一种基于Rsync算法的数据库备份方案设计
根据容灾备份系统对备份类别的要求程度,数据库备份系统可以分为数据级备份和应用级备份。数据备份是指建立一个异地的数据备份系统,该系统是对原本地系统关键应用数据实时复制。当出现故障时,可由异地数据系统迅速恢复本地数据从而保证业务的连续性。应用级备份比数据备份层次更高,即在异地建立一套完整的、与本地数据库系统相当的备份数据库应用系统,同时备份本地数据。可以同本地应用系统互为备份,也可与本地应用系统共同工作,在灾难故障出现后,远程应用系统迅速接管或承担本地应用系统的业务运行。本文基于 Rsync算法设计实现数据库应用级容灾备份方案,并说明方案的部署及实施流程。
Rsync介绍
Rsync(remote synchronize)是一款开源的Linux/Unix远程数据同步工具,可以通过网络快速同步多台服务器主机之间的文件与目录。其核心为“Rsync算法”,它由澳大利亚计算机工程师Andrew Tridgell发明。算法思路利用差分计算两个文件不同编码值,并将该编码值传给同步源文件,来获取两个文件在不进行文件内容直接网络传输的情况下知道两个文件的不同和相同之处,从而仅仅对文件的不同内容进行同步传输,以减少网络数据传输量,进而提高传输效率达到同步文件的效果。算法核心包括了Checksum算法、传输算法、Checksum searching算法、对比算法。
Checksum算法首先会把同步目标文件平均切分成若干个小块,比如每块512个字节(最后一块会小于这个数),然后对每块计算两个校验和(Checksum):
- 一个叫滚动校验和(rolling checksum),为32位弱校验和,使用adler-32算法;
- 另一个为强校验和(md5 checksum),采用128位的md5 Hash算法;
通过弱滚动校验和来快速计算出两文件块的不同,但该算法碰撞概率较高。因此,通过引入强checksum校验和来计算两文件块的相同。
文件块的校验和计算完毕后,会将一个checksum列表传输给同步源文件,包括rolling checksum(32bits)、md5 checksum(128bits)、文件块编号。源文件会进行同样的校验和算法计算,并与列表进行对比发现文件的不同和相同之处。
同步源文件通过采用checksum searching算法来查找,将目标文件的checksum列表数据存放在一个16bits的hash table中,采用rolling checksum做hash值,以便获得时间复杂度的查找性能。Hash table的大小为216,对rolling checksum的hash会被散列到0到216-1中的某个整数值。对hash值发生碰撞的则做成一个链表进行存放。
最复杂关键的为文件块的对比算法。同步源文件将自身的文件块进行checksum计算后,从hash table中进行查找。如果查到了则说明发现了相同的文件块信息,再计算比较md5的checksum,如果md5 checksum再相同则说明目标文件中存在相同的文件块,并记录文件块编号。如果没有查找到则说明文件块信息不同,也不用再计算md5 checksum值。总之,只要rolling checksum或md5 checksum其中有不匹配的项,那么对比算法就会对文件块进行rolling动作,算法会往后跳1个字节,取2-513字节的文件块计算checksum,重复进行相关的查找对比,直到完成整个源同步文件的对比。通过对比算法可以找出相邻两次匹配中的那些文本字符不同,则需要同步传输给目标文件。对比算法流程如图1所示:
 图1.对比算法流程说明
图1.对比算法流程说明
同步源文件通过Rsync算法后会得到一个数据数组表,如图2所示。其中绿色文件块为在目标文件端已匹配上,不用再进行传输。而白色文件块则是匹配不上,需要通过传输进行同步的数据内容,这些数据内容是不定长的字节。最终,同步源文件把这个数据内容和数组表一起压缩传给目标文件端,在目标文件端的Rsync算法会根据这个表重新生成文件,这样同步完成。
 图2.数据数组表示例
图2.数据数组表示例
Rsync是一个客户端与服务端架构部署的网络结构。Rsync服务端指运行rsync deamon守护进程的服务器,并设置备份目录来保存同步目标文件;Rsync客户端则发起rsync连接的服务器,存放备份的同步源文件。Rsync的备份服务器体系结构如图3。
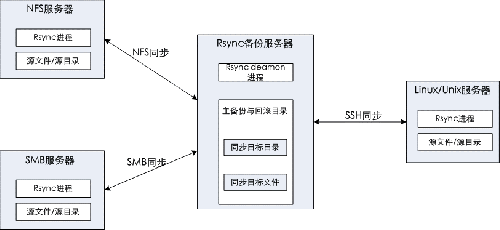
图 3.Rsync备份服务器体系结构
Rsync工具不仅提供了高效快速的增量同步算法,对于数据库备份还具备许多完善、灵活的功能特性:
- 支持备份更新目录和文件;
- 适合数据存储结构大文件的增量同步备份,减少备份传输耗时;
- 对多个同步文件内部以流水线减少文件等待延时;
- 支持多种网络环境下rsh、ssh、nfs、socket端口等传输方式,可灵活支持数据库的加密、压缩等文件特性;
- 适合数据库镜像备份,支持匿名传输;
- 支持数据库备份数据可灵活保持连接、文件属性、权限、设备以及时间等;
数据库备份思路
一个数据库的数据库备份必须是一个数据库的完整的映像,在这个映像的时间点上,没有部分完成的事务存在。因此,数据库备份设计方案必须要求数据库支持在某时刻数据库的静止状态或不会对数据镜像文件进行刷新,希望对数据库系统完成在线数据库备份操作,实现数据库系统高性能的应用级备份。
方案设计思路采用Rsync工具对备份数据库各节点的数据从生产数据库系统上进行增量同步,由于生产数据库系统和备份数据库系统是拓扑结构完全相同的两个环境,因此生产数据库和备份数据库之间节点存在相对应的关系。如果在对应节点之间建立起同步关系,只要保证每个节点上的表结构、数据、日志记录等保持一致,那么整个数据库系统环境总体的表结构、数据和日志等也会一致。整个备份方案设计流程分为备份初始化、增量同步备份、备份恢复。以此来实现数据库系统的在线备份,并支持应用系统通过网络对备份数据库系统的切换和请求。
备份方案设计
通过以数据库集群的在线备份为例对设计方案和实施流程进行说明。
数据库备份方案一般主要考虑到数据库系统备份、应用系统访问切换、ETL数据业务流程备份等,整体网络拓扑结构可简单如下图所示。

图4.整体网络拓扑图
备份系统之间网络为确保数据的及时性可采用局域网或城域网,一般推荐提供万兆以上专用网络。应用系统访问可采用HA专用网络设备或DNS软件技术等对备份数据库系统进行切换,同时ETL数据业务流程则通过对控制文件进行备份,确保业务在故障状态下对备份数据库系统的操作。最核心的数据库系统备份则需根据数据库集群系统的特点,以及Rsync备份服务器体系结构进行设计,其网络结构部署图如下。

图 5.数据库集群备份设计方案部署图
备份数据库系统在数据库集群服务器各节点上部署运行备份数据库集群软件和 Rsync Server程序,机器节点称为备份服务器。所有备份服务器节点需要启动Rsync守护(daemon)进程,等待客户端Rsync连接。同时,原生产数据库系统集群节点部署Rsync Client服务程序,为Rsync客户端服务器,在启动备份操作时向备份服务器发送同步请求。生产数据库系统在备份操作启动之前确保数据库系统处于静止状态,生产数据库集群节点与备份数据库集群节点采用一对一方式进行数据的增量同步备份。
实施流程

图 6.备份初始化流程
1、备份初始化
- 首先确认备份数据库集群软件系统环境的正常安装部署,并分别在生产数据库系统集群各节点和备份数据库系统集群各节点上部署Rsync软件环境,生产数据库集群为Rsync客户端,备份数据库集群为Rsync服务端。
- 检查和验证备份系统初始化前的网络环境,确认备份系统网络与生产网络环境的互通性,可以通过网络测试工具或网络命令方式进行验证。检查确认生产数据库集群状态是否正常。
- 待生产数据库系统进行状态确认一致后,对生产数据库系统集群模式设置为只读(静止)模式,生产数据库系统集群仅对外提供查询功能,不进行DDL、DML等数据更新操作,使其数据镜像文件处于静止状态,为备份初始化数据的初次同步做好准备。 首次备份初始化的时间点主要选定在生产数据库系统业务流程执行前的闲暇时间段来进行,根据业务系统的特点和备份数据量的预估,尽量减少对生产数据库集群业务流程执行的影响。
- 启动备份初始化同步程序,通过生产数据库系统集群与备份数据库系统集群之间万兆网络来进行数据同步。作为初始化备份同步方式采用SCP命令,主要是为了节省备份所需的备份时间和系统资源消耗。另外由于Rsync工具需要Rsync差分抽取算法支持,所以算法执行过程中会消耗更多的资源和通信代价,从而也使初始化备份的时间周期更长。 初始化同步时间可以通过以下计算公式评估得出。例:估算备份初始化数据量规模大小,例如为D(单位TB)。数据库系统环境由多个(N)集群节点通过SCP命令方式传输,同步数据到备份数据库系统各集群节点服务器上。按照网络传输同步速率为1TB/小时(考虑到网络利用率和数据在磁盘上落地时间等工程经验总结数值),初始化数据同步耗时=总数据量/节点数/网络传输速度(TB/小时)= D / N / 1(TB/小时),工程估算200TB初始化同步数据耗时为8小时左右。
- 确认备份初始化数据同步是否成功。如果成功,则修改生产数据库系统集群模式设置为正常模式,恢复生产数据库系统集群正常对外提供数据操作的能力。
- 启动备份数据库系统服务,验证备份数据库系统集群数据是否一致性。如果失败,则人工确认查找故障问题,重新进行初始化数据同步。
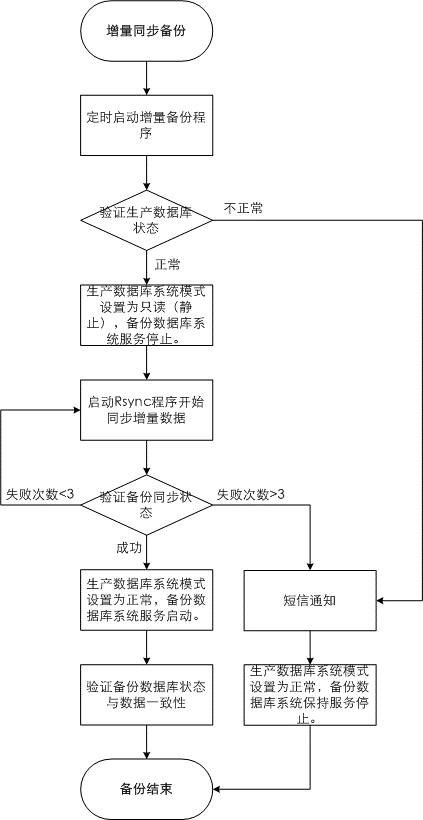
图 7.增量同步备份流程
2、增量同步备份

图8.备份恢复流程
3、备份恢复
- 当生产数据库系统集群产生故障时,首先停止该数据库集群服务,并将生产数据库系统脱离生产业务网络环境。
- 切换应用系统访问接口程序和ETL业务流程平台命令。应用系统访问接口程序通过HA专用网络设备或DNS软件技术对JDBC驱动连接字符串IP地址进行修改来切换,需要将原生产数据库系统的各服务节点IP地址替换为备份数据库库系统下各服务节点的IP地址。ETL业务流程平台则通过修改控制文件中对数据库环境的指定。
- 备份数据库系统集群对外提供生产业务服务,并重新执行上一个备份点后的数据加载和ETL业务流程过程,确保生产业务的连续性。
- 人工对生产数据库系统集群进行故障解决和恢复。
- 启动恢复后的生产数据库系统集群环境,并连接生产业务网络环境。按照备份数据库系统集群切换流程重新将应用系统访问接口程序和ETL业务流程切换到恢复后的生产集群环境上,切换流程与备份数据库系统相似。
- 恢复生产数据库系统集群环境后,还需对故障后所有的数据加载和ETL业务流程进行重新执行,确保生产集群的整体数据一致性和业务实时性。
方案优势及不足
基于Rsync算法的数据库备份设计方案实现了数据库系统的在线备份能力及应用级切换功能,主要优势在于:数据库备份过程中采用Rsync算法灵活高效的实现了数据库数据文件的增量备份,极大减少了日常备份所耗费的时间;方案可支持主流大多数Linux、Unix操作系统,并灵活地选择或设定备份数据文件及目录树;允许备份过程中对生产系统数据库进行查询统计操作;满足备份数据库系统的在线切换,且设计方案具有较高的性价比。
方案的不足之处在于数据库系统对每个集群节点的同步是完全独立于其它节点的,因此务必所有集群节点的增量备份成功,才能确保集群整体增量备份的成功。且生产系统数据库无法做到任意时间点的实时备份同步。
结束语
基于数据库的在线备份功能及技术一直是数据库产品研究的重点和难点。方案摒弃了传统关系型数据库采用日志备份的思路,对镜像数据文件进行增量备份的方式来实现。充分利用Rsync算法的优势和开源技术,结合分布式数据库的场景特点,提出了一种切实可行的备份设计方案。
作者: 伍艺 天津南大通用数据技术股份有限公司电信行业售前咨询顾问,主要负责电信行业MPP分布式数据库技术方案及项目管理。责编/刘亚琼
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

