我们知道,HTTP/2 协议由两个 RFC 组成:一个是 RFC 7540 ,描述了 HTTP/2 协议本身;一个是 RFC 7541 ,描述了 HTTP/2 协议中使用的头部压缩技术,本文将通过实际案例带领大家详细地认识 HTTP/2 头部压缩这门技术。
为什么要压缩
在 HTTP/1 中,HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。
随着 Web 功能越来越复杂,每个页面产生的请求数也越来越多,根据 HTTP Archive 的统计,当前平均每个页面都会产生上百个请求。越来越多的请求导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。
以下是我随手打开一个页面的抓包结果。可以看到,传输头部的网络开销超过 100kb,比 HTML 还多:

下面是其中一个请求的明细。可以看到,为了获得 58 字节的数据,在头部传输上花费了好几倍的流量:
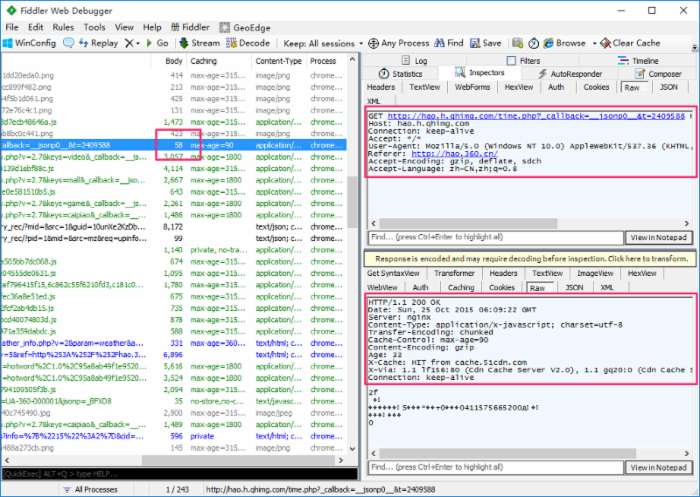
HTTP/1 时代,为了减少头部消耗的流量,有很多优化方案可以尝试,例如合并请求、启用 Cookie-Free 域名等等,但是这些方案或多或少会引入一些新的问题,这里不展开讨论。
压缩后的效果
接下来我将使用访问本博客的抓包记录来说明 HTTP/2 头部压缩带来的变化。如何使用 Wireshark 对 HTTPS 网站进行抓包并解密,请看我的这篇文章。本文使用的抓包文件,可以点这里下载。
首先直接上图。下图选中的 Stream 是浏览器发出的请求头:

从图片中可以看到这个 HEADERS 流的长度是 206 个字节,而解密后的头部长度有 451 个字节。由此可见,压缩后的头部大小减少了一半。
然而这就是全部吗?再上一张图。下图选中的 Stream 是点击本站链接后,浏览器发出的请求头:
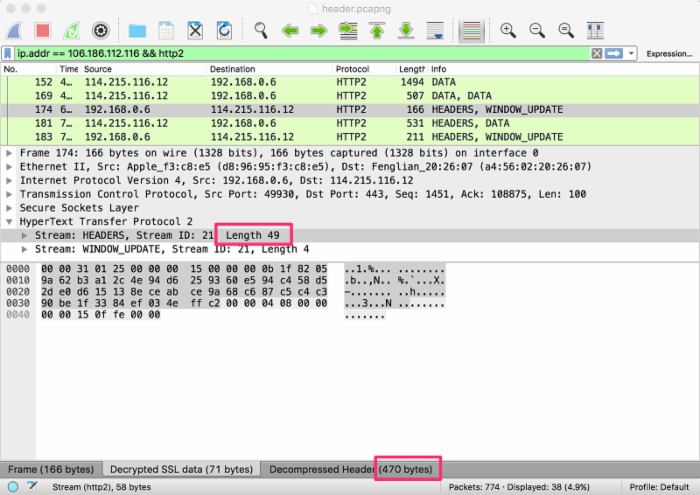
可以看到这一次,HEADERS 流的长度只有 49 个字节,但是解密后的头部长度却有 470 个字节。这一次,压缩后的头部大小几乎只有原始大小的 1/10。
为什么前后两次差距这么大呢?我们把两次的头部信息展开,查看同一个字段两次传输所占用的字节数:

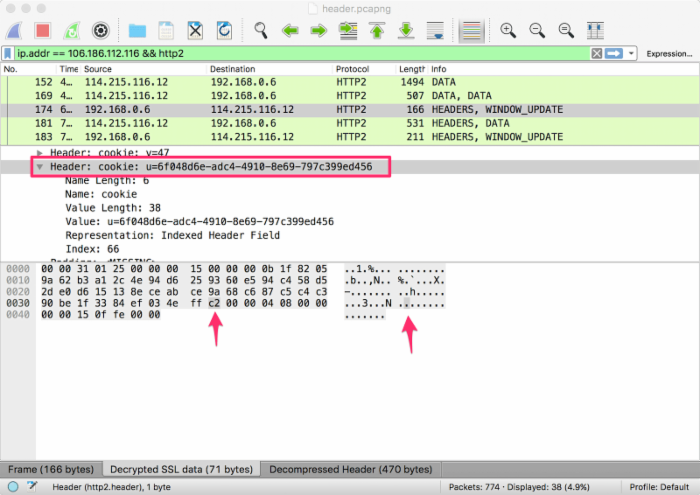
对比后可以发现,第二次的请求头部之所以非常小,是因为大部分键值对只占用了一个字节。尤其是 UserAgent、Cookie 这样的头部,首次请求中需要占用很多字节,后续请求中都只需要一个字节。
技术原理
下面这张截图,取自 Google 的性能专家 Ilya Grigorik 在 Velocity 2015 • SC 会议中分享的「 HTTP/2 is here, let's optimize! 」,非常直观地描述了 HTTP/2 中头部压缩的原理:
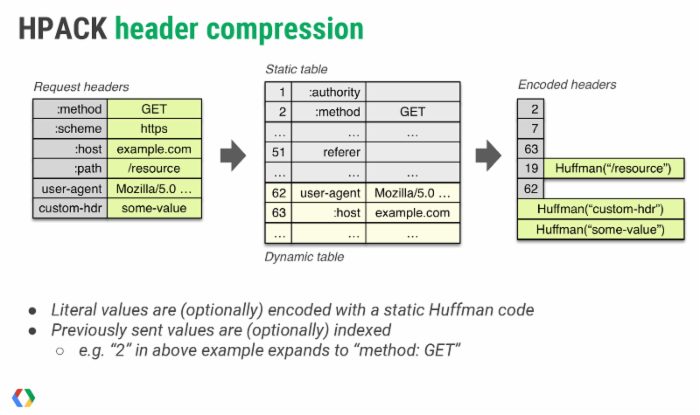
我再用通俗的语言解释下,头部压缩需要在支持 HTTP/2 的浏览器和服务端之间:
- 维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
- 维护一份相同的动态字典(Dynamic Table),可以动态的添加内容;
- 支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
静态字典的作用有两个:1)对于完全匹配的头部键值对,例如 :method :GET ,可以直接使用一个字符表示;2)对于头部名称可以匹配的键值对,例如 cookie :xxxxxxx ,可以将名称使用一个字符表示。HTTP/2 中的静态字典如下(以下只截取了部分,完整表格在 这里 ):
| Index | Header Name | Header Value |
|---|---|---|
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| ... | ... | ... |
| 32 | cookie | |
| ... | ... | ... |
| 60 | via | |
| 61 | www-authenticate |
同时,浏览器可以告知服务端,将 cookie :xxxxxxx 添加到动态字典中,这样后续整个键值对就可以使用一个字符表示了。类似的,服务端也可以更新对方的动态字典。需要注意的是,动态字典上下文有关,需要为每个 HTTP/2 连接维护不同的字典。
使用字典可以极大的提升压缩效果,其中静态字典在首次请求中就可以使用。对于静态、动态字典中不存在的内容,还可以使用哈夫曼编码来减小体积。HTTP/2 使用了一份静态哈夫曼码表( 详见 ),也需要内置在客户端和服务端之中。
这里顺便说一下,HTTP/1 的状态行信息(Method、Path、Status 等),在 HTTP/2 中被拆成键值对放入头部(冒号开头的那些),同样可以享受到字典和哈夫曼压缩。另外,HTTP/2 中所有头部名称必须小写。
实现细节
了解了 HTTP/2 头部压缩的基本原理,最后我们来看一下具体的实现细节。HTTP/2 的头部键值对有以下这些情况:
1)整个头部键值对都在字典中
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 1 | Index (7+) | +---+---------------------------+ 这是最简单的情况,使用一个字节就可以表示这个头部了,最左一位固定为 1,之后七位存放键值对在静态或动态字典中的索引。例如下图中,头部索引值为 2(0000010),在静态字典中查询可得 :method :GET 。

2)头部名称在字典中,并更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | Index (6+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+ 对于这种情况,首先需要使用一个字节表示头部名称:左两位固定为 01,之后六位存放头部名称在静态或动态字典中的索引。接下来的一个字节表示头部值的长度 N,后续 N 个字节就是头部值的内容了,可使用哈夫曼编码。例如下图中索引值为 32(100000),在静态字典中查询可知名称为 cookie ,头部值的长度是 28(0011100),接下来的 28 个字节是 cookie 的值,将其进行哈夫曼解码就能得到具体内容。

客户端或服务端看到这种格式的头部键值对,会将其添加到自己的动态字典中。后续传输这样的内容,就符合第 1 种情况了。
3)头部名称不在字典中,并更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+ 这种情况与第 2 种情况类似,只是由于头部名称不在字典中,所以第一个字节固定为 01000000;接着申明名称的长度,并放上名称的具体内容;再申明值的长度,最后放上值的具体内容。例如下图中名称的长度是 5(0000101),值的长度是 6(0000110)。对其具体内容进行哈夫曼解码后,可得 pragma: no-cache 。
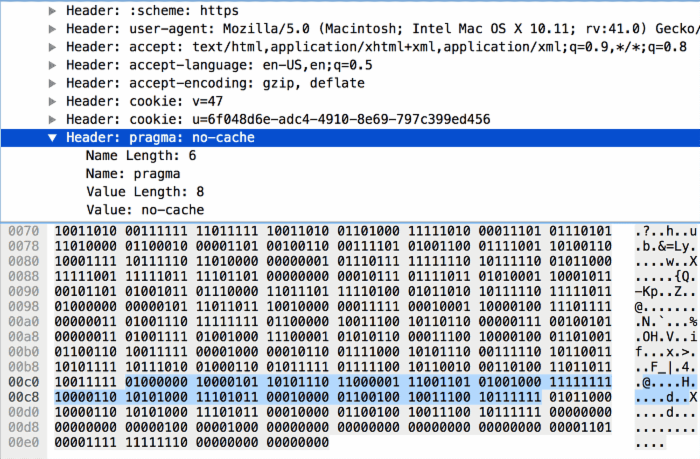
客户端或服务端看到这种格式的头部键值对,会将其添加到自己的动态字典中。后续传输这样的内容,就符合第 1 种情况了。
4)头部名称在字典中,不更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | Index (4+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+ 这种情况与第 2 种情况非常类似,唯一不同之处是:第一个字节左四位固定为 0001,只剩下四位来存放索引了,如下图:
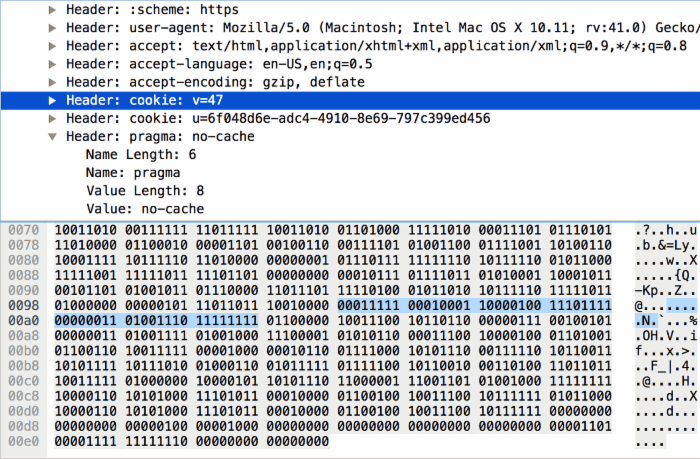
对于这种格式的头部键值对,不能将其添加到动态字典中(可以使用哈夫曼编码)。对于一些非常敏感的头部,比如用来认证的 Cookie,这么做可以提高安全性。
5)头部名称不在字典中,不更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+ 这种情况与第 3 种情况非常类似,唯一不同之处是:第一个字节固定为 00010000。这种情况比较少见,没有截图,各位可以脑补。同样,对于这种格式的头部键值对,也不能将其添加到动态字典中,只能使用哈夫曼编码来减少体积。
明白了头部压缩的技术细节,理论上可以很轻松写出 HTTP/2 头部解码工具了。我比较懒,直接找来 node-http2 中的 compressor.js 验证一下:
var compressor = require('./compressor'); var Decompressor = compressor.Decompressor; var log = require('bunyan').createLogger({name: 'test'}); var decompressor = new Decompressor(log, 'REQUEST'); var buffer; var result; buffer = new Buffer('820481634188353daded6ae43d3f877abdd07f66a281b0dae053fad0321aa49d13fda992a49685340c8a6adca7e28102e10fda9677b8d05707f6a62293a9d810020004015309ac2ca7f2c3415c1f53b0497ca589d34d1f43aeba0c41a4c7a98f33a69a3fdf9a68fa1d75d0620d263d4c79a68fbed00177febe58f9fbed00177b518b2d4b70ddf45abefb4005db901f1184ef034eff609cb60725034f48e1561c8469669f081678ae3eb3afba465f7cb234db9f4085aec1cd48ff86a8eb10649cbf', 'hex'); result = decompressor.decompress(buffer); decompressor._table.forEach(function(row, index) { console.log(index + 1, row[0], row[1]); }); 头部原始数据来自于本文第三张截图,运行结果如下(静态字典只截图了一部分):
{ ':method': 'GET', ':path': '/', ':authority': 'imququ.com', ':scheme': 'https', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:41.0) Gecko/20100101 Firefox/41.0', accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'accept-language': 'en-US,en;q=0.5', 'accept-encoding': 'gzip, deflate', cookie: 'v=47; u=6f048d6e-adc4-4910-8e69-797c399ed456', pragma: 'no-cache' } 1 ':authority' '' 2 ':method' 'GET' 3 ':method' 'POST' 4 ':path' '/' 5 ':path' '/index.html' 6 ':scheme' 'http' 7 ':scheme' 'https' 8 ':status' '200' ... ... 32 'cookie' '' ... ... 60 'via' '' 61 'www-authenticate' '' 62 'pragma' 'no-cache' 63 'cookie' 'u=6f048d6e-adc4-4910-8e69-797c399ed456' 64 'accept-language' 'en-US,en;q=0.5' 65 'accept' 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' 66 'user-agent' 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:41.0) Gecko/20100101 Firefox/41.0' 67 ':authority' 'imququ.com' 可以看到,这段从 Wireshark 拷出来的头部数据可以正常解码,动态字典也得到了更新(62 - 67)。
在进行 HTTP/2 网站性能优化时很重要一点是「使用尽可能少的连接数」,本文提到的头部压缩是其中一个很重要的原因:同一个连接上产生的请求和响应越多,动态字典积累得越全,头部压缩效果也就越好。所以,针对 HTTP/2 网站,最佳实践是不要合并资源,不要做域名散列。
默认情况下,浏览器会针对这些情况使用同一个连接:
- 同一域名下的资源;
- 不同域名下的资源,但是满足两个条件:1)解析到同一个 IP;2)使用同一个证书;
上面第一点容易理解,第二点则很容易被忽略,实际上 Google 已经这么做了,Google 一系列网站都共用了同一个证书,可以这样验证:
$ openssl s_client -connect google.com:443 |openssl x509 -noout -text | grep DNS depth=2 C = US, O = GeoTrust Inc., CN = GeoTrust Global CA verify error:num=20:unable to get local issuer certificate verify return:0 DNS:*.google.com, DNS:*.android.com, DNS:*.appengine.google.com, DNS:*.cloud.google.com, DNS:*.google-analytics.com, DNS:*.google.ca, DNS:*.google.cl, DNS:*.google.co.in, DNS:*.google.co.jp, DNS:*.google.co.uk, DNS:*.google.com.ar, DNS:*.google.com.au, DNS:*.google.com.br, DNS:*.google.com.co, DNS:*.google.com.mx, DNS:*.google.com.tr, DNS:*.google.com.vn, DNS:*.google.de, DNS:*.google.es, DNS:*.google.fr, DNS:*.google.hu, DNS:*.google.it, DNS:*.google.nl, DNS:*.google.pl, DNS:*.google.pt, DNS:*.googleadapis.com, DNS:*.googleapis.cn, DNS:*.googlecommerce.com, DNS:*.googlevideo.com, DNS:*.gstatic.cn, DNS:*.gstatic.com, DNS:*.gvt1.com, DNS:*.gvt2.com, DNS:*.metric.gstatic.com, DNS:*.urchin.com, DNS:*.url.google.com, DNS:*.youtube-nocookie.com, DNS:*.youtube.com, DNS:*.youtubeeducation.com, DNS:*.ytimg.com, DNS:android.com, DNS:g.co, DNS:goo.gl, DNS:google-analytics.com, DNS:google.com, DNS:googlecommerce.com, DNS:urchin.com, DNS:youtu.be, DNS:youtube.com, DNS:youtubeeducation.com 本文链接: https://imququ.com/post/header-compression-in-http2.html
-- EOF --
于 2015-10-25 20:57:26 发表于「前端技术」分类下,并被添加「HTTP2、Wireshark」标签。
本站部署于「 阿里云 ECS 」。如果你也要购买阿里云服务,可以使用我的九折推荐码 NY1Z0E ,感谢你对本站的支持!
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

