【R】用 ggplot2 绘制漂亮的分级统计地图
最近我一直尝试利用R绘制地图,我从网上找到了上百种不同的实现方法,然而其中却没有适用于我的数据的方法。最终,我从以下几个博客【1】中找到了灵感。我在整合这些资源的基础上,通过不断的试验和修正得到了一个较好地解决方案。这个方案就是本篇博文的主要内容。
本篇博文中展示了如何利用 ggplot2 来绘制分级统计地图,同时还介绍了如何更改图例、颜色等参数指标,以及如何导出图像文件。
数据预处理
绘制分级统计地图需要一些软件包,你最好确认你的电脑中已经安装并加载了它们。我们利用 maptools 库中的 readShapeSpatial() 函数来读取形状数据。形状数据是储存了经纬度等地图信息的空间向量数据。好消息是,你可以免费下载这些数据!比如,你可以在这个网站中【2】下载全球各个国家的形状数据。
我的项目是对印度的数据进行绘图分析,所以我下载了印度的形状数据并将它们导入到 R 中。
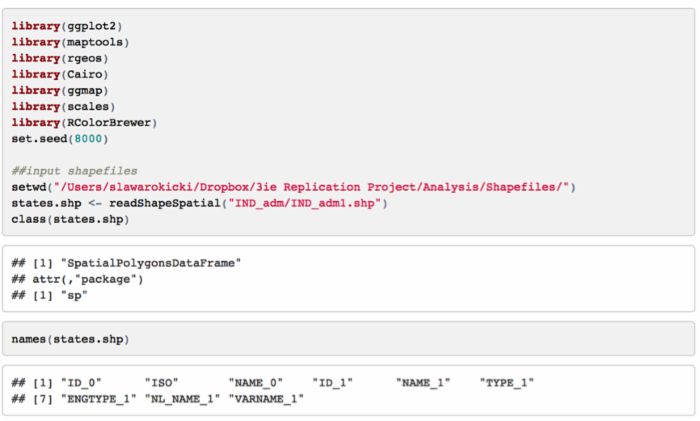
我们所导入的形状数据是一个空间类型的数据,我们可以检查它的变量名来观测它包含哪些内容。比如我们可以输出各个邦的名称:

现在我们已经得到目标数据。接下来我将会编造一些数据,你也可以导入 csv 格式的数据或者从你估计的模型中提取数据。最重要的一点是,新导入的数据中 id 号码必须和形状数据中的 id 一致,因为我们等会要合并这两个数据集。
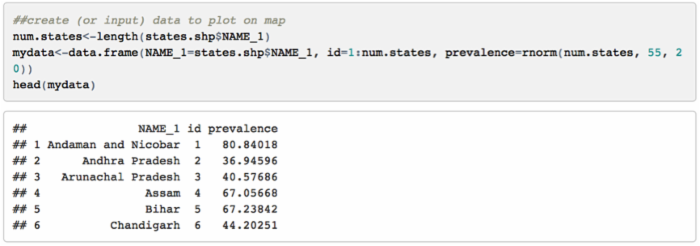
[译者注]此处代码有误,原数据的ID编码为1287-1321,所以“id=1:num.states”应改为“id=1286+(1:num.states)”。
现在我们需要整合形状数据和目标数据集。首先,我们利用 ggplot 中的 fortify() 函数将形状数据转换成数据框格式的数据。该函数可以根据特定的识别变量将数据转化成数据框格式。
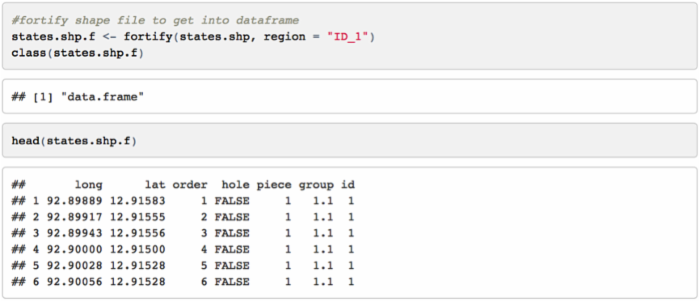
[译者注]此处显示的 ID 数据与原数据集的 ID 数据不一致。
我们可以看到这是一个常见的数据框格式的数据,其中列向量包含了经纬度数据。
接下来我们根据 ID 数据合并两个数据集,并保证空间数据集中没有缺失值。更重要的是,我们需要根据变量 order 对数据集进行排序。

基础绘图
我们准备利用 ggplot()、geom_polygon() 和 coord_map() 函数来绘图。
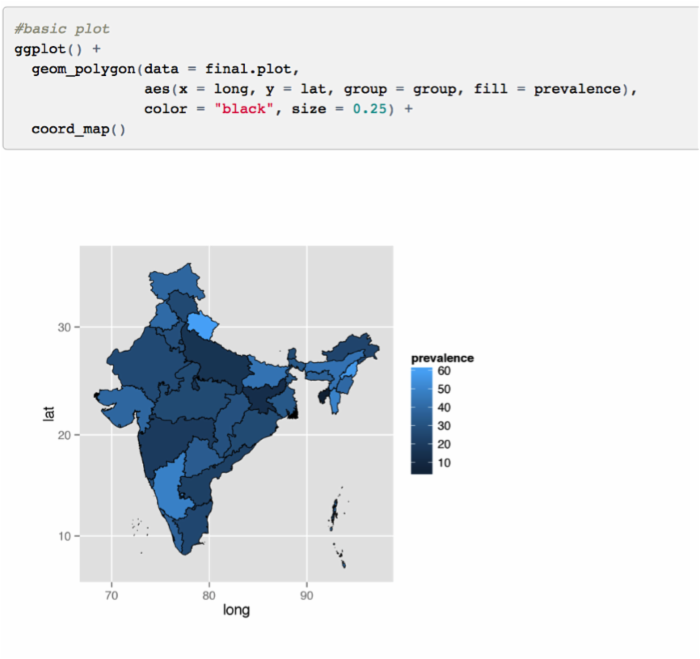
高阶绘图
上一部分只是绘图的开始,我们还可以通过调整其他参数使图形变得更漂亮。首先,我们可以利用 ggmap() 库中的 theme_nothing() 来删除背景和网格线,同时还需要设置 legend 的参数绘制图例。当然,我们还可以更改图例和整个图像的标题。
接下来,我们将配色改为“YlGn”(从黄色到绿色过渡)。你可以通过 display.brewer.all() 函数来观察具体配色情况。
我们也可以利用 scales 库中的 pretty_breaks() 函数来获取最佳分割点。如果你不喜欢 pretty_breaks() 的方法,你还可以通过 scale_fill_gradient() 来实现:scale_fill_gradient(name=”var”,limits=c(0,100),low=”white”,high=”red”)
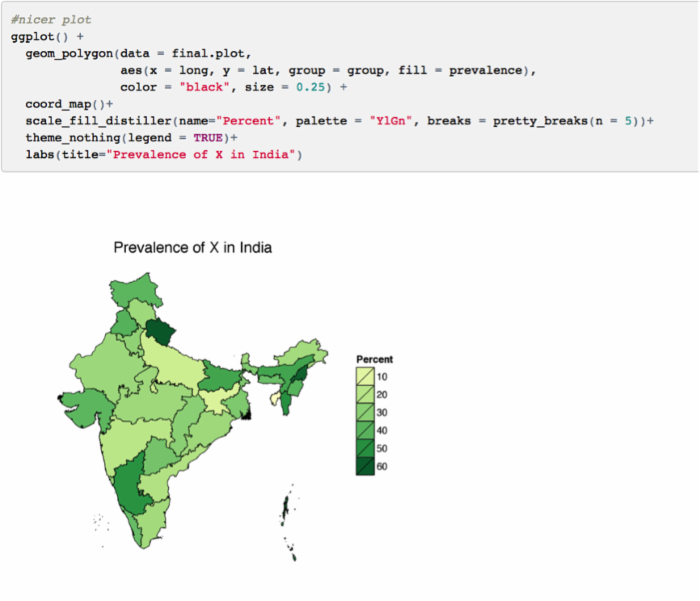
其他参数:
如果你想要将数值表示为暗色而不是亮色,那么你们可以在 scale_fill_distiller() 中加入 trans=”reverse”。
如果你面对的是离散型变量,那么你应该采用 scale_fill_manual() 函数:

此外,你还可以将各个邦的名称也绘制到地图上。首先,你需要识别出每个邦名对应的经纬度数据。本文中,我们利用 aggregate() 函数计算每个州经纬度取值范围的均值并作为对应邦名的坐标。
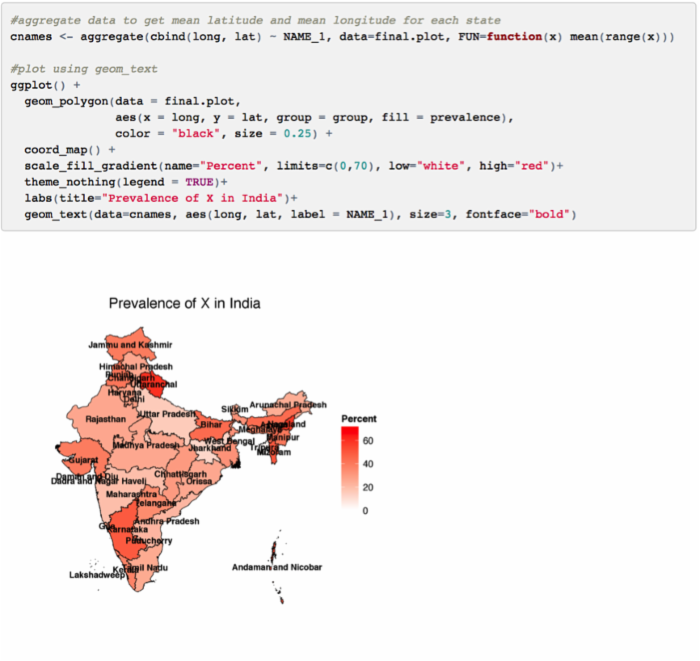
虽然这张图看起来有点乱,但是通过其他设置它将变得非常有用。当然你还可以利用 geom_text() 在地图中添加一些重要的识别信息。
导出地图数据
最后,我们可以用两种方法导出地图数据。
方法一:利用 Cairo 来导出地图。(MAC需要安装 X11)
首先我们将图像保存到对象中,然后利用 ggsave() 将该对象转化成 png 文件。
方法二:利用 pdf() 函数将对象保存为 pdf 文件

参考资料:
【1】 http://www.kevjohnson.org/making-maps-in-r/ ;
http://blog.revolutionanalytics.com/2009/11/choropleth-challenge-result.html
【2】http://www.diva-gis.org/gdata
原文链接:
http://rforpublichealth.blogspot.de/2015/10/mapping-with-ggplot-create-nice.html
原文作者:Slawa Rokicki
翻译:Fibears
正文到此结束
热门推荐










相关文章

近期评论
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

