PalDB —— LinkedIn 的嵌入式只读 KV 存储系统
PalDB 是 LinkedIn 开源的可嵌入只读 Key-Value 存储系统。
PalDB 是一个可嵌入,持续 Key-Value 存储,拥有非常快的性能和合适的存储大小。PalDB 存储是单个二进制文件,只能编写一次,可以直接在应用中使用。
PalDB 的 JAR 包只有 110K,只有单个依赖 (snappy, which isn't mandatory),可以跟一些配置参数一起使用。
因为 PalDB 是只读的存储系统,只关注数据,相比其他嵌入式 key-value 系统来说非常简单,拥有较高的吞吐量。
当前的基准测试基于 3.1Ghz Macbook Pro:
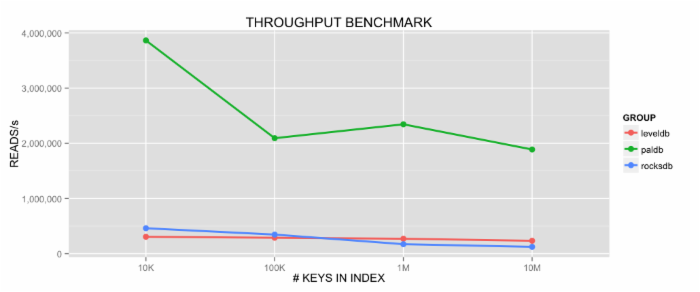
PalDB, LevelDB 和 RocksDB 吞吐量比较(越高越好)
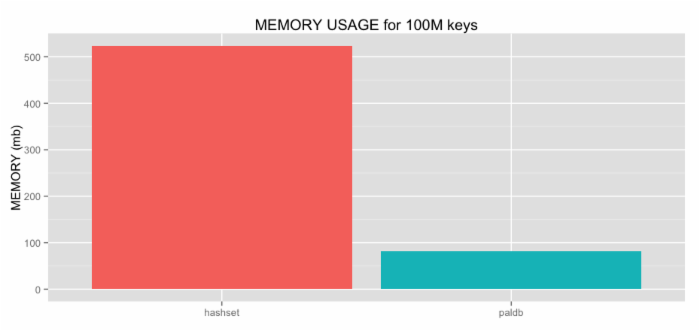
PalDB 和一个 Java HashSet 内存使用比较(越低越好)
编写一个存储:
StoreWriter writer = PalDB.createWriter(new File("store.paldb")); writer.put("foo", "bar"); writer.put(1213, new int[] {1, 2, 3}); writer.close(); 查看一个存储:
StoreReader reader = PalDB.createReader(new File("store.paldb")); String val1 = reader.get("foo"); int[] val2 = reader.get(1213); reader.close(); 迭代
StoreReader reader = PalDB.createReader(new File("store.paldb")); Iterable<Map.Entry<String, String>> iterable = reader.iterable(); for (Map.Entry<String, String> entry : iterable) { String key = entry.getKey(); String value = entry.getValue(); } reader.close(); 正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

