Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning
对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人、象棋AI程序)在决定一步后,获得了较好的结果,那么我们给agent一些回报(比如回报函数结果为正),得到较差的结果,那么回报函数为负。比如,四足机器人,如果他向前走了一步(接近目标),那么回报函数为正,后退为负。如果我们能够对每一步进行评价,得到相应的回报函数,那么就好办了,我们只需要找到一条回报值最大的路径(每步的回报之和最大),就认为是最佳的路径。
增强学习在很多领域已经获得成功应用,比如自动直升机,机器人控制,手机网络路由,市场决策,工业控制,高效网页索引等。本节的增强学习从马尔科夫决策过程(MDP,Markov decision processes)开始。
Markov decision processes
马尔科夫决策过程由一个五元组构成
-
S表示状态集(states)。(比如,在自动直升机系统中,直升机当前位置坐标组成状态集)
-
A表示一组动作(actions)。(比如,使用控制杆操纵的直升机飞行方向,让其向前,向后等)
-
是状态转移概率。S中的一个状态到另一个状态的转变,需要A来参与。表示的是在当前状态下,经过作用后,会转移到的其他状态的概率分布情况(当前状态执行a后可能跳转到很多状态)。
-
是阻尼系数(discount factor)
-
,R是回报函数(reward function),回报函数经常写作S的函数(只与S有关),这样的话,R重新写作。
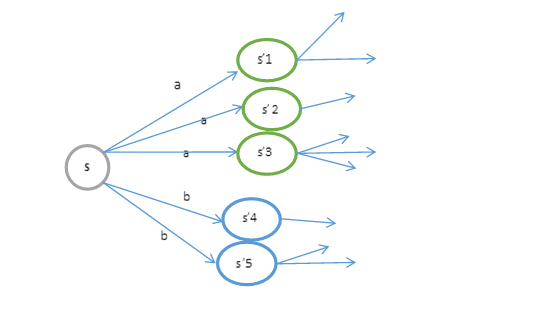
MDP的动态过程如下:某个agent的初始状态为,然后从A中挑选一个动作执行,执行后,agent按概率随机转移到了下一个状态,。然后再执行一个动作,就转移到了,接下来再执行…,我们可以用下面的图表示整个过程

我们定义经过上面转移路径后,得到的回报函数之和如下

如果R只和S有关,那么上式可以写作
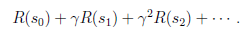
我们的目标是选择一组最佳的action,使得全部的回报加权和期望最大。
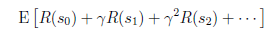
从上式可以发现,在t时刻的回报值被打了的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的尽量放到前面,小的尽量放到后面。
已经处于某个状态s时,我们会以一定策略来选择下一个动作a执行,然后转换到另一个状态s'。我们将这个动作的选择过程称为策略(policy),每一个policy其实就是一个状态到动作的映射函数。给定也就给定了,也就是说,知道了就知道了每个状态下一步应该执行的动作。
我们为了区分不同的好坏,并定义在当前状态下,执行某个策略后,出现的结果的好坏,需要定义值函数(value function)也叫折算累积回报(discounted cumulative reward)
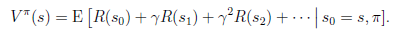
可以看到,在当前状态s下,选择好policy后,值函数是回报加权和期望。这个其实很容易理解,给定也就给定了一条未来的行动方案,这个行动方案会经过一个个的状态,而到达每个状态都会有一定回报值,距离当前状态越近的其他状态对方案的影响越大,权重越高。这和下象棋差不多,在当前棋局下,不同的走子方案是,我们评价每个方案依靠对未来局势(,,…)的判断。一般情况下,我们会在头脑中多考虑几步,但是我们会更看重下一步的局势。
从递推的角度上考虑,当期状态s的值函数V,其实可以看作是当前状态的回报R(s)和下一状态的值函数V'之和,也就是将上式变为:
然而,我们需要注意的是虽然给定后,在给定状态s下,a是唯一的,但可能不是多到一的映射。比如你选择a为向前投掷一个骰子,那么下一个状态可能有6种。再由Bellman等式,从上式得到
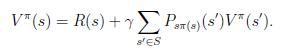
s'表示下一个状态。
前面的R(s)称为立即回报(immediate reward),就是R(当前状态)。第二项也可以写作,是下一状态值函数的期望值,下一状态s'符合分布。
可以想象,当状态个数有限时,我们可以通过上式来求出每一个s的V(终结状态没有第二项V(s'))。如果列出线性方程组的话,也就是|S|个方程,|S|个未知数,直接求解即可。
当然,我们求V的目的就是想找到一个当前状态s下,最优的行动策略,定义最优的V*如下:
就是从可选的策略中挑选一个最优的策略(discounted rewards最大)。
上式的Bellman等式形式如下:
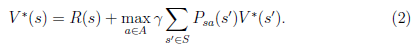
第一项与无关,所以不变。第二项是一个就决定了每个状态s的下一步动作a,执行a后,s'按概率分布的回报概率和的期望。
如果上式还不好理解的话,可以参考下图:
定义了最优的V*,我们再定义最优的策略如下:
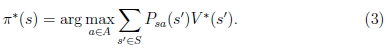
选择最优的,也就确定了每个状态s的下一步最优动作a。
根据以上式子,我们可以知道
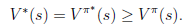
解释一下就是当前状态的最优的值函数V*,是由采用最优执行策略的情况下得出的,采用最优执行方案的回报显然要比采用其他的执行策略要好。
这里需要注意的是,如果我们能够求得每个s下最优的a,那么从全局来看,的映射即可生成,而生成的这个映射是最优映射,称为。针对全局的s,确定了每一个s的下一个行动a,不会因为初始状态s选取的不同而不同。
Value iteration and policy iteration
本节讨论两种求解有限状态MDP具体策略的有效算法。这里,我们只针对MDP是有限状态、有限动作的情况,。
值迭代法
-
将每一个s的V(s)初始化为0
-
循环直到收敛 {
对于每一个状态s,对V(s)做更新
}
值迭代策略利用了上节中 bellman equation (2)
内循环的实现有两种策略:
1) 同步迭代法
拿初始化后的第一次迭代来说吧,初始状态所有的V(s)都为0。然后对所有的s都计算新的V(s)=R(s)+0=R(s)。在计算每一个状态时,得到新的V(s)后,先存下来,不立即更新。待所有的s的新值V(s)都计算完毕后,再统一更新。
这样,第一次迭代后,V(s)=R(s)。
2) 异步迭代法
与同步迭代对应的就是异步迭代了,对每一个状态s,得到新的V(s)后,不存储,直接更新。这样,第一次迭代后,大部分V(s)>R(s)。
不管使用这两种的哪一种,最终V(s)会收敛到V*(s)。知道了V*后,我们再使用公式(3)来求出相应的最优策略,当然可以在求V*的过程中求出。
策略迭代法
值迭代法使V值收敛到V*,而策略迭代法关注,使收敛到。
-
将随机指定一个S到A的映射。
-
循环直到收敛 {
- 令
-
对于每一个状态s,对做更新
}
-
(a)步中的V可以通过之前的Bellman等式求得
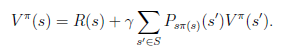
这一步会求出所有状态s的。
(b)步实际上就是根据(a)步的结果挑选出当前状态s下,最优的a,然后对做更新。
对于值迭代和策略迭代很难说哪种方法好,哪种不好。对于规模比较小的MDP来说,策略一般能够更快地收敛。但是对于规模很大(状态很多)的MDP来说,值迭代比较容易(不用求线性方程组)。
Learning a model for an MDP
在之前讨论的MDP中,我们是已知状态转移概率和回报函数R(s)的。但在很多实际问题中,这些参数不能显式得到,我们需要从数据中估计出这些参数(通常S、A和是已知的)。
假设我们已知很多条状态转移路径如下:
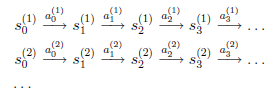
其中,是i时刻,第j条转移路径对应的状态,是状态时要执行的动作。每个转移路径中状态数是有限的,在实际操作过程中,每个转移链要么进入终结状态,要么达到规定的步数就会终结。
如果我们获得了很多上面类似的转移链(相当于有了样本),那么我们就可以使用最大似然估计来估计状态转移概率。

分子是从s状态执行动作a后到达s'的次数,分母是在状态s时,执行a的次数。两者相除就是在s状态下执行a后,会转移到s'的概率。
为了避免分母为0的情况,我们需要做平滑。如果分母为0,则令,也就是说当样本中没有出现过在s状态下执行a的样例时,我们认为转移概率均分。
上面这种估计方法是从历史数据中估计,这个公式同样适用于在线更新。比如我们新得到了一些转移路径,那么对上面的公式进行分子分母的修正(加上新得到的count)即可。修正过后,转移概率有所改变,按照改变后的概率,可能出现更多的新的转移路径,这样会越来越准。
同样,如果回报函数未知,那么我们认为R(s)为在s状态下已经观测到的回报均值。
当转移概率和回报函数估计出之后,我们可以使用值迭代或者策略迭代来解决MDP问题。比如,我们将参数估计和值迭代结合起来(在不知道状态转移概率情况下)的流程如下:
- 随机初始化
- 循环直到收敛 {
-
在样本上统计中每个状态转移次数,用来更新和R
-
使用估计到的参数来更新V(使用上节的值迭代方法)
-
根据更新的V来重新得出
-
}
在(b)步中我们要做值更新,也是一个循环迭代的过程,在上节中,我们通过将V初始化为0,然后进行迭代来求解V。嵌套到上面的过程后,如果每次初始化V为0,然后迭代更新,就会很慢。一个加快速度的方法是每次将V初始化为上一次大循环中得到的V。也就是说V的初值衔接了上次的结果。
参考文献
[1] Machine Learning Open Class by Andrew Ng in Stanford http://openclassroom.stanford.edu/MainFolder/CoursePage.php?course=MachineLearning
[2] Yu Zheng, Licia Capra, Ouri Wolfson, Hai Yang. Urban Computing: concepts, methodologies, and applications . ACM Transaction on Intelligent Systems and Technology. 5(3), 2014
[3] Jerry Lead http://www.cnblogs.com/jerrylead/
[3]《大数据-互联网大规模数据挖掘与分布式处理》 Anand Rajaraman,Jeffrey David Ullman著,王斌译
[4] UFLDL Tutorial http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
[5] Spark MLlib之朴素贝叶斯分类算法 http://selfup.cn/683.html
[6] MLlib - Dimensionality Reduction http://spark.apache.org/docs/latest/mllib-dimensionality-reduction.html
[7] 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用 http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
[8] 浅谈 mllib 中线性回归的算法实现 http://www.cnblogs.com/hseagle/p/3664933.html
[9] 最大似然估计 http://zh.wikipedia.org/zh-cn/%E6%9C%80%E5%A4%A7%E4%BC%BC%E7%84%B6%E4%BC%B0%E8%AE%A1
[10] Deep Learning Tutorial http://deeplearning.net/tutorial/
雪松
Microsoft MVP
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

