用 Ganglia 监控基于 Biginsights 的 HBase 集群性能
BigInsights 和 HBase 简介
InfoSphere BigInsights 是 IBM 集成和开发的一个大数据分析平台,同时具备可视化的管理界面。它能够帮助企业从海量的数据集中挖掘出潜在的商业价值,基于这些信息,企业能够以此或者有用的信息和做出正确的商业决策。如果使用传统的数据处理方式,不仅数据处理的效率低,而且容易丢失一些重要的数据信息。
BigInsights 包含了 Apache Hadoop 开源项目,同时集成了 IBM 自己开发的组件,这样的软件架构具有处理大数据的天然优势,可以满足企业开发和部署高可扩展的分布式计算平台的要求。它提供了简洁方便的 UI 界面,用户只需要通过界面简单修改配置,就能够轻松实现 Hadoop、HBase、Oozie、Hive 等各个组件的安装。同时,用户可以通过 UI 来查看各个组件的运行状态。
HBase 读写过程的简介
HBase 作为 BigTable 的一个开源实现,是 BigInsights 软件平台中重要的一个组成部分,HBase 是一个面向列的分布式数据库。HBase 不是一个关系型数据库,其设计目标是用来解决关系型数据库在处理海量数据时的理论和实现上的局限性。传统关系型数据库,以满足数据一致性(ACID)为目标,并没有考虑数据规模扩大时的扩展性。HBase 从一开始就是为 Terabyte 到 Petabyte 级别的海量数据存储和高速读写而设计,这些数据能够被分布到数千台普通服务器上,并且能够满足高并发的读写需求。
随着移动互联网,物联网(Internet of Things)等新兴应用业务的不断出现,HBase 的应用也变得越来越广泛。很多大型互联网公司,比如脸书、淘宝等都在 HBase 上有符合自己业务特征的应用和扩展,同时对 HBase 的发展也做出了自己的贡献,在这些贡献里面当然也包括 IBM 在内。大型的移动互联网公司在业务中面临的一个重要挑战就是大规模数据的实时写入与高效读取,随之而来的就是人们会越发关注 HBase 的读写性能。
往 HBase 写入数据的过程中,涉及到以下的一些步骤:
- 在开始写入的时候,需要创建一个表格。创建表格的时候,会在 HDFS 上面创建一个同名的目录,该目录下将生成第一个 region。Region 可以理解为将一个表格横向切割之后的一系列行数据的集合,region 中会以 family 名创建一个目录,这个目录下面存放具体记录数据的文件。同时,在该表表名目录下,会生成一个“compaction.dir”目录,该目录将在 family 名目录下 region 超过一定数量是用于合并 region;
- 当第一个 region 出现的时候,内存中最初被写入的数据将会被保存到该文件中,这个间隔是由“hbase.hregion.memstore.flush.size”决定的,默认是 64MB, 该 region 所在的 regionServer 的内存中一旦有超过 64MB 的数据时候,就将被写入到 region 中;
- 随着内存中的数据不断被写入到 region 中,文件不断增大,直到超过“hbase.hregion.max.filesize”决定的文件大小(默认是 256MB,此时加上内存刷入的数据 64MB+256MB), 该 reigon 将被 split,立即被一切为二,其过程是在该目录下创建一个名为“.split”的目录作为标记,然后由 Regionserver 将文件信息读取进来,分别写入到两个新的 region 目录中,最后再将老的 region 删除。
从 HBase 读取数据,主要分为以下两种情况:
- 首先来看第一种情况,表刚创建时,所有 put 的数据还在 memstore 中,并没有刷新到 hdfs 上。这个时候数据是在 memstore 中,并没有 storefile 产生,理所当然,hbase 要查找 memstore 来获得相应的数据。对于 memstore 或者 storefile 来说,内存中都有关于 rowkey 的索引的,所以对于通过 rowkey 的查询速度是非常快速的。通过查询该索引就知道是否存在需要查看的数据,已经该数据在 memstore 中的位置。通过索引提供的信息就很容易找得到所需要的数据。
- 还有一种情况就是检测到数据不在 memstore 中,则需要去 HFile 中查找,返回一个 merged 的数据给用户。
通过上述 HBase 读写过程的解析,我们可以看到 memstore 在读写过程中起到了非常重要的作用。所以在关注 HBase 高并发写入读取数据性能的时候,这些性能的指标很难被直观检测到,所以需要借助外部的一些工具来监控这些指标,以此来找出性能的瓶颈,并且对集群做出调优,使 HBase 的读写性能达到最佳。
回页首
利用 Ganglia 监控集群性能
随着数据中心的发展,对于计算机资源以及应用程序资源利用的监控比以往更加重要。Ganglia 是一个开源的监控项目,现在已经能扩展到监控数千节点的集群。每一台被监控的机器上都会运行一个叫 gmond 的守护进程,负责发送在本机上采集到的一些度量,比方说 CPU 的使用率、内存的使用情况、磁盘的使用等等。这个守护进程会将采集的这些信息发送给集群里面的一台主机,这台主机会接收所有的度量信息,将这些度量信息整合之后以可视化的界面展示给用户。gmond 守护进程的开销非常小,所以不会影响它所在机器的性能。
Ganglia 架构设计
图 1. Ganglia 架构和数据流

由图 1 可以看到,Ganglia 可以监控由好几个子集群结合起来的集群。gmond 与 gmetad 之间的关系相当于 Master-Slave 的关系,一个 gmetad 节点可以所属于一个或者多个 gmond 节点。在 gmetad 搜集到来自各个 gmond 节点的度量信息之后,通过 rrdtool 产生数据的走势图。最后通过 Web 的方式展现给用户。
gmond 有以下几个特点:
- gmond 可以等待 gmetad 亲自把采集到的数据取走,或者 gmond 采用广播的形式把自己的数据发送给其它的 gmond 节点,由其它的 gmond 把数据提交给 gmetad。
- gmond 节点之前的通讯方式是基于 UDP,而接收 gmetad 的轮询请求是基于 TCP 的(端口:8649)
在 BigInsights 集群中部署 Ganglia
本文使用 BigInsights 版本为 2.1.2,所属的 HBase 版本为 0.96。因为本文的重点是如何使用 Ganglia 来监控 BigInsights 中的 HBase 集群,所以将省略 BigInsights 的安装步骤,大家可以参考其它的文章来完成对它的部署。该集群由四个节点组成,如表格 1 所示。
表 1. BigInsights 集群信息
| 主机名称 | IP 地址 | 操作系统版本 |
|---|---|---|
| HMasterServer | 9.112.246.124 | Red Hat Enterprise Linux 5.9 |
| HRegionServer1 | 9.110.79.23 | Red Hat Enterprise Linux 5.9 |
| HRegionServer2 | 9.110.79.24 | Red Hat Enterprise Linux 5.9 |
| HRegionServer3 | 9.110.79.25 | Red Hat Enterprise Linux 5.9 |
安装完成之后在浏览器可以输入 URL:9.112.246.124:8080,即可登录 Biginsights 的 console,查看各个模块的状态信息。
本文 Ganglia 的安装都是基于离线安装的,所以需要安装一些依赖包,如表格 2 所示。
表 2. Ganglia 依赖包及安装包
| 依赖包 | 作用 |
|---|---|
| expat-2.0.1.tar.gz | 解析 XML |
| apr-1.4.5.tar.gz | Apache 可移植运行库 |
| apr-util-1.3.12.tar.gz | Apache 可移植运行库 |
| confuse-2.6.tar.g | 配置文件解析 |
| rrdtool-1.2.27.tar.g | 画图 |
| php-5.4.10.tar.gz | 支持 Ganglia 的 web 页面 |
| httpd-2.2.23.tar.gz | Apache 用于发布 web 页面 |
| ganglia-3.6.0.tar.gz | 度量数据的采集 |
| ganglia-web-3.5.10.tar.gz | 发布采集的度量信息 |
其中 php、Apache、ganglia-web 只需要在主节点上安装。主节点负责将从节点的度量信息,以 web 的方式展现给用户。
ganglia-web 是使用 php 编写的 web 界面,以图表的方式展现存储在 RRD 中的数据。通常与 gmetad 进程运行在一起。
清单 1. 主节点 ganglia-web 的安装与配置
tar -zxf ganglia-web-3.5.10.tar.gz cd /home/Ganglia/ganglia-web-3.5.10 cp conf_default.php conf.php vi conf.php $conf['gweb_confdir'] = "/home/Ganglia/ganglia-web-3.5.10"; $conf['gmetad_root'] = "/usr/local/ganglia";
清单 2. 主节点创建 ganglia-web 的临时目录
cd /home/Ganglia/ganglia-web-3.5.10/dwoo mkdir cache chmod 777 cache mkdir compiled chmod 777 compiled
清单 3. ganglia 在所有节点的安装与配置
tar -zxf ganglia-3.6.0.tar.gz cd ganglia-3.6.0 ./configure --prefix=/usr/local/ganglia --with-gmetad --enable-gexec --with-python=/usr/local
在安装完 Apache 和 PHP 之后,需要讲主节点采集到的信息通过 web 的方式发布出去,这里需要在 ganglia-web 上做一定的配置,在 httpd.conf 增加了如下部分内容:
清单 4. 主节点使用 Apache 发布 ganglia-web
Alias /ganglia “/home/Ganglia/ganglia-web-3.5.10" <Directory “/home/Ganglia/ganglia-web-3.5.10"> AuthType Basic Options None AllowOverride None Order allow,deny Allow from all </Directory>
为了能够使主从节点之间组成一个信息度量的采集集群,需要对主节点的 gmetad 进行配置,即修改“/etc/ganglia/gmetad.conf”文件,如清单 5。本文将所要监控的集群的名称叫做“moma-cluster”,这个集群里面包含了四个节点,同时指明了在主节点上度量信息存放的位置是“/usr/local/ganglia/rrds”,case_sensitive_hostnames 表示在集群里面,各个节点的名字的大小写是敏感的。
清单 5. 主节点配置 gmetad
data_source "moma-cluster" HMasterServer HRegionServer1 HRegionServer2 HRegionServer3 xml_port 8651 interactive_port 8652 rrd_rootdir "/usr/local/ganglia/rrds" case_sensitive_hostnames 1
需要对各个从节点上安装的 gmond 进行配置,即修改“/etc/ganglia/gmond.conf”文件,如清单 6。
清单 6. 从节点配置 gmond
cluster { name = "moma-cluster" owner = "nobody" latlong = "unspecified" url = "unspecified" } 在安装完所有这些服务之后,可以开始启动这些服务项,测试是否安装完成,主节点启动 apche 服务和 gmetad 服务,每一台从节点启动 gmond 节点。在启动完成之后,可以在浏览器中输入 URL: 9.110.246.124/ganglia,可以看到如图 2 所示的界面,其中包含了四个节点。
图 2. Ganglia 监控界面

回页首
GangliaMetrics 与 HBase 的集成
文本已经在上一节中介绍了 Ganglia 能够监控的指标,包括系统的 CPU、内存、DISK IO 等等,这些都是涉及的系统资源。通过 HBase 读写的简介,本文已经将读写过程中涉及到的一些重要参数做了介绍,这些参数的配置和调整在很大程度上影响到 HBase 的读写性能。如果只是从系统资源的利用率来衡量,很难将那些因为 HBase 内部机制而影响性能的因子挖掘出来,从而会影响性能的调优,所以需要 Ganglia 在监控与采集系统资源的同时,获得跟 HBase 本身机制相关的度量信息。
其实 HBase 本身已经实现了这些度量信息的采集,即通过对度量信息的采集接口发送给 Ganglia,下面将举例 RegionServerMetrics,详细说明这个实现过程。
图 3. HBase Metrics 架构设计
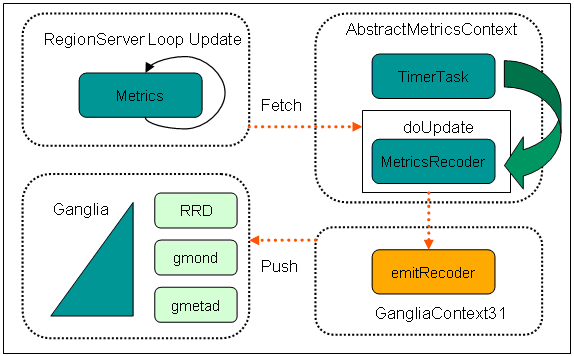
- RegionServerMetrics 根据 HBase 的 classpath(Biginsights 目录为主安装目录 /hbase/conf/ hadoop-metrics2-hbase.properties)的配置,创建一个 Context 实例,如清单 7 所示。
- RegionServerMetrics 实现了 metrics.Update 接口,实现了 doUpdater(MetricsContext) 的方法。
- RegionServerMetrics 的构造函数,会将自己注册到 GangliaContext31。
- 创建 MetricsRecord,加载到 GangliaContext31 里。
- 启动 startMonitoring() 过程。在 AbstractMetricsContext 里,是 TimeTask 来作为一个线程,周期性调用 doUpdater()。
- HRegionServer 周期性的执行 doMetrics() 方法。该方法只更新在 RegionServerMetrics 定义的 metrics 对象,周期性更新的间隔是由“hbase.regionserver.msginterval”决定
- GangliaContext31 获取 Metrics 的更新,然后发送给 Ganglia。该方法会将 MetricsRecord 发送给 Ganglia 的 gmond 或者 gmetad。过程的周期性间隔时间是由 hbase.sink.ganglia.period 来决定的
清单 7. 创建 Context 实例*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10 hbase.sink.ganglia.period=10 hbase.sink.ganglia.servers=9.110.246.124:8649
在完成 HBase Metrics 跟 Ganglia 结合的配置之后,重启 Biginsights 中的 HBase 集群,之后再次打开 Ganglia 的控制页面,就可以看到跟 HBase 相关的 metrics,如图 4 所示。
图 4. Ganglia 采集 HBase Metrics

回页首
Ganglia 监控 Biginsights 中的 HBase 集群读写性能
本文将结合车联网项目中的海量数据(GPS 数据,CAN 数据等)的读写案例,来说明如何使用 Ganglia 来监控 HBase 集群,从而发现 HBase 读写中的性能瓶颈,从而做出调整与优化,提升整个集群的性能。
本文采用多线程的方式,采取读文件的的方式来模拟大数据中持续不断的写入过程,从而来监控 HBase 在数据灌输中的各项指标,包括系统资源,以及 HBase 的各项指标。首先,本文将通过写数据的过程中发现的一个关于集群 CPU 消耗不均衡的问题来调整,经过优化与调整之后,实现集群的负载均衡。
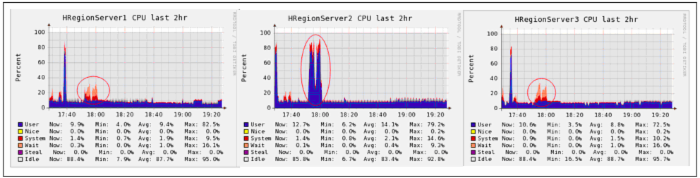
由图 5 可得,在高并发的数据写入过程中,三台 RegionServer 上的 CPU 使用率非常不均匀,写入的压力集中在 HRegionServer2 上,而且 HRegionServer1 和 HRegionServer3 的 iowait 值非常高。分析其原因,这是由于 HBase 本身的特性造成。在 HBase 里面,在表格刚刚创建的时候,只有一个 region,随着数据的不断写入,region 会被分割,然后集群会对这些 reigon 做一个调度。所以说,在 region 没有被分割的时候,会集中在某一台 server 上,也就是图 4 中的 HRegionServer2。因为 HBase 底层的存储机制是基于 HDFS,所以会存在冗余备份的过程,数据在写入到 HRegionServer2 的时候,同时会对它在其它节点上做备份写入操作,所以会造成 iowait 非常高。
图 5. Ganglia 监控优化之前的 CPU
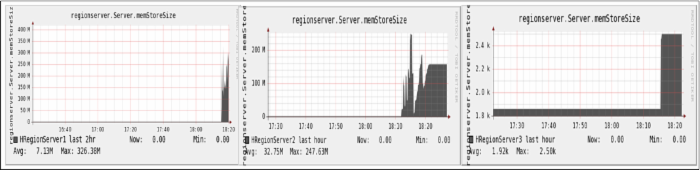
本文已经在第一节中介绍过关于 memstore 在整个 HBase 读写过程中的作用。通过 HBase Metrics 就可以实时监控整个指标,及时发现性能的瓶颈。HRegionServer1 和 HRegionServer2 在写入过程中的 memstore 的平均值分别是 7.3MB 和 32.7MB,而 HRegionServer3 的平均值只有 1.97KB,进一步说明了整个集群的写入是负载不均衡的。
图 6. Ganglia 监控 HBase Metrics
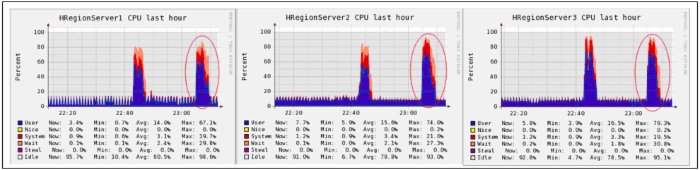
为了能够解决 CPU 使用率不均匀的问题,本文对 HBase 中 Rowkey 的设计上做了一个 region 的预划分,同时在数据的写入过程中,根据 GPS/CAN 数据的特点,做了一个动态的 region 的分配机制,最终实现了数据写入的负载均衡,如图 7 所示。
图 7. Ganglia 监控优化之后的 CPU
回页首
结束语
本文通过介绍 Biginsights 以及其中 HBase 的读写机制,引出在大数据读写过程中对性能监控的需求,Ganglia 是现在主流的监控集群的开源软件,能够满足对集群的系统资源的监控。但是这并不能采集 HBase 的一些度量信息,所以介绍了 HBase Metrics。本文最后通过车联网数据在 Biginsights 的写入案例,展示了如何使用 Ganglia 对整个集群性能以及 HBase Metrics 的进行性能监控,找到了数据写入的瓶颈,对此作出了优化,提升了整个集群的写入性能。
本文对于 Biginsights 或者是 HBase 读写性能的监控非常有指导意义,可以通过监控系统以及平台的指标来及时发现性能的瓶颈,做出调整与优化,最终提升数据的读写性能。
正文到此结束
- 本文标签: 配置 管理 解析 开发 apache Hadoop 数据库 expat 安装 大数据 Apache Hadoop 操作系统 update classpath tar Ganglia HMaster 开源项目 CTO 参数 目录 测试 HDFS IDE UDP 软件 linux 服务器 负载均衡 集群 HRegionServer 数据 TCP key 备份 ip 互联网 HBase 开源软件 时间 XML root 端口 压力 rrdtool UI 需求 实例 企业 PHP IBM 进程 confuse Region 多线程 DOM 开源 web tab 线程 apr
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

