python机器学习《回归 一》
唠嗑唠嗑
依旧是每一次随便讲两句生活小事。表示最近有点懒,可能是快要考试的原因,外加这两天都有笔试和各种面试,让心情变得没那么安静的敲代码,没那么安静的学习算法。搞得第一次和技术总监聊天的时候都不太懂装饰器这个东东,甚至不知道函数式编程是啥;昨天跟另外一个经理聊天的时候也是没能把自己学习的算法很好的表达出来,真是饱暖思**啊。额,好像用词不当,反正就是人的脑袋除了想着吃肉还要多运动运动,幸好的是每天晚上的瑜伽能够让自己足够沉下心来冷静冷静。回想起当初的各种面试,现在的自己毫无疑问能够很好的表达那些问题,但是很多时候贵在反应速度,所以自己虽然反应不迟钝,但是回答的不完美也是平时没有反复巩固知识的结果,不扯了,写笔记咯。
接着上一篇文章python机器学习《入门》
正文:
在前面的入门文章中主要介绍了机器学习任务重的两个算法:监督学习和非监督学习。其中,在监督学习中最重要的两个东西分别是回归和分类预测。这里,我们主要讲回归预测。上一节中,估计很多人看到一大堆文字描述就很头疼,表示这一节会尽量以例子讲解,其中例子的实现也是python编程求得结果哦。下一篇的文章将会具体的实现一个数据的爬取、分析以及训练最终预测流程。
1、回归的来源“回归”这一词的是达尔文的表兄弟发明的(天才都一家去了),话说这个表兄弟一开始是利用豌豆种子(双亲)来预测下一代的尺寸,后来就发现有一些规律可循,因此就观察到人类的遗传上面,发现如果双亲的身高比平均高度高的话,子女的身高也倾向于较高的高度,但不会超过双亲(话说这句话在我身边完美体现,害我苦恼为啥是家里最矮的)。这种现象即孩子的高度向着平均身高回退(回归)。虽然说数值预测与回退现象关系不是很大,但是人家是达尔文的表兄弟,所以就引用了人家的指定学术用名啦~
上一节我们讲到的房价月预测问题,实际上就是输入变量“房价”x并映射输出到一个连续的预期结果函数f(x)中。具体来说,假设我们有这么一群数据组合(x(i),y(i));其中i=1,...,m;也就是一共有m个数据组合样本,现在借助《机器学习实战》这本书给出的数据ex0.zip文件来实现该数据集的回归预测。
一、首先,在附件中下载并打开数据文件ex0.txt,观察到:

- 数据中的第一列都是1,那么很明显我们可以将后面的两列作为x,y值,虽然目前并不知道这些数据在实际应用中的名称。
- 所有的数据(列与列之间)的间隔都是tab符号分割,每一个样本数据各占一行,这方便我们后期的数据读取。
好的,分析数据,最方便的方式就是可视化数据,那么画个图看看数据的趋势如何:
1.1 准备数据:使用Python从文本文件中导入数据
创建名为“reg.py”文件,本节所有的代码都保存在该文件中;在画图之前,我们需要将准备一下,步骤包括:读取数据,将数据解析保存到矩阵中。代码如下:
1 # coding=utf-8 2 __author__ = 'wing1995' 3 4 5 from numpy import * 6 7 8 9 def file2matrix(filename): 10 f = open(filename) 11 contents = f.readlines() 12 length = len(contents) # 得到文件内容的行数 13 Mat = zeros((length, 3)) # 创建一个空矩阵用于存储文件内容 14 index = 0 15 for line in contents: 16 line = line.strip() # 去除每一行的换行符 17 data = line.split('/t') 18 Mat[index, :] = data # 将每一列数据按照行索引存放到空矩阵 19 index += 1 20 return mat(Mat) 好的,现在你有了矩阵,可以通过任何方式索引矩阵,例如索引第二列数据:
1 data_file = "C:/Users/wing1995/Desktop/machinelearninginaction/Ch08/ex0.txt" 2 dataMat = file2matrix(data_file) 3 print dataMat[:, 1]
ps:关于数据中的第一列数据为啥全是1后面会讲到,它属于默认的特征值x0。
1.2 分析数据:使用Matplotlib创建散点图
主要绘图用到了以下函数:
绘制用基本函数:plt.scatter(),plt.plot(),plt.bar()
自定义轴和标题函数:plt.xlabel(),plt.ylabel(),plt.title()
基本图形显示,清除函数:plt.show(),plt.clf()
具体函数的画法可以通过“help”命令查看,基础知识这里就不再赘述,直接在“reg.py”文件中添加画图函数:
1 def my_scatter(dataMat): 2 x = dataMat[:, 1] 3 y = dataMat[:, 2] 4 plt.xlabel('x') 5 plt.ylabel('y') 6 plt.scatter(x, y) 7 plt.show() 效果图如下:
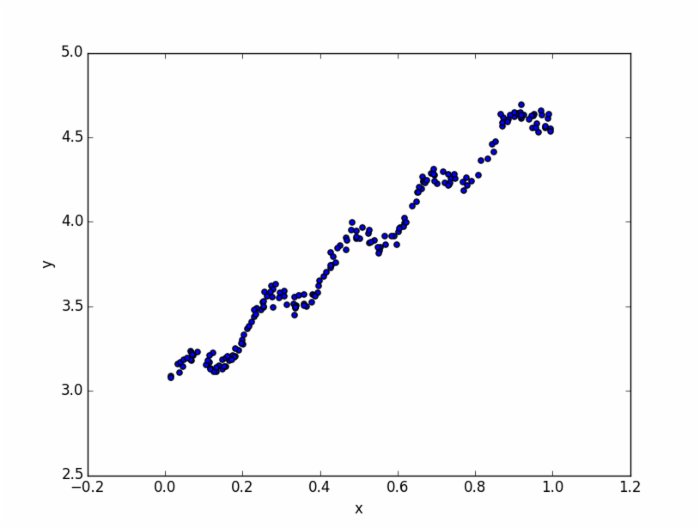
可以很明显的看得出来图片呈现上升的趋势,而且如果想用一条线来拟合该趋势的话,应该是一条直线。因此,我们给出拟合曲线的“假设函数”:
所谓的拟合,就是尝试建立并调用函数h(x),让输入数据x映射到输出结果y。以上样本有点大,举个小例子:
现在,随机猜测假设函数的两个参数theta0=2和theta1=2,此时假设函数h(x)=2+2*x。得到的映射结果如下:
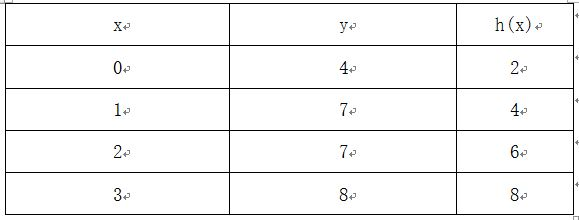
这样子是无法了解我们的假设函数是否能很好的预测y值。因此,有了“成本函数”这个概念。
成本函数J(theta):我们可以通过成本函数来衡量假设函数的精确度,这里的精度指的是预测值h(x)与真实值y之间的差值。由于样本量往往是大于一个的,因此需要将样本中的输入值x依次代入到假设函数中得到的函数值与实际值y作比较求得样本的预测误差的平均值,具体公式如下:
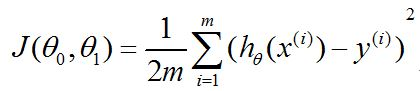
作为学数学的人,看这个就无比熟悉,工科的童鞋可能看公式不太习惯。通俗来讲,大家应该都知道平均值的定义,那么以上J(theta0,theta1)实际上就是1/2*M,这里的M就是误差平方的均值。其中m是指m个样本,例如上面表格中样本数据的m=4。这个成本函数的另外一个名字或许更为大家所知——“平方误差函数”或者“均方误差”,这里的均值减半也是梯度下降算法的简易实现,因为对平方求导得到的2会和这里的1/2抵消。还有一个问题是为啥当初设计误差的人不直接讲误差正负抵消而要做平方也是我一直没弄清的问题,上次研究图像处理的混合互补模型ROF中也有这么一个误差平方和的表示,导师问我为什么,我没回答出来,只觉得是固定的定义而已,希望知道的朋友解释一下。
有了这个成本函数,我们就可以根据上面的表格得出假设函数的拟合精度了,那么问题来了:前面的假设函数中theta值也是我们假设的,对于大样本数据,我们主观的给定theta的值很多时候拟合的精度都不够高。如何求解这个最优theta得到拟合效果最好的假设函数?
梯度下降算法:现在我们有了假设函数以及衡量它的精度的方式(成本函数)。现在需要一个方法来改善我们的假设函数,该方法即梯度下降法。
1.3 用python画个图让你们更好的理解这个代价函数J(theta)。1.3.1 编程实现计算代价函数
1 def computeCost(X, y, m, theta): 2 pre = X*theta # 预测值 3 s = 0 4 for i in range(m): 5 s += (pre[i] - y[i])**2 6 J = 1/(2*m)*s # 代价函数 7 return J 8 9 10 X = dataMat[:, 0:2] 11 y = dataMat[:, 2] 12 m = len(y) # 样本数量 13 theta = zeros((2, 1)) # 初始化theta 14 iterations = 1500 # 迭代次数 15 16 J = computeCost(X, y, m, theta)
上面的代码已经很好的实现代价函数的算法,由于我们的初始化theta值为0,因此J的初始值也是0,接下来需要运用梯度下降算法计算theta0和theta1,因此先上一个coursera上面布置的作业里面我用matlab画的图(数据不一样),后面贴python代码实现该类型图的画法:
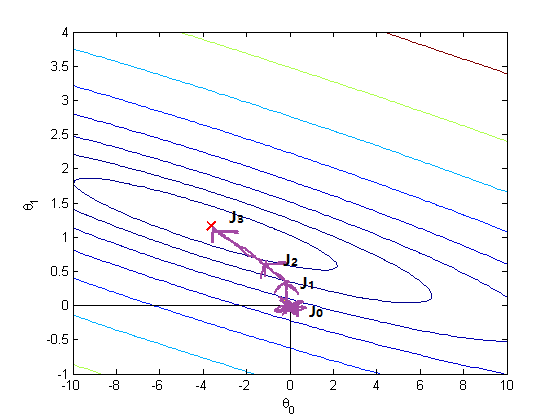
上图是theta0和theta1在整个迭代过程中收敛到最佳假设函数的情况(J0—>J3)这个过程就是初始值theta0=theta1=0到最优值J3的多次迭代的结果,上图的红叉叉就是J(theta)的一个全局最优解的对应的最优theta的值。此时,成本最小,最能预测结果;讲此时的theta代入到假设函数得到的假设函数正是我们需要的回归函数,拟合度最高。
从J0走向J1的这个过程就是成本函数J(theta0, theta1)分别对theta0和theta1求偏导,例如从J0走向J1的斜率就是theta0和theta1的偏导,就好比人走下坡路,斜率就是选择下坡的方向,角度;而theta0和theta1就是两个同时下坡的小人,迈开的步伐的大小就是学习速度alpha。因此两个小人能否走到坡底是由它们的初始位置(初始位置一半被初始化为0)和下坡的方向(偏导)以及下坡的步伐(学习速度alpha)所决定。
总的来说,梯度下降的公式为:
重复步骤,直至收敛:
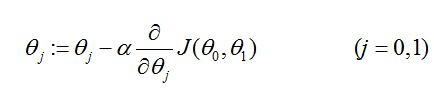
哎呀,看官可能看累了,接下来都有考试,就先写这么多,后面给出梯度下降算法的具体实现代码~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

