hbase与关系数据库区别
任何一项新技术并非救命稻草,一抹一擦立马药到病除的百宝箱,并非使用Spring或者NOSQL的产品就神乎其神+五光十色,如果那样基本是扯淡。同类 型产品中不管那种技术最终要达到的目的是一样的,通过新的技术手段你往往可能避讳了当前你所需要面对的问题,但过后新的问题又来了。也许回过头来看看还不 如在原来的基础上多动动脑筋 想想办法 做些改良可以得到更高的回报。
传统数据库是以数据块来存储数据,简单来说,你的表字段越多,占用的数据空间就越多,那么查询有可能就要跨数据块,将会导致查询的速度变慢。在大型系统中一张表上百个字段,并且表中的数据上亿条这是完全是有可能的。因此会带来数据库查询的瓶颈。我们都知道一个常识数据库中表记录的多少对查询的性能有非常大的影响,此时你很有可能想到分表、分库的做法来分载数据库运算的压力,那么又会带来新的问题,例如:分布式事务、全局唯一ID的生成、跨数据库查询 等,依旧会让你面对棘手的问题。如果打破这种按照行存储的模式,采用一种基于列存储的模式,对于大规模数据场景这样情况有可能发生一些好转。由于查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储, 可以动态增加,并且列为空就不存储数据,节省存储空间。 每个字段的数据按照聚集存储,能大大减少读取的数据量,查询时指哪打哪,来的更直接。无需考虑分库、分表 Hbase将对存储的数据自动切分数据,并支持高并发读写操作,使得海量数据存储自动具有更强的扩展性。
Java中的HashMap是Key/Value的结构,你也可以把HBase的数据结构看做是一个Key/Value的体系,话说HBase的区域由表名和行界定的。在HBase区域每一个"列族"都由一个名为HStore的对象管理。每个HStore由一个或多个MapFiles(Hadoop中的一个文件类型)组成。MapFiles的概念类似于Google的SSTable。 在Hbase里面有以下两个主要的概念,Row key 和 Column Family,其次是Cell qualifier和Timestamp tuple,Column family我们通常称之为“列族”,访问控制、磁盘和内存的使用统计都是在列族层面进行的。列族Column family是之前预先定义好的数据模型,每一个Column Family都可以根据“限定符”有多个column。在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,最新的数据版本排在最前面 。
口水:Hbase将table水平划分成N个Region,region按column family划分成Store,每个store包括内存中的memstore和持久化到disk上的HFile。
上述可能我表达的还不够到位,下面来看一个实践中的场景,将原来是存放在MySQL中Blog中的数据迁移到HBase中的过程:
MySQL中现有的表结构:
 迁移HBase中的表结构:
迁移HBase中的表结构:
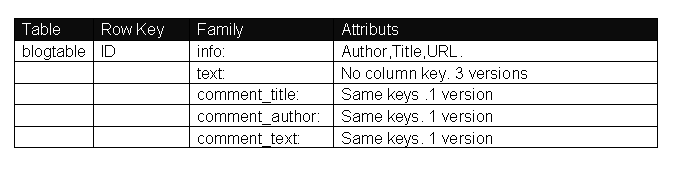 原来系统中有2张表blogtable和comment表,采用HBase后只有一张blogtable表,如果按照传统的RDBMS的话,blogtable表中的列是固定的,比如schema 定义了Author,Title,URL,text等属性,上线后表字段是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义blogtable表,然后定义info 列族,User的数据可以分为:info:title ,info:author ,info:url 等,如果后来你又想增加另外的属性,这样很方便只需要 info:xxx 就可以了。
对于Row key你可以理解row key为传统RDBMS中的某一个行的主键,Hbase是不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。 Hbase中的记录是按照rowkey来排序的,这样就使得查询变得非常快。
具体操作过程如下:
============================创建blogtable表=========================
create 'blogtable', 'info','text','comment_title','comment_author','comment_text'
============================插入概要信息=========================
put 'blogtable', '1', 'info:title', 'this is doc title'
put 'blogtable', '1', 'info:author', 'javabloger'
put 'blogtable', '1', 'info:url', 'http://www.javabloger.com/index.php'
put 'blogtable', '2', 'info:title', 'this is doc title2'
put 'blogtable', '2', 'info:author', 'H.E.'
put 'blogtable', '2', 'info:url', 'http://www.javabloger.com/index.html'
============================插入正文信息=========================
put 'blogtable', '1', 'text:', 'what is this doc context ?'
put 'blogtable', '2', 'text:', 'what is this doc context2?'
==========================插入评论信息===============================
put 'blogtable', '1', 'comment_title:', 'this is doc comment_title '
put 'blogtable', '1', 'comment_author:', 'javabloger'
put 'blogtable', '1', 'comment_text:', 'this is nice doc'
put 'blogtable', '2', 'comment_title:', 'this is blog comment_title '
put 'blogtable', '2', 'comment_author:', 'H.E.'
put 'blogtable', '2', 'comment_text:', 'this is nice blog'
HBase的数据查询读取,可以通过单个row key访问,row key的range和全表扫描,大致如下:
注意:HBase不能支持where条件、Order by 查询,只支持按照Row key来查询,但是可以通过HBase提供的API进行条件过滤。
例如:http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/ColumnPrefixFilter.html
scan 'blogtable' ,{COLUMNS => ['text:','info:title'] } —> 列出 文章的内容和标题
scan 'blogtable' , {COLUMNS => 'info:url' , STARTROW => '2'} —> 根据范围列出 文章的内容和标题
get 'blogtable','1' —> 列出 文章id 等于1的数据
get 'blogtable','1', {COLUMN => 'info'} —> 列出 文章id 等于1 的 info 的头(Head)内容
get 'blogtable','1', {COLUMN => 'text'} —> 列出 文章id 等于1 的 text 的具体(Body)内容
get 'blogtable','1', {COLUMN => ['text','info:author']} —> 列出 文章id 等于1 的内容和作者(Body/Author)内容
对于NOSQL这样的新技术,的的确确是可以解决过去我们所需要面对的问题,但也并非适合每个应用场景,所以在使用新产品的同时需要切合当前的产品需要, 是需求在引导新技术的投入,而并非为了赶时髦去使用他。你的产品是否过硬不是你使用了什么新技术,用户关心的是速度和稳定性,不会关心你是否使用了 NOSQL。相反Google有着超大的数据量,能给全世界用户带来了惊人的速度和准确性,大家才会回过头来好奇Google到底是怎么做到的。所以根据 自己的需要千万别太勉强自己使用了某项新技术。
总之一句话,用什么不是最关键,最关键是怎么去使用!
原来系统中有2张表blogtable和comment表,采用HBase后只有一张blogtable表,如果按照传统的RDBMS的话,blogtable表中的列是固定的,比如schema 定义了Author,Title,URL,text等属性,上线后表字段是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义blogtable表,然后定义info 列族,User的数据可以分为:info:title ,info:author ,info:url 等,如果后来你又想增加另外的属性,这样很方便只需要 info:xxx 就可以了。
对于Row key你可以理解row key为传统RDBMS中的某一个行的主键,Hbase是不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。 Hbase中的记录是按照rowkey来排序的,这样就使得查询变得非常快。
具体操作过程如下:
============================创建blogtable表=========================
create 'blogtable', 'info','text','comment_title','comment_author','comment_text'
============================插入概要信息=========================
put 'blogtable', '1', 'info:title', 'this is doc title'
put 'blogtable', '1', 'info:author', 'javabloger'
put 'blogtable', '1', 'info:url', 'http://www.javabloger.com/index.php'
put 'blogtable', '2', 'info:title', 'this is doc title2'
put 'blogtable', '2', 'info:author', 'H.E.'
put 'blogtable', '2', 'info:url', 'http://www.javabloger.com/index.html'
============================插入正文信息=========================
put 'blogtable', '1', 'text:', 'what is this doc context ?'
put 'blogtable', '2', 'text:', 'what is this doc context2?'
==========================插入评论信息===============================
put 'blogtable', '1', 'comment_title:', 'this is doc comment_title '
put 'blogtable', '1', 'comment_author:', 'javabloger'
put 'blogtable', '1', 'comment_text:', 'this is nice doc'
put 'blogtable', '2', 'comment_title:', 'this is blog comment_title '
put 'blogtable', '2', 'comment_author:', 'H.E.'
put 'blogtable', '2', 'comment_text:', 'this is nice blog'
HBase的数据查询读取,可以通过单个row key访问,row key的range和全表扫描,大致如下:
注意:HBase不能支持where条件、Order by 查询,只支持按照Row key来查询,但是可以通过HBase提供的API进行条件过滤。
例如:http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/ColumnPrefixFilter.html
scan 'blogtable' ,{COLUMNS => ['text:','info:title'] } —> 列出 文章的内容和标题
scan 'blogtable' , {COLUMNS => 'info:url' , STARTROW => '2'} —> 根据范围列出 文章的内容和标题
get 'blogtable','1' —> 列出 文章id 等于1的数据
get 'blogtable','1', {COLUMN => 'info'} —> 列出 文章id 等于1 的 info 的头(Head)内容
get 'blogtable','1', {COLUMN => 'text'} —> 列出 文章id 等于1 的 text 的具体(Body)内容
get 'blogtable','1', {COLUMN => ['text','info:author']} —> 列出 文章id 等于1 的内容和作者(Body/Author)内容
对于NOSQL这样的新技术,的的确确是可以解决过去我们所需要面对的问题,但也并非适合每个应用场景,所以在使用新产品的同时需要切合当前的产品需要, 是需求在引导新技术的投入,而并非为了赶时髦去使用他。你的产品是否过硬不是你使用了什么新技术,用户关心的是速度和稳定性,不会关心你是否使用了 NOSQL。相反Google有着超大的数据量,能给全世界用户带来了惊人的速度和准确性,大家才会回过头来好奇Google到底是怎么做到的。所以根据 自己的需要千万别太勉强自己使用了某项新技术。
总之一句话,用什么不是最关键,最关键是怎么去使用!
迁移HBase中的表结构:
原来系统中有2张表blogtable和comment表,采用HBase后只有一张blogtable表,如果按照传统的RDBMS的话,blogtable表中的列是固定的,比如schema 定义了Author,Title,URL,text等属性,上线后表字段是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义blogtable表,然后定义info 列族,User的数据可以分为:info:title ,info:author ,info:url 等,如果后来你又想增加另外的属性,这样很方便只需要 info:xxx 就可以了。
对于Row key你可以理解row key为传统RDBMS中的某一个行的主键,Hbase是不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。 Hbase中的记录是按照rowkey来排序的,这样就使得查询变得非常快。
具体操作过程如下:
============================创建blogtable表=========================
create 'blogtable', 'info','text','comment_title','comment_author','comment_text'
============================插入概要信息=========================
put 'blogtable', '1', 'info:title', 'this is doc title'
put 'blogtable', '1', 'info:author', 'javabloger'
put 'blogtable', '1', 'info:url', 'http://www.javabloger.com/index.php'
put 'blogtable', '2', 'info:title', 'this is doc title2'
put 'blogtable', '2', 'info:author', 'H.E.'
put 'blogtable', '2', 'info:url', 'http://www.javabloger.com/index.html'
============================插入正文信息=========================
put 'blogtable', '1', 'text:', 'what is this doc context ?'
put 'blogtable', '2', 'text:', 'what is this doc context2?'
==========================插入评论信息===============================
put 'blogtable', '1', 'comment_title:', 'this is doc comment_title '
put 'blogtable', '1', 'comment_author:', 'javabloger'
put 'blogtable', '1', 'comment_text:', 'this is nice doc'
put 'blogtable', '2', 'comment_title:', 'this is blog comment_title '
put 'blogtable', '2', 'comment_author:', 'H.E.'
put 'blogtable', '2', 'comment_text:', 'this is nice blog'
HBase的数据查询读取,可以通过单个row key访问,row key的range和全表扫描,大致如下:
注意:HBase不能支持where条件、Order by 查询,只支持按照Row key来查询,但是可以通过HBase提供的API进行条件过滤。
例如:http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/ColumnPrefixFilter.html
scan 'blogtable' ,{COLUMNS => ['text:','info:title'] } —> 列出 文章的内容和标题
scan 'blogtable' , {COLUMNS => 'info:url' , STARTROW => '2'} —> 根据范围列出 文章的内容和标题
get 'blogtable','1' —> 列出 文章id 等于1的数据
get 'blogtable','1', {COLUMN => 'info'} —> 列出 文章id 等于1 的 info 的头(Head)内容
get 'blogtable','1', {COLUMN => 'text'} —> 列出 文章id 等于1 的 text 的具体(Body)内容
get 'blogtable','1', {COLUMN => ['text','info:author']} —> 列出 文章id 等于1 的内容和作者(Body/Author)内容
对于NOSQL这样的新技术,的的确确是可以解决过去我们所需要面对的问题,但也并非适合每个应用场景,所以在使用新产品的同时需要切合当前的产品需要, 是需求在引导新技术的投入,而并非为了赶时髦去使用他。你的产品是否过硬不是你使用了什么新技术,用户关心的是速度和稳定性,不会关心你是否使用了 NOSQL。相反Google有着超大的数据量,能给全世界用户带来了惊人的速度和准确性,大家才会回过头来好奇Google到底是怎么做到的。所以根据 自己的需要千万别太勉强自己使用了某项新技术。
总之一句话,用什么不是最关键,最关键是怎么去使用!
正文到此结束
热门推荐










近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

