
Node.js 诞生之初就遭到不少这样的吐槽,当然这些都早已不是问题了。
1、可靠性低。
2、单进程,单线程,只支持单核 CPU,不能充分的利用多核 CPU 服务器。一旦这个进程崩掉,那么整个 web 服务就崩掉了。
回想以前用 php 开发 web 服务器的时候,每个 request 都在单独的线程中处理,即使某一个请求发生很严重的错误也不会影响到其它请求。Node.js 会在一个线程中处理大量请求,如果处理某个请求时产生一个没有被捕获到的异常将导致整个进程的退出,已经接收到的其它连接全部都无法处理,对一个 web 服务器来说,这绝对是致命的灾难。
应用部署到多核服务器时,为了充分利用多核 CPU 资源一般启动多个 Node.js 进程提供服务,这时就会使用到 Node.js 内置的 cluster 模块了。相信大多数的 Node.js 开发者可能都没有直接使用到 cluster,cluster 模块对 child_process 模块提供了一层封装,可以说是为了发挥服务器多核优势而量身定做的。简单的一个 fork,不需要开发者修改任何的应用代码便能够实现多进程部署。当下最热门的带有负载均衡功能的 Node.js 应用进程管理器 pm2 便是最好的一个例子,开发的时候完全不需要关注多进程场景,剩余的一切都交给 pm2 处理,与开发者的应用代码完美分离。
pm2 start app.js
pm2 确实非常强大,但本文并不讲解 pm2 的工作原理,而是从更底层的进程通信讲起,为大家揭秘使用 Node.js 开发 web 应用时,使用 cluster 模块实现多进程部署的原理。
fork
说到多进程当然少不了 fork ,在 un*x 系统中,fork 函数为用户提供最底层的多进程实现。
fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.
The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect the other.
本文中要讲解的 fork 是 cluster 模块中非常重要的一个方法,当然了,底层也是依赖上面提到的 fork 函数实现。 多个子进程便是通过在master进程中不断的调用 cluster.fork 方法构造出来。下面的结构图大家应该非常熟悉了。
 上面的图非常粗糙, 并没有告诉我们 master 与 worker 到底是如何分工协作的。Node.js 在这块做过比较大的改动,下面就细细的剖析开来。
上面的图非常粗糙, 并没有告诉我们 master 与 worker 到底是如何分工协作的。Node.js 在这块做过比较大的改动,下面就细细的剖析开来。
多进程监听同一端口
最初的 Node.js 多进程模型就是这样实现的,master 进程创建 socket,绑定到某个地址以及端口后,自身不调用 listen 来监听连接以及 accept 连接,而是将该 socket 的 fd 传递到 fork 出来的 worker 进程,worker 接收到 fd 后再调用 listen,accept 新的连接。但实际一个新到来的连接最终只能被某一个 worker 进程 accpet 再做处理,至于是哪个 worker 能够 accept 到,开发者完全无法预知以及干预。这势必就导致了当一个新连接到来时,多个 worker 进程会产生竞争,最终由胜出的 worker 获取连接。
之所以可以这么做,最核心的一点是文件描述符可以在进程间进行传递,对底层感兴趣的同学可以看下我收集的一些技术文章 《进程通信》
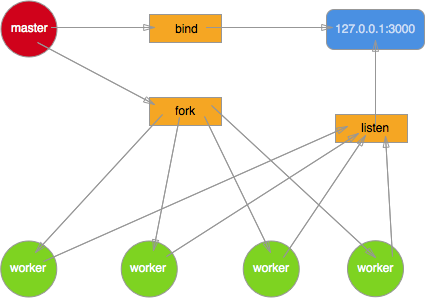
为了进一步加深对这种模型的理解,我编写了一个非常简单的 demo。
master 进程
const net = require('net');
const fork = require('child_process').fork;
var handle = net._createServerHandle('0.0.0.0', 3000);
for(var i=0;i<4;i++) {
fork('./worker').send({}, handle);
}
worker 进程
const net = require('net');
process.on('message', function(m, handle) {
start(handle);
});
var buf = 'hello nodejs';
var res = ['HTTP/1.1 200 OK','content-length:'+buf.length].join('/r/n')+'/r/n/r/n'+buf;
function start(server) {
server.listen();
server.onconnection = function(err,handle) {
console.log('got a connection on worker, pid = %d', process.pid);
var socket = new net.Socket({
handle: handle
});
socket.readable = socket.writable = true;
socket.end(res);
}
}
保存后直接运行 node master.js 启动服务器,在另一个终端多次运行 ab -n10000 -c100 http://127.0.0.1:3000/
各个 worker 进程统计到的请求数分别为
worker 63999 got 14561 connections
worker 64000 got 8329 connections
worker 64001 got 2356 connections
worker 64002 got 4885 connections
相信到这里大家也应该知道这种多进程模型比较明显的问题了
- 多个进程之间会竞争 accpet 一个连接,产生惊群现象,效率比较低。
- 由于无法控制一个新的连接由哪个进程来处理,必然导致各 worker 进程之间的负载非常不均衡。
这其实就是著名的”惊群”现象。
简单说来,多线程/多进程等待同一个 socket 事件,当这个事件发生时,这些线程/进程被同时唤醒,就是惊群。可以想见,效率很低下,许多进程被内核重新调度唤醒,同时去响应这一个事件,当然只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠(也有其他选择)。这种性能浪费现象就是惊群。
惊群通常发生在 server 上,当父进程绑定一个端口监听 socket,然后 fork 出多个子进程,子进程们开始循环处理(比如 accept)这个 socket。每当用户发起一个 TCP 连接时,多个子进程同时被唤醒,然后其中一个子进程 accept 新连接成功,余者皆失败,重新休眠。
nginx proxy
现代的 web 服务器一般都会在应用服务器外面再添加一层负载均衡,比如目前使用最广泛的 nginx。利用 nginx 强大的反向代理功能,可以启动多个独立的 node 进程,分别绑定不同的端口,最后由nginx 接收请求然后进行分配。
http {
upstream cluster {
server 127.0.0.1:3000;
server 127.0.0.1:3001;
server 127.0.0.1:3002;
server 127.0.0.1:3003;
}
server {
listen 80;
server_name www.domain.com;
location / {
proxy_pass http://cluster;
}
}
}
这种方式就将负载均衡的任务完全交给了 nginx 处理,并且 nginx 本身也相当擅长。再加一个守护进程负责各个 node 进程的稳定性,这种方案也勉强行得通。但也有比较大的局限性,比如想增加或者减少一个进程时还得再去改下 nginx 的配置。该方案与 nginx 耦合度太高,实际项目中并不经常使用。
小结
说了这么多,一直在讲解 Node.js 多进程部署时遇到的各种问题。小伙伴们肯定会有非常多的疑问。实际的 Node.js 项目中我们到底是如何利用多进程的呢,并且如何保障各个 worker 进程的稳定性。如何利用 cluster 模块 fork 子进程,父子进程间又是如何实现通信的呢?
下篇将为大家一一揭晓,敬请期待!
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

