 当宿主机接收到这样的请求之后,由于DNAT规则的存在,会将该请求的目的IP(宿主机eth0的IP)和目的端口port_1进行转换,转换为容器IP和容器的端口port_0;
(3) 由于宿主机认识容器IP,故可以将请求发送给veth pair;
(4) veth pair的veth0将请求发送至容器内部的eth0,最终交给内部服务进行处理。
使用DNAT方法,可以使得Docker宿主机以外的世界主动访问Docker Container内部服务。那么Docker Container如何访问宿主机以外的世界呢。以下简要分析Docker Container访问宿主机以外世界的流程:
(1) Docker Container内部进程获悉宿主机以外服务的IP地址和端口port_2,于是Docker Container发起请求。容器的独立网络环境保证了请求中报文的源IP地址为容器IP(即容器内部eth0),另外Linux内核会自动为进程分配一个可用源端口(假设为port_3);
(2) 请求通过容器内部eth0发送至veth pair的另一端,到达veth0,也就是到达了网桥(docker0)处;
(3) docker0网桥开启了数据报转发功能(/proc/sys/net/ipv4/ip_forward),故将请求发送至宿主机的eth0处;
(4) 宿主机处理请求时,使用SNAT对请求进行源地址IP转换,即将请求中源地址IP(容器IP地址)转换为宿主机eth0的IP地址;
(5) 宿主机将经过SNAT转换后的报文通过请求的目的IP地址(宿主机以外世界的IP地址)发送至外界。
在这里,很多人肯定会问:对于Docker Container内部主动发起对外的网络请求,当请求到达宿主机进行SNAT处理后发给外界,当外界响应请求时,响应报文中的目的IP地址肯定是Docker宿主机的IP地址,那响应报文回到宿主机的时候,宿主机又是如何转给Docker Container的呢?关于这样的响应,由于port_3端口并没有在宿主机上做相应的DNAT转换,原则上不会被发送至容器内部。为什么说对于这样的响应,不会做DNAT转换呢。原因很简单,DNAT转换是针对容器内部服务监听的特定端口做的,该端口是供服务监听使用,而容器内部发起的请求报文中,源端口号肯定不会占用服务监听的端口,故容器内部发起请求的响应不会在宿主机上经过DNAT处理。
其实,这一环节的内容是由iptables规则来完成,具体的iptables规则如下:
iptables -I FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
这条规则的意思是,在宿主机上发往docker0网桥的网络数据报文,如果是该数据报文所处的连接已经建立的话,则无条件接受,并由Linux内核将其发送到原来的连接上,即回到Docker Container内部。
以上便是Docker Container中bridge桥接模式的简要介绍。可以说,bridger桥接模式从功能的角度实现了两个方面:第一,让容器拥有独立、隔离的网络栈;第二,让容器和宿主机以外的世界通过NAT建立通信。
然而,bridge桥接模式下的Docker Container在使用时,并非为开发者包办了一切。最明显的是,该模式下Docker Container不具有一个公有IP,即和宿主机的eth0不处于同一个网段。导致的结果是宿主机以外的世界不能直接和容器进行通信。虽然NAT模式经过中间处理实现了这一点,但是NAT模式仍然存在问题与不便,如:容器均需要在宿主机上竞争端口,容器内部服务的访问者需要使用服务发现获知服务的外部端口等。另外NAT模式由于是在三层网络上的实现手段,故肯定会影响网络的传输效率。
3.2 host模式
Docker Container中的host模式与bridge桥接模式有很大的不同。最大的区别当属,host模式并没有为容器创建一个隔离的网络环境。而之所以称之为host模式,是因为该模式下的Docker Container会和host宿主机共享同一个网络namespace,故Docker Container可以和宿主机一样,使用宿主机的eth0,实现和外界的通信。换言之,Docker Container的IP地址即为宿主机eth0的IP地址。
Docker Container的host网络模式可以参考下图:
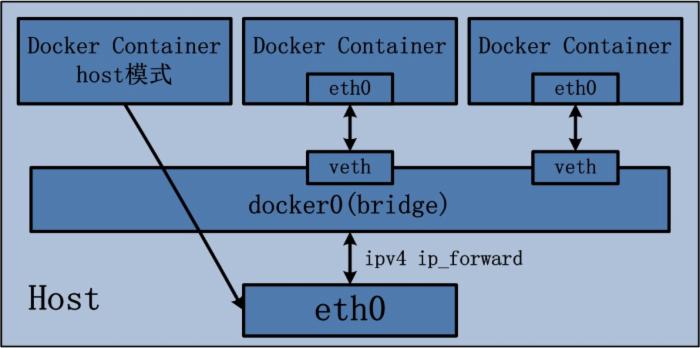
图3.2 Docker Container host网络模式示意图
上图最左侧的Docker Container,即采用了host网络模式,而其他两个Docker Container依然沿用brdige桥接模式,两种模式同时存在于宿主机上并不矛盾。
Docker Container的host网络模式在实现过程中,由于不需要额外的网桥以及虚拟网卡,故不会涉及docker0以及veth pair。上文namespace的介绍中曾经提到,父进程在创建子进程时,如果不使用CLONE_NEWNET这个参数标志,那么创建出的子进程会与父进程共享同一个网络namespace。Docker就是采用了这个简单的原理,在创建进程启动容器的过程中,没有传入CLONE_NEWNET参数标志,实现Docker Container与宿主机共享同一个网络环境,即实现host网络模式。
可以说,Docker Container的网络模式中,host模式是bridge桥接模式很好的补充。采用host模式的Docker Container,可以直接使用宿主机的IP地址与外界进行通信,若宿主机的eth0是一个公有IP,那么容器也拥有这个公有IP。同时容器内服务的端口也可以使用宿主机的端口,无需额外进行NAT转换。当然,有这样的方便,肯定会损失部分其他的特性,最明显的是Docker Container网络环境隔离性的弱化,即容器不再拥有隔离、独立的网络栈。另外,使用host模式的Docker Container虽然可以让容器内部的服务和传统情况无差别、无改造的使用,但是由于网络隔离性的弱化,该容器会与宿主机共享竞争网络栈的使用;另外,容器内部将不再拥有所有的端口资源,原因是部分端口资源已经被宿主机本身的服务占用,还有部分端口已经用以bridge网络模式容器的端口映射。
3.3 other container模式
Docker Container的other container网络模式是Docker中一种较为特别的网络的模式。之所以称为“other container模式”,是因为这个模式下的Docker Container,会使用其他容器的网络环境。之所以称为“特别”,是因为这个模式下容器的网络隔离性会处于bridge桥接模式与host模式之间。Docker Container共享其他容器的网络环境,则至少这两个容器之间不存在网络隔离,而这两个容器又与宿主机以及除此之外其他的容器存在网络隔离。
Docker Container的other container网络模式可以参考下图:
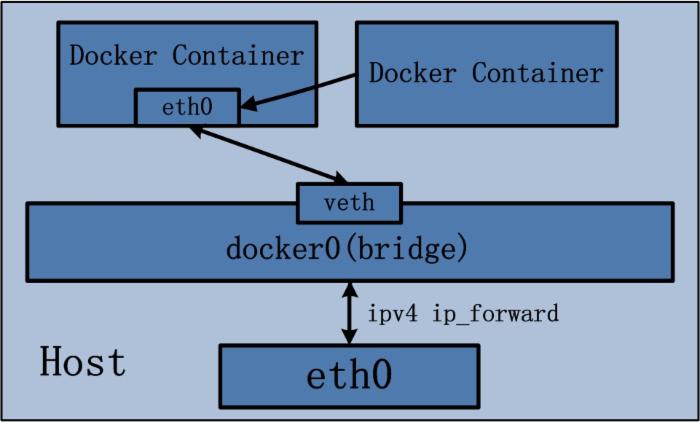
图3.3 Docker Container other container网络模式示意图
上图右侧的Docker Container即采用了other container网络模式,它能使用的网络环境即为左侧Docker Container brdige桥接模式下的网络。
Docker Container的other container网络模式在实现过程中,不涉及网桥,同样也不需要创建虚拟网卡veth pair。完成other container网络模式的创建只需要两个步骤:
(1) 查找other container(即需要被共享网络环境的容器)的网络namespace;
(2) 将新创建的Docker Container(也是需要共享其他网络的容器)的namespace,使用other container的namespace。
Docker Container的other container网络模式,可以用来更好的服务于容器间的通信。
在这种模式下的Docker Container可以通过localhost来访问namespace下的其他容器,传输效率较高。虽然多个容器共享网络环境,但是多个容器形成的整体依然与宿主机以及其他容器形成网络隔离。另外,这种模式还节约了一定数量的网络资源。但是需要注意的是,它并没有改善容器与宿主机以外世界通信的情况。
3.4 none模式
Docker Container的第四种网络模式是none模式。顾名思义,网络环境为none,即不为Docker Container任何的网络环境。一旦Docker Container采用了none网络模式,那么容器内部就只能使用loopback网络设备,不会再有其他的网络资源。
可以说none模式为Docker Container做了极少的网络设定,但是俗话说得好“少即是多”,在没有网络配置的情况下,作为Docker开发者,才能在这基础做其他无限多可能的网络定制开发。这也恰巧体现了Docker设计理念的开放。
4.作者介绍
孙宏亮, DaoCloud 初创团队成员,软件工程师,浙江大学VLIS实验室应届研究生。读研期间活跃在PaaS和Docker开源社区,对Cloud Foundry有深入研究和丰富实践,擅长底层平台代码分析,对分布式平台的架构有一定经验,撰写了大量有深度的技术博客。2014年末以合伙人身份加入DaoCloud团队,致力于传播以Docker为主的容器的技术,推动互联网应用的容器化步伐。邮箱: allen.sun@daocloud.io
5.下期预告
下期内容为:Docker源码分析(八):Docker Container网络(下)
感谢郭蕾对本文的审校和策划。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ)或者腾讯微博(@InfoQ)关注我们,并与我们的编辑和其他读者朋友交流。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

