自己手动编写一个简单的解释器 Part 6
之前几篇文章:
-
自己手动编写一个简单的解释器 Part 1
-
自己手动编写一个简单的解释器 Part 2
-
自己手动编写一个简单的解释器 Part 3
-
自己手动编写一个简单的解释器 Part 4
-
自己手动编写一个简单的解释器 Part 5
今天是个大日子:) “为什么?” 你可能会问。因为今天讲完括号表达式,然后再实现语法解释器对任意深层次,类似 7 + 3 * (10 / (12 / (3 + 1) - 1)) 这样嵌套括号表达式的解析之后我们就可以结束算术表达式部分的讨论啦。(嗯,差不多吧)
接下来就开始,没意见吧?
首先,我们调整语法以支持括号表达式。你应该在 Part 5 学过,表达式的基本单元使用了 factor 原则。在那篇文章中,整数就是我们拥有的唯一的基本单元。今天我们就要增加另一个基本单元--括号表达式。让我们开始学习吧。
下面是我们升级后的语法:

expr 部分和 term 部分和我们在 Part5 里面的一样。这里唯一改变的地方是在 factor 里面,这里的 LPAREN 代表左括号‘(’,RPAREN 代表右括号‘)’,两个括号中间的 expr 代表表达式。
下面是这个 factor 升级后的语法图解,里面包含了可选项。 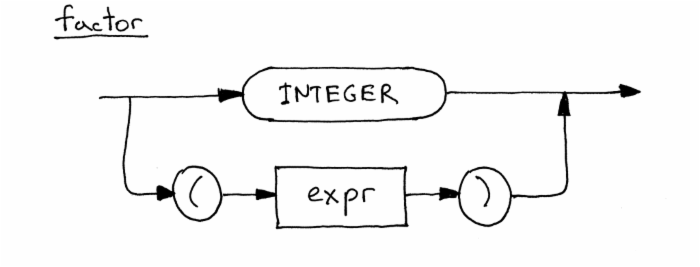
因为这个语法规则的 expr 和 term 两个部分没有改变,这个语法图解跟 Part5 里面的看起来一样:
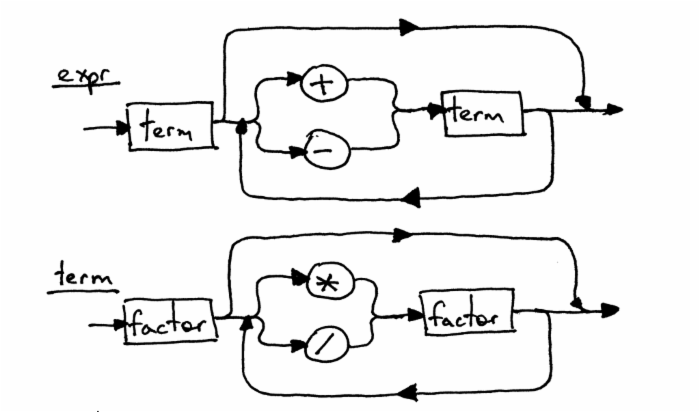
在我们新的语法里面有个很有趣的特点-递归性。如果你想于执行表达式2*(7+3),你需要从expr的起始符号开始,最终你需要再次回头执行原始表达式中的(7+3)。
让我们把2*(7+3)根据语法来进行分解,看看它是如何执行的:

说点题外话:如果你需要复习一下关于递归的知识的话,你可以看看 Daniel P. Friedman 和 Matthias Felleisen 合著的 The Little Schemer 这本书,讲的非常好。
好了,接下来让我们直接根据新的语法翻译代码。
根据前文对代码做的主要修改如下:
-
Lexer 修改成多返回两个令牌:LPAREN 代表左括号,RPAREN 代表右括号。
-
解释器的因子方法在除了整数意外的括号表达式方面有了略微的改进。
这是一份完整的可以处理任意深度嵌套的任意位数的加减乘除四则运算的计算机源代码:
# Token types## EOF (end-of-file) token is used to indicate that# there is no more input left for lexical analysisINTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, EOF = ( 'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', '(', ')', 'EOF')class Token(object): def __init__(self, type, value): self.type = type self.value = value def __str__(self): """String representation of the class instance. Examples: Token(INTEGER, 3) Token(PLUS, '+') Token(MUL, '*') """ return 'Token({type}, {value})'.format( type=self.type, value=repr(self.value) ) def __repr__(self): return self.__str__()class Lexer(object): def __init__(self, text): # client string input, e.g. "4 + 2 * 3 - 6 / 2" self.text = text # self.pos is an index into self.text self.pos = 0 self.current_char = self.text[self.pos] def error(self): raise Exception('Invalid character') def advance(self): """Advance the `pos` pointer and set the `current_char` variable.""" self.pos += 1 if self.pos > len(self.text) - 1: self.current_char = None # Indicates end of input else: self.current_char = self.text[self.pos] def skip_whitespace(self): while self.current_char is not None and self.current_char.isspace(): self.advance() def integer(self): """Return a (multidigit) integer consumed from the input.""" result = '' while self.current_char is not None and self.current_char.isdigit(): result += self.current_char self.advance() return int(result) def get_next_token(self): """Lexical analyzer (also known as scanner or tokenizer) This method is responsible for breaking a sentence apart into tokens. One token at a time. """ while self.current_char is not None: if self.current_char.isspace(): self.skip_whitespace() continue if self.current_char.isdigit(): return Token(INTEGER, self.integer()) if self.current_char == '+': self.advance() return Token(PLUS, '+') if self.current_char == '-': self.advance() return Token(MINUS, '-') if self.current_char == '*': self.advance() return Token(MUL, '*') if self.current_char == '/': self.advance() return Token(DIV, '/') if self.current_char == '(': self.advance() return Token(LPAREN, '(') if self.current_char == ')': self.advance() return Token(RPAREN, ')') self.error() return Token(EOF, None)class Interpreter(object): def __init__(self, lexer): self.lexer = lexer # set current token to the first token taken from the input self.current_token = self.lexer.get_next_token() def error(self): raise Exception('Invalid syntax') def eat(self, token_type): # compare the current token type with the passed token # type and if they match then "eat" the current token # and assign the next token to the self.current_token, # otherwise raise an exception. if self.current_token.type == token_type: self.current_token = self.lexer.get_next_token() else: self.error() def factor(self): """factor : INTEGER | LPAREN expr RPAREN""" token = self.current_token if token.type == INTEGER: self.eat(INTEGER) return token.value elif token.type == LPAREN: self.eat(LPAREN) result = self.expr() self.eat(RPAREN) return result def term(self): """term : factor ((MUL | DIV) factor)*""" result = self.factor() while self.current_token.type in (MUL, DIV): token = self.current_token if token.type == MUL: self.eat(MUL) result = result * self.factor() elif token.type == DIV: self.eat(DIV) result = result / self.factor() return result def expr(self): """Arithmetic expression parser / interpreter. calc> 7 + 3 * (10 / (12 / (3 + 1) - 1)) 22 expr : term ((PLUS | MINUS) term)* term : factor ((MUL | DIV) factor)* factor : INTEGER | LPAREN expr RPAREN """ result = self.term() while self.current_token.type in (PLUS, MINUS): token = self.current_token if token.type == PLUS: self.eat(PLUS) result = result + self.term() elif token.type == MINUS: self.eat(MINUS) result = result - self.term() return resultdef main(): while True: try: # To run under Python3 replace 'raw_input' call # with 'input' text = raw_input('calc> ') except EOFError: break if not text: continue lexer = Lexer(text) interpreter = Interpreter(lexer) result = interpreter.expr() print(result)if __name__ == '__main__': main() 将上面的代码保存为 calc6.py ,测试一下,看看你得新解释器能不能正确处理不同操作符已经任意嵌套深度的算术表达式。
一个简单的 python 会话:
$ python calc6.py calc> 3 3 calc> 2 + 7 * 4 30 calc> 7 - 8 / 4 5 calc> 14 + 2 * 3 - 6 / 2 17 calc> 7 + 3 * (10 / (12 / (3 + 1) - 1))22 calc> 7 + 3 * (10 / (12 / (3 + 1) - 1)) / (2 + 3) - 5 - 3 + (8)10 calc> 7 + (((3 + 2)))12
下面是今天为你准备的个小练习 
-
按照本文讲解的方法编写一个自己的算数表达式解析器。记住:重复练习是所有学习方法之母。
嘿,你已经一路看到最后了!恭喜你,你已经学会了如何创建(如果你做了所有的练习-真的编写过)一个简单的可以执行很复杂算术表达式的递归文法文法分析器/解析器。
下一篇文章中我将讲解更多关于递归文法分析器的细节。我也会介绍一个整个系列都会用到,而且在解析器和编译器中都非常重要且运用广泛的数据结构。
敬请期待。在那之前请你继续练习编写你的解析器。更重要的:享受乐趣享受过程!
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

