无处不在的等待


11月03日,由Oracle 资深DBA彭小波老师在“DBA+东北群”进行了一次关于“无处不在的等待”的线上主题分享。小编特别整理出其中精华内容,供大家学习交流。 Latch:cache buffers lru chain 等待事件
“DBA+社群”东北联合发起人。从事Oracle 数据库技术十余年,ACOUG核心成员,Oracle用户组年轻专家。现就职于某金融保险公司,曾服务于航天、航空、机车、大型制造行业数据库的维护以及系统开发,擅长Oracle数据库架构规划、SQL优化、OWI方面性能的优化。
数据库性能优化是一个神秘而又古老的话题,之所以说神秘是因为,一个困扰大家的SQL,在DBA的调整后,性能能提升百倍,甚至千倍。在外行看来,就像魔术师变魔术一样。古老是因为,当我们使用接触数据库那天起,甚至一些Oracle业界的技术大牛都在一直在孜孜不倦的研究数据库性能优化,如果想做个出色的DBA,数据库性能优化会伴随着我们整个职业生涯。
我想用一句话概括数据库优化,优化是数据库体系结构的延续,数据库的结构和运行的机制决定了数据库的优化模式,所以说数据库的体系是优化的基石。当你把数据库体系结构学明白了,优化是水到渠成。反过来,我们通过优化数据库,进一步的深入学习数据库的体系结构。
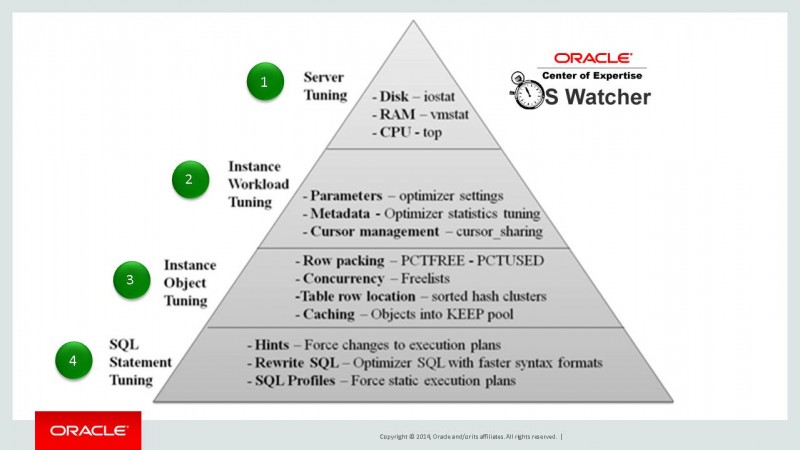
从这张图上我们看到数据库优化的主要方向大致分四部分(注:这里不讲主机,网络,存储等方面的优化):
-
资源的优化
-
实例的优化
-
SQL的优化
-
数据库的优化
Oracle社区中也提供了一个监控主机性能方面的一个小工具,OS Watcher。关于OS Watcher的使用我们可以参考MOS文档 ID 1614397.1。数据库各个方面都有优化的余地,主要有上面写的四大部分。其中SQL优化又是重中之重。
优化数据库的主要步骤:
1.设立优化目标和优化的方向。
2.采集数据库的信息。
3.修改数据库的配置。(注:这里不是指简单的修改数据库参数)
4.再次采集数据库信息。
那么,我们用现实生活中的例子来说明。
请你想一下你到医院看病的情况:
医生问你哪里不舒服,在数据库中就是确定优化的方向。医生给你测量体温,在数据库中就是收据数据库的信息。医生根据你的体温判断你发烧了,在数据库中就是根据收集的信息判断数据库问题所在。医生给你吃退烧药,在数据库中就是修改数据库配置。医生再次测量体温,达到预期效果,在数据库中就是达到了我们的优化指标。
优化是无止境的,达到预期就可以,用户能接受就可以。数据库有优化的向导(ADDM,STA,SPA),做的就是我上面写的事情。向导是死的,我们人是活的,千万不能刻舟求剑。我们要根据自己的实际情况来变化。
在Oracle9i及之前,我们已经拥有了很多很好用的性能分析工具,比如,statspack,sql_trace、set event 10046&10053等等。这些工具能够帮助DBA很快的定位性能问题。但这些工具都只给出一些统计数据,然后再由DBA们根据自己的经验进行优化。那能不能由机器自动在统计数据的基础上给出优化建议呢?
Oracle10g中就推出了新的优化诊断工具:数据库自动诊断监视工具(Automatic Database Diagnostic Monitor ADDM)和SQL优化建议工具(SQL Tuning Advisor STA)。这两个工具的配合使用,能使DBA节省大量优化时间,也大大减少了系统宕机的危险。简单点说,ADDM就是收集相关的统计数据到自动工作量知识库(Automatic Workload Repository AWR)中,而STA则根据这些统计数据,给出优化建议。
在Oracle 9i以前,当一个系统出现了明显的性能问题时,首先做一个statspack快照,等30分钟,再做一次。分析报告,在top 5 events里面发现’ cursor: xx wait ’事件。根据经验,这个事件可能是因为shared pool 中 cursor 的版本数变得过多,过多的硬/软分析,过多的无效/重新加载,加载了大量的对象,shared pool 大小不合适,资源的持有者被 OS 或者 Resource Manager 从 CPU 上移除内存的操作系统管理(例如 Linux x86-64 上非常大的 SGA,而没有实施 Hugepage),代码缺陷等等引起的。
根据这些经验,我们需要逐个来定位排除,比如查看语句的查询计划、查看user_tables的last_analysed字段,检查热块等等步骤来最后定位出原因,并给出优化建议。但是,有了STA以后,它就可以根据ADDM采集到的数据直接给出优化建议,甚至给出优化后的语句。

Why is my sql Slow,给我们引出了一个问题,为什么我们的SQL会慢哪?当这个问题迎面而来的时候,我想当大家会给出有各种答案。服务器资源不足,应用程序复杂多变,网络原因,SQL写的不好,数据库本身的问题,等等......
那么我想说的是,SQL慢,70%,80%是由于SQL写的不好。SQL的问题。不过,不完全是SQL问题,要具体问题具体分析,分析后才能给出正确的答案。
如果SQL写的不好,SQL慢,会引起大量等待时间,一条SQL慢有时甚至能拖垮整个数据库,导致数据库宕机。
最初Oracle 7.0中有104个等待事件,Oracle 8.0中有140个等待事件,Oracle 8i中有220个等待事件,Oracle 9i中有400个等待事件,Oracle 10g中有800个等待事件,随着版本的提升等待事件一路攀升。这也意味着oracle正向准确报告性能问题发展,性能问题更加细粒度化,当发现等待事件时能快速的定位问题。
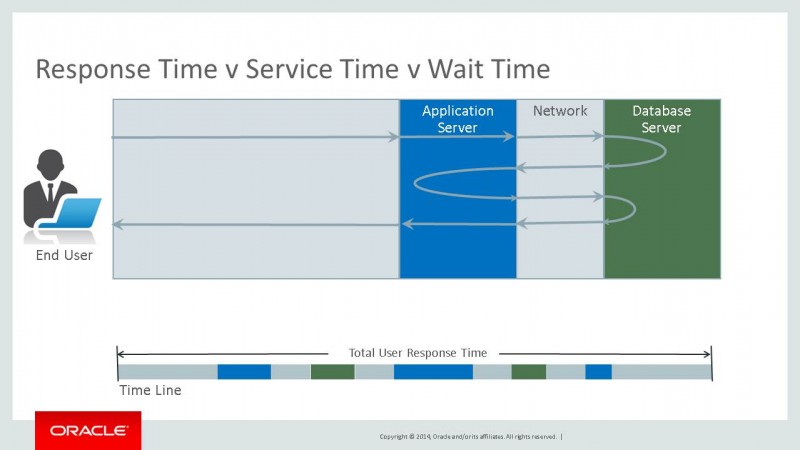
这是一个典型三层架构的应用系统。它讲解了一个用户请求业务的整个流程。首先当用户在应用端发出请求,经过网络,到达应用,应用在经过网络,请求数据库查询数据。反反复复大约经历10个步骤才把数据返回给最终用户。Response Time = Service Time + Wait Time,每个环节都存在影响性能的因素。只要降低工作时间和等待时间,响应时间自然随之降低,有些问题只要降低工作时间,等待时间自然也会降低,但是有些时候,不能降低工作时间,这是只有降低等待时间一种方法。
从这里引入我们今天的主题,《无处不在的等待》,在Oracle世界里,Oracle是一个巨大的同步机,许多进程可以同时使用同一个资源,如果没有保护资源的精确的同步机制,资源的一致性将遭到破坏。Oracle利用Latch和Lock这两种同步机制保护资源。
Latch:cache buffers chains 等待事件
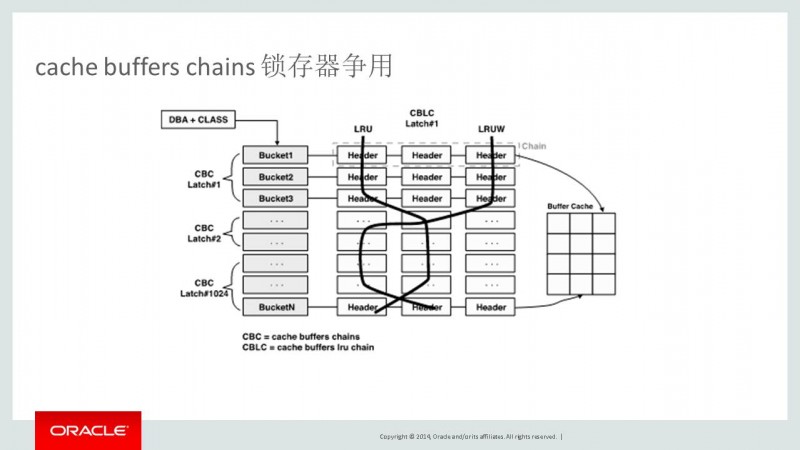
一、产生的背景:
Oracle为了将物理IO最小化,把最近使用过的数据块保持在内存中。为了管理这些内存,oracle 使用如图的结构,Hash Chain的结构,Hash Chain位于共享池中,使用典型内存结构Bucket->Chain->Header结构进行管理。Hash Chain结构的起点是Hash表,Hash表由多个hash bucket组成,块地址 是由file#+block#组成的,当扫描块时使用Hash函数进行hash运算,使用hash值查找hash bucket,具有相同hash值的buffer haeder在hash bucket上以chain形式链接。
Buffer header有指向实际缓冲区的指针。注意:Hash Chain结构是在共享池中,而实际缓冲区信息存储在高速缓冲区中。Hash Chain结构利用cache buffers chain Latch来保护。当进程扫描特定的数据块时,必须获得相应数据块所在Hash Chain管理的cache buffers chain Latch。基本上一个进程获得仅有的一个cache buffers chain Latch,一个cache buffers chain Latch管理多个Hash Chain。
当多个进程同时检索Buffer Cache时,获得cache buffers chain Latch的过程中发生争用,就会产生cache buffers chain Latch等待事件。
使用SQL语句可以获得hash_latches,hash_buckets数量,因此一个锁存器保护Bucket数量是1048576/32768=32个。
SQL> select x.ksppinm name,
2 y.ksppstvl value,
3 y.ksppstdf isdefault,
4 decode(bitand(y.ksppstvf, 7),
5 1,
6 'MODIFIED',
7 4,
'SYSTEM_MOD', 8
9 'FALSE') ismod,
10 decode(bitand(y.ksppstvf, 2), 2, 'TRUE', 'FALSE') isadj
11 from sys.x$ksppi x, sys.x$ksppcv y
12 where x.inst_id = userenv('Instance')
13 and y.inst_id = userenv('Instance')
14 and x.indx = y.indx
15 and x.ksppinm like '%db_block_hash%'
16 order by translate(x.ksppinm, ' _', ' ');
NAME VALUE ISDEFAUL ISMOD ISADJ
--------------------------------------------- --------------- -------- -------- --------
_db_block_hash_buckets 1048576 TRUE FALSE FALSE
_db_block_hash_latches 32768 TRUE FALSE FALSE
二、产生的原因:
1.执行效率低下的SQL,低效的SQL语句是发生Latch:cache buffers chains 争用的主要原因。发生在多个进程同时扫描大范围的表或索引时。
2.出现热块hot block时,由于编写SQL语句时,SQL持续扫描少数特定块(between and ,in,not in, exists),多个会话同时执行SQL语句时,发生Latch:cache buffers chains 争用。
--1.创建测试表
create table t1(id int,name varchar2(10));
insert into values(1,'xiaobo');
commit;
--2.获取t1表的第一行数据及ROWID,根据dbms_rowid包查出这行数据的文件号、块号
SQL> select rowid,
dbms_rowid.rowid_relative_fno(rowid) file#,
dbms_rowid.rowid_block_number(rowid) block#,
id,
name
from emm.t1
where rownum = 1; 2 3 4 5 6 7
ROWID FILE# BLOCK# ID NAME
------------------ ---------- ---------- ---------- --------------------
AAADfaAAFAAAACDAAA 5 131 1 xiaobo
注意:这里的DBA(Data Block Address)就是由5号文件和131号块组成
--3.根据DBA获取CBC Latch的地址
SQL> select hladdr from x$bh where file#=5 and dbablk=131;
HLADDR
----------------
00000001D1C266D8
--4.根据CBC Latch的地址可以查出这个CBC Latch被获得的次数
SQL> select addr,name,gets from v$latch_children where addr='00000001D1C266D8';
ADDR NAME GETS
---------------- -------------------------------- -----------------------------------------------
00000001D1C266D8 cache buffers chains 46
--5.再次读取t1表的第一行数据,再次产生一次逻辑读
SQL>select id,name from emm.t1 where rowid='AAADfaAAFAAAACDAAA';
ID NAME
-------- ------------
1 xiaobo
--6.CBC Latch的次数变为48,说明一次逻辑读产生两次CBC Latch
SQL> select addr,name,gets from v$latch_children where addr='00000001D1C266D8';
ADDR NAME GETS
---------------- -------------------------------- -----------------------------------------------
00000001D1C266D8 cache buffers chains 48
这里说明一次逻辑读要加两次CBC Latch,一次为了加Buffer Pin,一次为了释放Buffer Pin!但是我不知道这里如何通过实验来证明,大家如果有好的建议,可以联系我。
使用oradebug跟踪cache buffers chains Latch争用事件
SQL> oradebug setmypid
Statement processed.
SQL> oradebug peek 0x1D1C266D8 4 -- 观察CBC Latch地址为0x1D1C266D8开始之后的4字节信息的值为0
[1D1C266D8, 1D1C266DC) = 00000000
SQL> oradebug poke 0x1D1C266D8 4 1 --修改CBC Latch地址为0x1D1C266D8开始的4字节信息的值为1,相当于获取了Latch
BEFORE: [1D1C266D8, 1D1C266DC) = 00000000 --修改前的值
AFTER: [1D1C266D8, 1D1C266DC) = 00000001 --修改后的值
--7. 再开一个新的会话,会话号为768
SQL> conn / as sysdba
Connected.
SQL> select sid from v$mystat where rownum=1;
SID
----------
768
--8.在新会话768下再查询T1表的第一行,我观察到不会堵塞。但是我看网上有些网友写的博客说这里会产生堵塞。
这样的说法是不正确的。原因我会做完下个实验给大家解释。(这里多说一句,大家看到网上的一些技术文章,一定要自己动手做实验。如果发现和文章说明的不一样,一定要查阅资料,一直到搞清楚为止)
SQL>select id,name from emm.t1 where rowid='AAADfaAAFAAAACDAAA';
ID NAME
-------- ------------
1 xiaobo
--9.我们回到oradebug的会话,这次我们不是使用select语句,而使用update语句来获取latch
SQL> update emm.t1 set id=2 where rowid='AAADfaAAFAAAACDAAA';
1 row updated.
--10.再次使用oradebug模拟获取latch
SQL> oradebug setmypid
Statement processed.
SQL> oradebug poke 0x1D1C266D8 4 1
BEFORE: [1D1C266D8, 1D1C266DC) = 00000000
AFTER: [1D1C266D8, 1D1C266DC) = 00000001
--11.回到刚才768会话下,查询T1表的第一行,这时我观察到产生了堵塞
SQL>select id,name from emm.t1 where rowid='AAADfaAAFAAAACDAAA';
--12.我们再开第三个会话,查看会话号768的等待事件,我们看到产生了CBC Latch的等待事件
SQL> select sid,event,p1raw,p2raw,p3raw from v$session where sid=768;
SID EVENT P1RAW P2RAW P3RAW
---------------- ------------------------------------- ------------------------- --------------------------- -------
768 latch: cache buffers chains 00000001D1C266D8 00000000000000B1 00
最后在第一个会话中释放lacth
SQL> oradebug poke 0x1D1C266D8 4 0
BEFORE: [1D1C266D8, 1D1C266DC) = 00000001
AFTER: [1D1C266D8, 1D1C266DC) = 00000000
三、总结:
在获取保护hash bucket的cache buffers chains latch时,如果是读取工作(select),就以shared模式获得(这也是我们刚才在实验中select时没有产生争用的原因)。如果是修改工作(update),就以exclusive模式
获得。

--创建测试表
create table t1 (id number,name char(20));
--添加测试数据
begin
for i in 1 .. 100000 loop
insert into t1 values (i, ‘pxboracle');
end loop;
commit;
end;
--开10个会话,其中表t1有几万行的数据,同时运行,立刻查询上面的语句
declare
v1 t1.id%type;
begin
for n in 1 .. 100 loop
--外循环100次
for k in 1 .. 100 loop
--内循环100次
select count(*) into v1 from t1; --每次取表的函数到变量
end loop; --内循环结束
dbms_lock.sleep(1); --内循环每次完成后休息1秒钟
end loop; --外循环结束
end;
/
这里多说一句,我们可以使用jobs同时模拟多个线程跑脚本。
--不断的执行下面SQL
SQL> select name,gets,misses from v$latch where name='cache buffers chains';
NAME GETS MISSES
------------------------------------------ ---------- ----------
cache buffers chains 68121210 6701801
我们不断的运行上面的SQL,观察到misses迅猛的增加。比原来增加600万次的misses!
我们要定位热点的对象--找到哪些misses的比较多。如果100000选出来的太多,请加大misses值
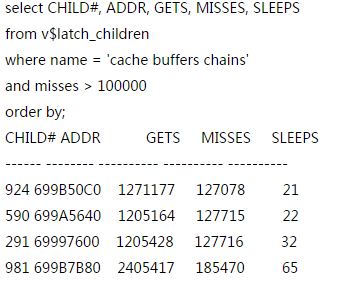
--根据addr的列,找到文件号和块号,再找到对象。这个addr和x$bh下的hladdr对应!

其中scott.t1表是我们自己的业务表。有9个块,因为我们只取了前几位的地址。可以判断scott.t1为热点。虽然t1表在内存中,我们可以命中,但要读取,还要通过latch,如果应用太集中,都访问一个表,必然造成这个结果。现在不是内存小了,而是访问模式太集中了,现象为cpu的负载过高。latch丢失严重。解决的办法为分散应用,增加减少索引!
SQL> create bitmap index scott.i1 on scott.t1(deptno);
索引已创建。
SQL> select name,gets,misses from v$latch where name='cache buffers chains';
NAME GETS MISSES
------------------------------------------ ---------- ----------
cache buffers chains 131912045 12869688
--现在我们再次在10个会话中运行刚才的测试程序。等结束后再次查询。
NAME GETS MISSES
------------------------------------------ ---------- ----------
cache buffers chains 132112739 12869695
发现只有极少的增加,可以忽略不计。原来增加了600万的misses.
从这个小实验,我们懂得了什么是热点块。通过改变sql的运行来改变热点。
刚才找到热点的块的方法是把地址先取出来,再查询。为了方便读懂程序!


这两个程序的结果一样,但效率不同!
Latch:cache buffers lru chain 等待事件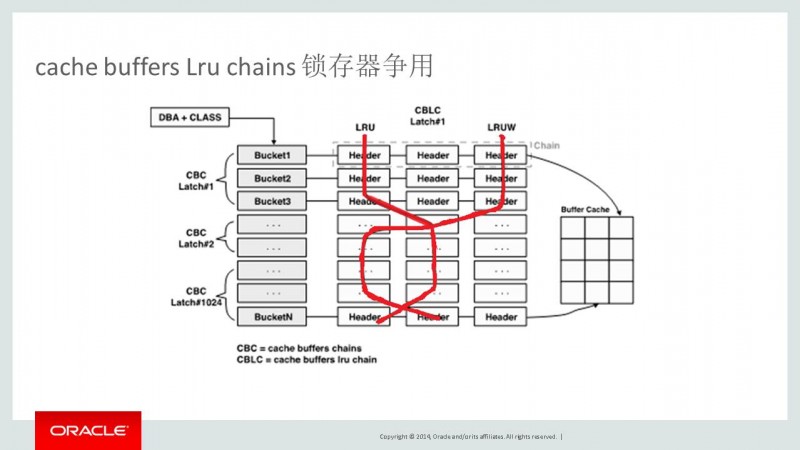
一、产生背景:
1、进程读取还没有加载到内存上的块时,查询LRU列表分配到所需要空闲缓冲区,在此过程中需要cache buffers lru chain Latch 。
2、DBWR进程为了将脏缓冲区记录到数据文件上,查询LRUW列表,将相应缓冲区移动到LRU列表的过程也需要cache buffers lru chain Latch 。
二、产生的原因:
cache buffers lru chain latch争用最重要的原因是过多请求空闲缓冲区,效率低下的SQL语句是过请求空闲缓冲区的典型情况,若多个会话同时执行效率不高的SQL,则查询空闲缓冲区过程中和记录脏缓冲区的过程,为了获取cache buffers lru chain latch发生争用。
cache buffers chain latch 和cache buffers lru chain latch争用的区别是,若多个会话同时扫描一个表或索引时,则发生cache buffers chain latch概率高,因为对相同的chain发生争用。若多个会话同时扫描不同的表和索引时,则发生cache buffers lru chain latch概率高,对个会话将各个不同的数据块载入到内存过程中,要请求过多的空间缓冲区,如果数据修改频繁,DBWR需要快速将脏缓冲写入到数据文件上,所以cache buffers lru chain latch争用加大。

如果你在系统中经常看到以上几点,说明数据库的性能和Shared Pool和Library Cache 等待事件有关。
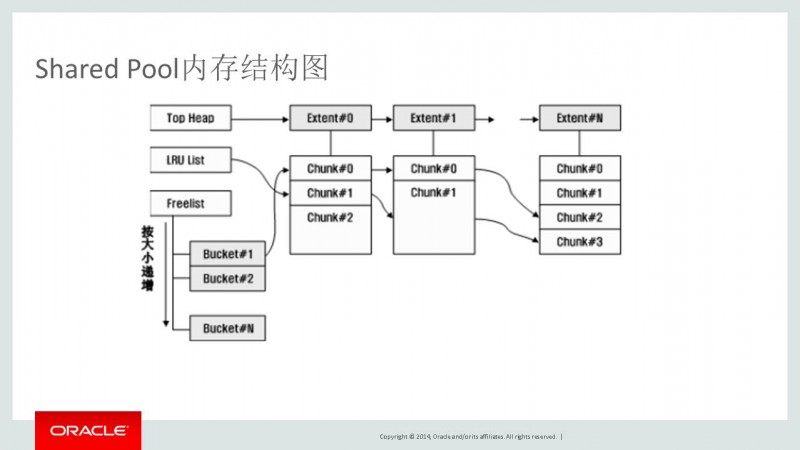
Oracle 在SGA的一个特定区域中保留SQL语句, packages, 对象信息以及其它一些内容,这就是大家熟悉的shared pool。这个共享内存区域是由一个复杂的cache和heap manager 构成的。
它主要解决三个基本问题:
1、不同大小SQL语句内存的分配,每次分配的内存大小是不一致的,从几个字节到上千个字节;
2、因为shared pool的目的是为了最大化共享信息,所以不是每次一个用户用完之后就可以释放这段内存(在传统的heap manager方式会遇到这个问题)。内存中的信息可能对于其他session来说是有用的——Oracle并不能事先知道这些内容是否会被再次用到;
3、Shared pool中的内容不能被写入到硬盘区域中,这一点和传统cache是不一样的。只有“可重用”的信息可以被覆盖,因为他们可以在下次需要时重建。
在发生hard parsing 时,进程从共享池中分配新SQL语句需要的存储空间时,必须先获得shared pool锁存器,shared pool锁存器全实例只有一个,在分配需要的内存chunk的过程中,一直持有shared pool锁存器。因此,多个进程同时使用共享池内存时,在获取shared pool锁存器过程中就会发生争用,就会产生等待latch:sharedpool 等待事件。
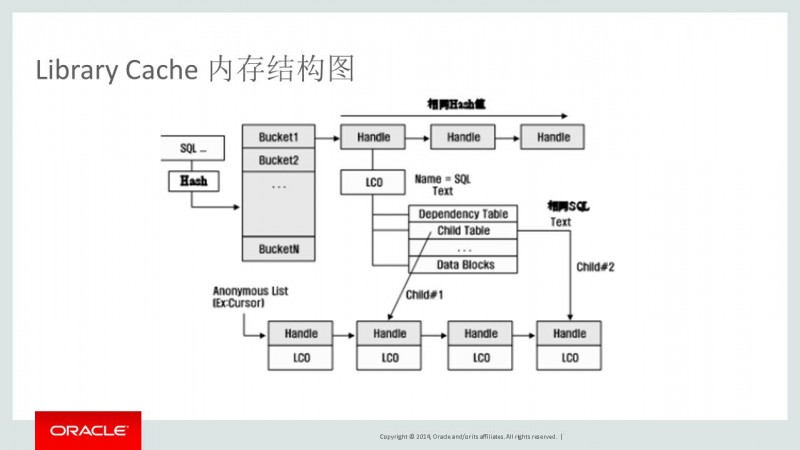
Library Cache 是共享池中最关键的部分,它是管理与SQL语句执行相关的所有信息。Library Cache 内存管理结构是hash table ->bucket->chain->handle->object.shared pool的管理是一件非常复杂的事情,在开始这部分内容前,我先介绍一下和这部分内容相关的概念。
Hard Parse(硬解析)
如果一个新的SQL被发起,但是又不在shared pool里面的话,它将被完整的解析一次。例如:Oracle必须在shared pool中分配内存,检查句法和语义等等……这被称为hard parse,它在CPU使用和latch获取上的都是非常消耗资源的。
Soft Parse(软解析)
如果一个session发起一个已经在shared pool中的SQL语句并且它可以使用一个当前存在的版本,那么这个过程被称为一个'soft parse'。对于应用来说,它只需请求解析这个语句。
Sharable SQL
如果是两个不同的session发起了完全相同的SQL语句,这也不意味着这个语句是可以共享的。比如说:用户SCOTT下有一个表EMP,发起了下面的语句:
SELECT ENAME from EMP;
用户FRED 有一个自己的表也叫EMP并且发起相同的语句:
SELECT ENAME from EMP;
尽管语句完全一样但是由于需要访问的EMP表是不同的对象,所以需要对这条语句产生不同的版本。有很多条件来判断两个完全一致的SQL文本是不是真的是完全相同(以至于他们可以被共享),包括:
1.语句中引用的所有的对象名必须都被解析成实际相同的对象;
2.发起语句的session中的optimizer相关的参数应该一致;
3.绑定变量的类型和长度应该是"相似的"(这里不做详细讨论,但是类型和长度的不同确实会导致语句被分为不同的版本);
4.发起语句的NLS (National Language Support)设置必须相同。
语句的版本
正如之前在'Sharable SQL'中描述的,如果两个语句字面上完全相同但是又不能被共享,则会对相同的语句产生不同的'version',即版本。如果Oracle要匹配一个包含多个版本的语句,它将不得不检查每一个版本来看它们是不是和当前被解析的语句完全相同。
所以最好用以下方法来避免高版本数(high version count):
1.客户端使用的绑定变量最大长度需标准化;
2.如果有大量的schema会包含相同名字的对象,那么避免使用一个相同的SQL语句。比如: SELECT xx FROM T; 并且每个用户都有一个自己的 T 的情况;
3.在Oracle 8.1可以将 _SQLEXEC_PROGRESSION_COST 设置成'0'。
下面列出了一些影响shared pool性能和它相关的latch的关键问题以及解决shared pool性能影响的方法。
1.减少Literal SQL,使用绑定变量
一个Literal SQL语句是指在predicate中使用具体值,而不是使用绑定变量,即不同的执行语句使用的具体值可能是不一样的。
例1:应用程序使用了:
SELECT * FROM emp WHERE ename='CLARK';
而不是:
SELECT * FROM emp WHERE ename=:bind1;
例2:如果两个SQL语句的含义相同但是没有使用相同的字符,那么Oracle认为它们是不同的语句。比如SCOTT在一个Session中提交的这两个语句:
SELECT ENAME from EMP;
SELECT ename from emp;
尽管它们实际上是相同的,但是因为大写字母‘E’和小写字母'e'的区别,他们不会被认为是完全相同的语句。
那么是不是任何情况,任何系统都要使用绑定变量哪?答案是否定的。原因是在有完整的统计信息并且SQL语句在predicate(限定条件)中使用具体值时,基于成本的优化器 (CBO)能工作的最好。比较下面的语句:
SELECT * FROM orders WHERE total_cost < 10000.0;
和
SELECT * FROM orders WHERE total_cost < :bindA;
对于第一个语句,CBO可以使用已经收集的histogram来判断是否使用全表扫描比使用TOTAL_COST列上索引扫描快(假设有索引的话)。第二个语句CBO并不知道绑定变量":bindA"对应行数的比例,因为该绑定变量没有一个具体的值以确定执行计划。例:":bindA" 可以是 0.0或者99999999999999999.9。
Orders表上两个不同的执行路径的响应时间可能会不同,所以当你需要CBO为你选出最好的执行计划的时候,选用使用literal语句会更好。在一个典型的Decision Support Systems(决策支持系统)中,重复执行'标准'语句的时候非常少,所以共享一个语句的几率很小,而且花在Parse上的CPU时间只占每个语句执行时间的非常小一部分,所以更重要的是给optimizer尽可能详细的信息,而不是缩短解析时间。
如果应用使用了literal (无共享) SQL,则会严重限制可扩展性和生产能力。在对CPU的需求、library cache 和 shared pool latch的获取和释放次数方面,新SQL语句的parse成本很高。
比如:仅仅parse一个简单的语句就可能需要获取和释放library cache latch 20或者30次。除非它是一个临时的或者不常用的SQL,并且需要让CBO得到尽可能多的信息来生成一个好的执行计划,否则最好让所有的SQL是共享的。
在OLTP类型的应用中,最好的方法是Parse一次并执行多次,然后保持这个cursor的打开状态,在需要的时候重复执行它。这样做的结果是每个语句只被Parse了一次(不管是soft parse还是hard parse)。显然,总会有些语句很少被执行,所以作为一个打开的cursor维护它们是一种浪费。
请注意一个session最多只能使用参数:open_cursors定义的cursor数,保持cursor打开会增加总体open cursors的数量。
三、总结:
1、OLTP系统尽量多使用绑定变量。
2、OLAP系统尽量多使用literal (无共享) SQL。
下面提供一个查找literal (无共享) SQL的方法。

这个查询查找前40个字符相同的,只被执行过很少次数,而又至少在shared pool里出现30次的语句。
在10g以上的版本可以用下面的SQL语句:

2.避免在业务高峰期执行DDL语句
有些命令会将sql的状态变成成INVALIDATE。这些命令直接修改cursor相关对象的上下文环境。它包括TRUNCATE, 表或索引上的ANALYZE或 DBMS_STATS.GATHER_XXX,关联对象的权限变更。相对应的cursor会留在SQLAREA中,但是下次被引用时会被完全reload并重新parse,所以会对数据库的整体性能造成影响。
我有一个真实的案例,在业务高峰期,执行了一个条grant 表授权的命令,导致数据性能急剧下降。
下面的查询可以帮我们找到Invalidation较多的sql:
SELECT SUBSTR(sql_text, 1, 40) "SQL",
invalidations
FROM v$sqlarea
ORDER BY invalidations DESC;
3.调整CURSOR_SHARING 参数
cursor_sharing参数在Oracle8.1.6引入的.这个参数需要小心使用。如果它被设为FORCE,那么Oracle会尽可能用绑定变量来替换原来SQL中的literals部分。因为FORCE会导致系统产生的绑定变量替换literal,从而影响优化器(CBO)可能会选择一个不同的执行计划,因为能够产生最好执行计划的literal值已经不存在了,被绑定变量替换掉了。
这个参数可以在系统级别或者session级别动态设置:ALTER SESSION SET cursor_sharing = FORCE;或者ALTER SYSTEM SET cursor_sharing = FORCE;
4.调整参数SESSION_CACHED_CURSORS 参数
当一个语句被parse的时候,Oracle会首先检查session的私有缓存中指向的语句,如果有可被共享的语句版本的话,它就可以被使用。这为经常被parse的语句提供了一个捷径,可以比soft或者hard parse使用更少的CPU和非常少的Latch get。
为了被缓冲在session缓存中,同样的语句必须在相同的cursor中被parse 3次,之后一个指向shared cursor的指针会被添加到你的session缓存中。如果session缓存cursor已达上限,则最近最少使用的那一个会被替换掉。
如果你还没有设置这个参数,建议先设置为50作为初始值。之后查看bstat/estat报告的统计信息章节的'session cursor cache hits'的值,从这个值可以判断cursor缓存是否有作用。如果有必要的话,可以增加或者减少cursor缓存的值。
session_cached_cursors参数 是一个可以在instance级别或者session级别设置的数值参数:ALTER SESSION SET session_cached_cursors = N;数值N 决定在一个session中可以被'cached'的cursor的个数。
5.调整_SQLEXEC_PROGRESSION_COST 参数 (8.1.5 以上)
这是一个Oracle 8.1.5引入的隐含参数。这里提到它是因为默认设置可能导致SQL共享方面的一些问题。设置成0会避免在shared pool 中产生语句高版本的问题。
提供一个查询高版本的SQL
SELECT address, hash_value,
version_count ,
users_opening ,
users_executing,
substr(sql_text,1,40) "SQL"
FROM v$sqlarea
WHERE version_count > 10
;
6.将cursor固定(pinning)在shared pool中
另外一种减少library cache latch使用的方法是将cursor固定在shared pool中,DBMS_SHARED_POOL.KEEP
这个存储过程 (RDBMS/ADMIN 目录下的DBMSPOOL.SQL脚本中有定义) 可以用来将对象KEEP到shared pool中, DBMS_SHARED_POOL.KEEP可以 'KEEP' packages, procedures, functions, triggers 和 sequences 。
通常情况下,建议将那些需要经常使用的package一直keep在shared pool中。KEEP操作在数据库启动后需要尽快实施,因为在shutdown之后Oracle不会自动重新keep这些对象。
7. 查找导致shared pool 内存‘aged’ out的内存分配的SQL语句
SELECT * FROM x$ksmlru WHERE ksmlrnum>0;
注意: 因为这个查询在返回不超过10行记录后就会消除X$KSMLRU的内容,所以请用SPOOL保存输出的内容。X$KSMLRU表显示从上一次查询该表开始,哪些内存分配操作导致了最多的内存块被清除出shared pool 。有些时候,这会有助于找到那些持续的请求分配空间的session或者语句。如果一个系统表现很好而且共享SQL 使用得也不错,但是偶尔会变慢,这个语句可以帮助找到原因。
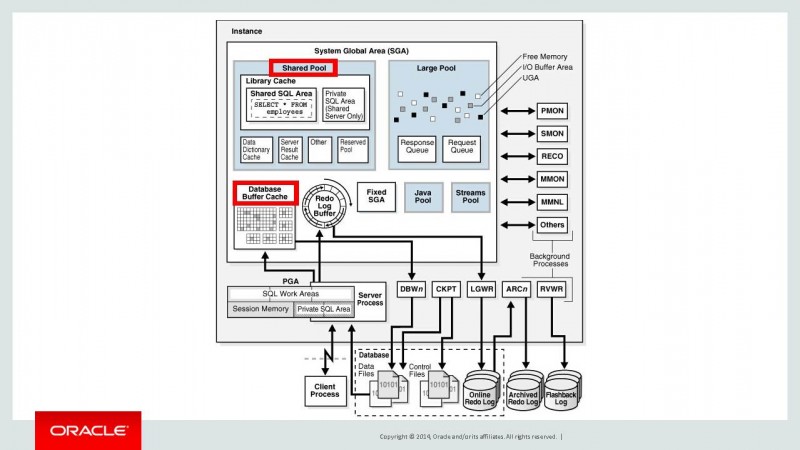
这是oracle体系结构图,我们今天主要介绍了标记红色的两步内存结构的等待。通过这两部分的介绍,主要告诉大家,如何从oracle数据库等待角度处理数据库性能问题。

这些事件大部分都是Idle事件,所以我们在分析性能时经常忽略不考虑,但是在某些情况下,这些事件对分析性能问题能提供决定性的线索。
当出现这些事件时,与下面2方面问题有关:
1.网络有关,网络丢包,网络速度缓慢。
2.SQL执行次数过高。
当出现SQL*Net message from/to client,SQL*Net more data from/to client事件时,有可能是应用程序和数据库之间的网络存在问题。如果SQL*Net message from/to client,SQL*Net more data from/to client事件出现过多,则数据库与数据库之间的网络存在问题。这时,我们应该对网络进行检查。
这是一个真实案例,前段时间咱们东北+DBA群的朋友发给我的一个AWR报告,系统现象,他反馈该系统的数据库运行缓慢,性能不好,提交非常慢。
1.首先我们看数据库系统非常空闲,不应该出现上述现象。数据库的Elapsed:119(mins)而DB Time:6.88(mins),说明系统比较空闲。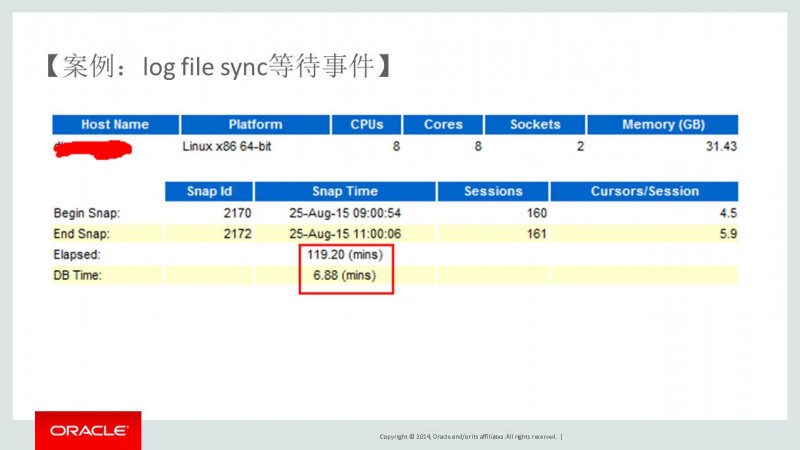
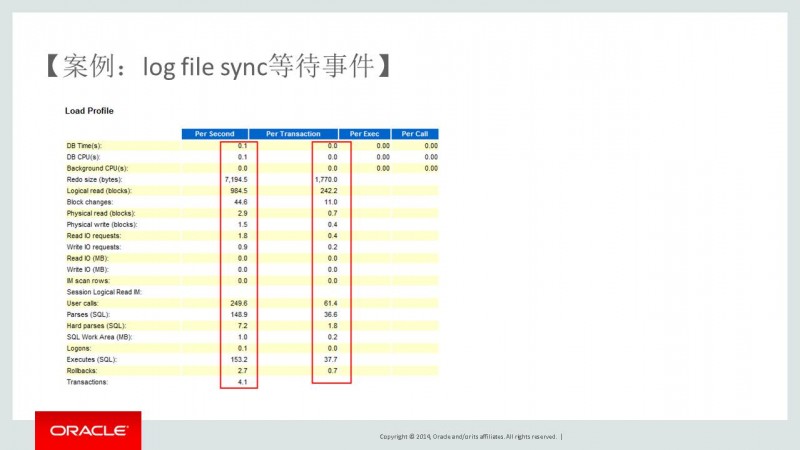
2.从 load profile中我们也能证实数据库比较空闲,几乎没有压力。我们接着往下看。
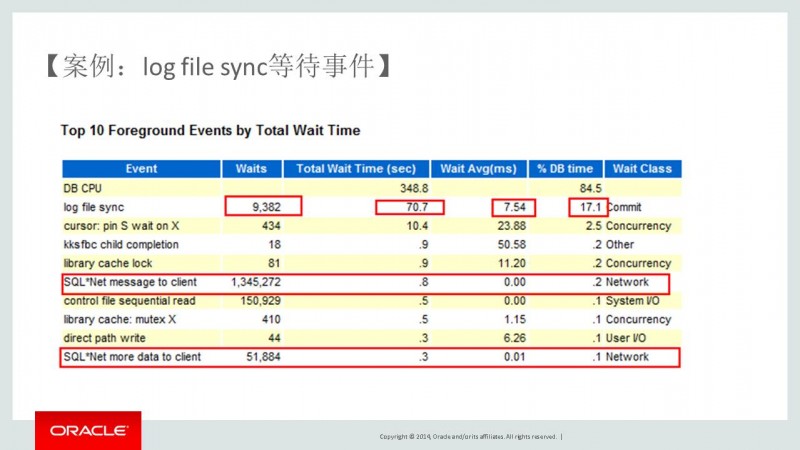
3. 我们从Top 10 Foreground Events by Total Wait Time看到很多和网络等待相关的事件。排在第一位是log file sync事件我们看到waits 9382,wait Avg(ms)7.54 %DB time Wait class: commit。commit提交事物,占用整个数据库的等待百分比为17% 平均等待为7.54ms 。那么在什么情况下,提交会等待那么长时间哪?
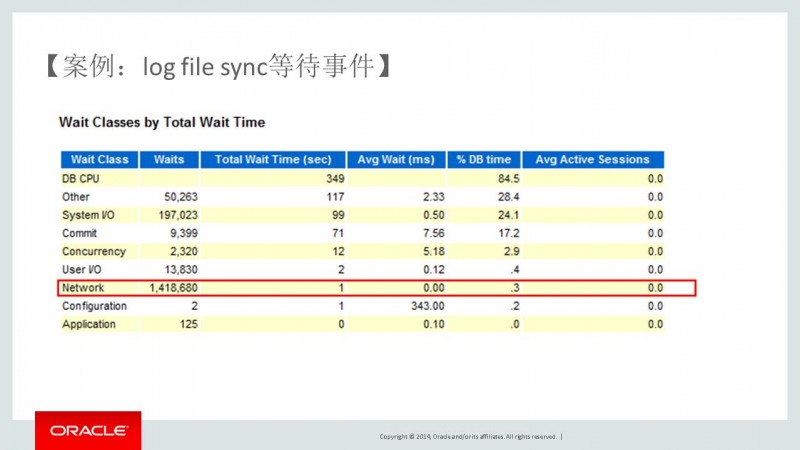
4. 从Wait Classes by Total Wait Time中我们看到依然是和网络相关的等待事件,等待时间(1418680)最高。
5. 从Foreground Wait Class中我们看到依然是和网络相关的等待事件,最高等待是commit。
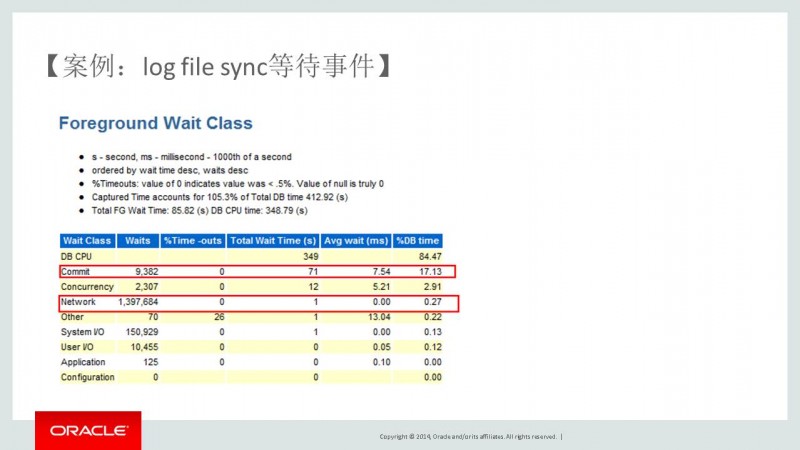
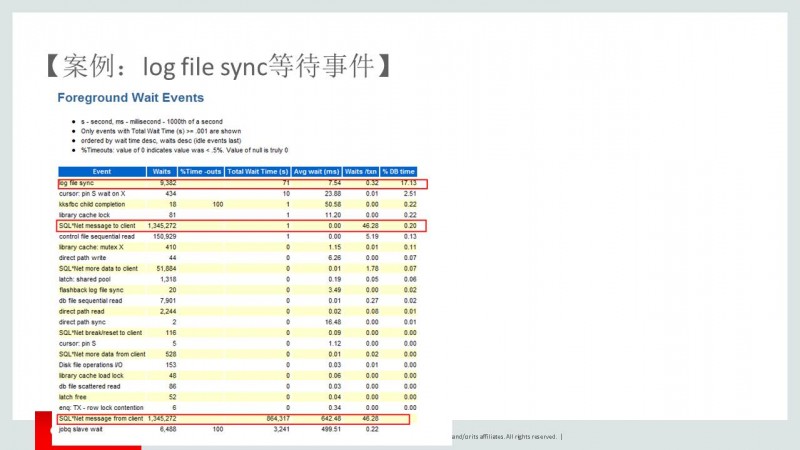
6. 从Foreground Wait Events中标记为红色,等待值都非常高。好了,我们已经通过很多地方证实了,影响该数据库的性能是和网络相关的。
7. 当我们读到Background Wait Events部分时,我们看到Redo Transport MISC,SYNC Remote Write,LNS wait on LGWR这些后台的等待事件时,问题已经豁然开朗了。我们如果对Oracle的DG比较熟悉的话,到这里我们就可以给出结论了。
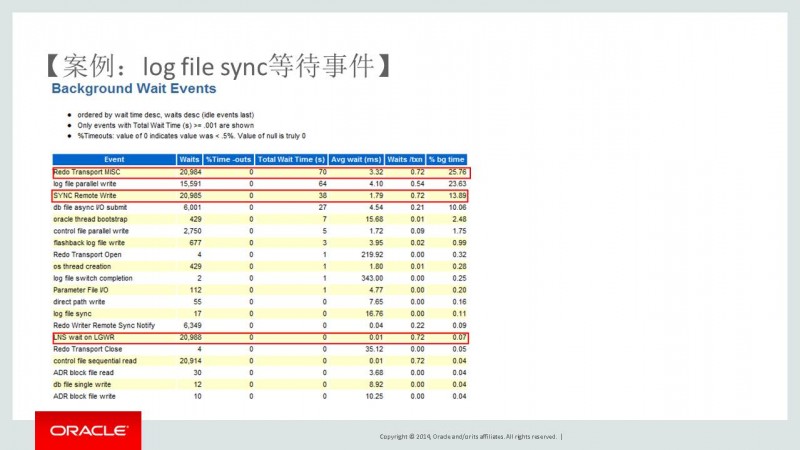
是因为该数据库配置的DG。数据库性能慢的原因是由于主库与备库之间的网络有问题。AWR报告中还有很多地方很多事件都指向和网络等待事件有关,在这里就不一一给大家贴图了。
数据库优化处处都有优化的余地。对DBA的要求也越来越高,不仅仅要只了解数据库技术,网络,存储,主机,软件架构多少都要了解,需要的知识面越来越广。最后。我想用一句话概括数据库优化,优化是数据库体系结构的延续,数据库的结构和运行的机制决定了数据库的优化模式,所以说数据库的体系是优化的基石。当你把数据库体系结构学明白了,优化是水到渠成。反过来,我们通过优化数据库,进一步的深入学习数据库的体系结构。
正文到此结束
- 本文标签: 操作系统 lib 文章 服务器 Oracle 医院 管理 解析 参数 client ACE update 医生 NSA HTML 快的 schema 博客 目录 js 标题 数据 App 软件 同步 http linux db cat UI CEO value 性能问题 主机 remote 压力 金融 空间 实例 总结 DDL cvs 进程 配置 时间 Select 锁 统计 tab 线程 map 需求 开发 src 测试 数据库 sql 代码 parse
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

