运维 2.0 时代:数据聚合和分组
运维 2.0 时代
运维 2.0 是指,从技术运维升级为服务运维,向公司提供可依赖的专业服务。运维 2.0 强调服务交付能力,而不是技术能力,需求可依赖、懂业务、服务化的专业运维。
为了了解运维 2.0 时代的监控方式,我们不妨从以前的监控手段说起。首先来了解一下 Zabbix ,通过 Zabbix 能够监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位和解决存在的各种问题。但时代在推进,如今 Zabbix 的功能真的就能满足广大开发者们么?

如果你是阿里云的用户,或者使用过 Zabbix,你将明显感受到一个痛点:没有办法对数据做聚合,只能挨个查看主机的性能指标,更不用说有管理的功能了。
如上图,Zabbix 只提供单台 Host 的 Disk 使用量。如果 3 台主机,同属于一个组 Mi-Kafka,就没法知道这个组总体 Disk 使用量了。
因此,就算线上系统发生了故障,要在短期内知道,到底是哪个模块的哪个部分出了什么样的问题,所需要的经验和时长都是巨大的。
而 OpenTSDB 和 StatsD 的出现改变了现状。
OpenTSDB 是什么呢,一个开源监控系统,可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的 Metrics 同时进行存储、索引以及服务,从而使得这些数据更容易让人理解。
集群监控
如今越来越多的企业开始使用混合云模式,来建设数据中心。私有云和公有云,以及集群系统,让监控工作变得异常复杂。所以,以下几个方面在运维监控中显得尤为重要:
- 性能指标的采集的轻量化;
- 性能指标能够集中在一个平台进行管理和可视化;
- 能够对性能指标进行灵活的组合和计算。
打个简单的比方,一家广告监控平台购买 AWS 的 50 台 EC2 来进行数据的采集,而数据分析则是本地的 10 台服务器来支持。

如果还在使用传统运维工具 Zabbix,这时候就会遇到一个问题,AWS 控制台可以看到这 50 台的监控指标。也就意味着,运维工程师需要使用 Zabbix 和 AWS 控制台来同时管理监控数据。
同时关注多集群中多个节点的运行情况,以及需要查看不同中间件的指标来发现问题,或者想要通过 Zabbix 集成短信报警渠道,这些让运维工作变得不堪重负。
而在非常早期的时候,淘宝团队就引入了 OpenTSDB 来辅助他们的运维监控。
随后的几年,云计算和 SaaS 的兴起,国外也出现了多种采用 StatsD 和 OpenTSDB 的开源工具搭建的 SaaS 服务:Boundary、CopperEgg、Datadog 等等。
他们都不约而同地采用了同一种产品逻辑,也是Cloud Insight 的产品逻辑————时间序列数据库的逻辑。
- 任何的性能指标,都作为时间序列数据被采集和处理;
- 任何的 Host 等归属于性能指标的属性,都作为指标的标签信息。
而在产品逻辑上,则表现为:

Cloud Insight
运维 2.0 时代有一款有趣的监控产品——Cloud Insight,它支持多种操作系统、云主机、数据库和中间件的监控,通过标签,对基础设施进行有效地管理,让您轻松应对复杂的基础设施架构。来帮助所有的 IT 公司,减少在系统监控上的人力和时间成本投入,让运维工作变得更加高效、简单。
视角决定高度,在此基础之上,Cloud Insight 还能够对数据指标进行聚合、分组、过滤、管理、计算;并提供团队协作功能,共同管理数据和报警事件。所以,Cloud Insight 也是一个数据管理平台,帮助企业内部加强沟通和协作,填补部门间、人员间、技能间的沟通鸿沟。
Cloud Insight 通过 3 个步骤深入操作系统、数据库、中间件,以及未来通过 Developer API 对接进来的所有 Metric 进行处理:
- Cloud Insight Agent 采集并处理 Metric;
- 在平台服务仪表盘和自定义仪表盘中,提供 Metric 聚合、分组、统计运算、基本数学运算等操作;
- 针对操作的结果,提供曲线图、柱状图等多样化的展现形式。
Cloud Insight 的神奇功能
- 自定义仪表盘
- 数据聚合
遥想 2015 年 8 月 17 日,Cloud Insight 还在梳理功能原型,畅想Cloud Insight 存在的意义,而一转眼,我们已经实现了很有意思的功能:
- 自定义仪表盘
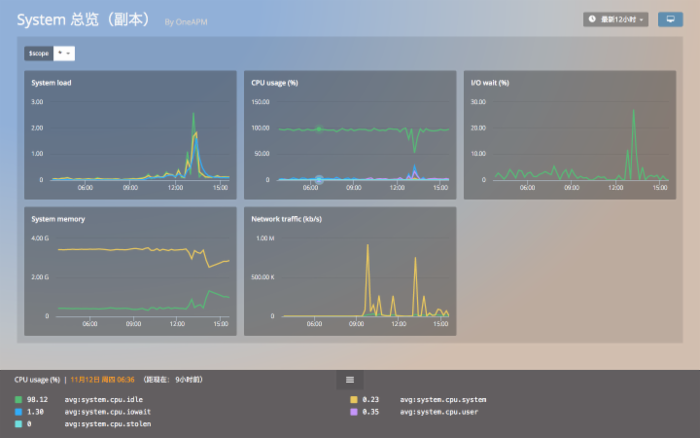
Cloud Insight 已经可以自定义仪表盘了,除了在数据展现上清晰直观,它还拥有一个炫酷的本事:随意拖拽。
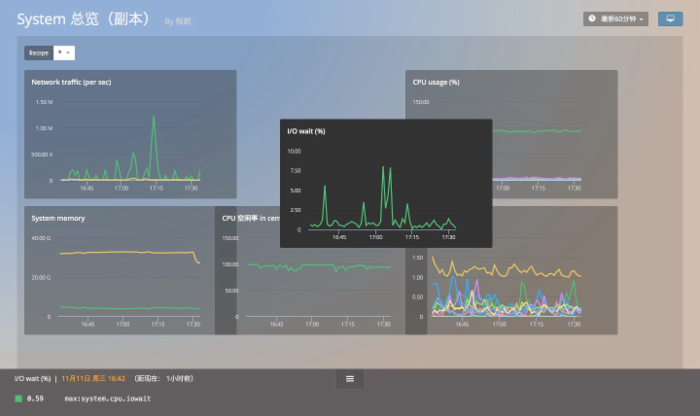
- 使用标签来实现数据聚合&分组
在 Beta v 0.2.1 中,我们实现了数据的聚合和分组。沿袭了 OpenTSDB 的查询方式:用一种类 SQL 的方式来查询指标。
具体操作可以访问Cloud Insight 文档中心 • Metric 查询。
Cloud Insight 还支持类似 SQL 的 group_by 查询语法。这个在查看 多个磁盘分区的容量 和 Docker 中不同 Container 的性能消耗 时都是非常有用的。
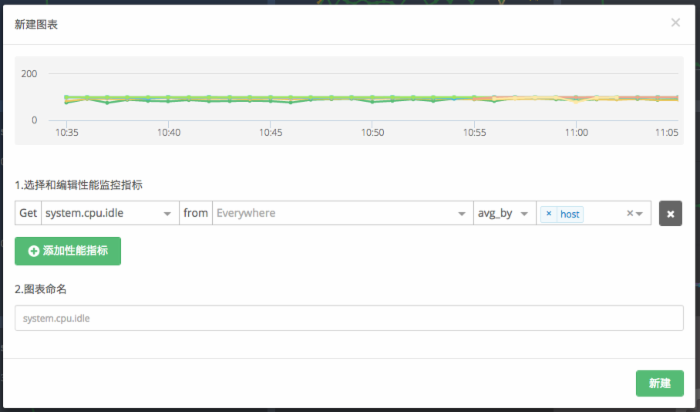
例子举例,如果我们想要看每个 host 的 CPU 空闲率:
avg: system.cpu.idle {} by {host} 此时,第一个 {FromTag} 缺省代表从所有 Metrics 中查询数据。如图所示,得到以下图表:
在实际的测试环境中,由于我们有 6 台测试主机,所以会得到如下的曲线。并且,当鼠标悬停至曲线时,下方的悬停窗口会分别显示 6 台主机的 system.cpu.idle。
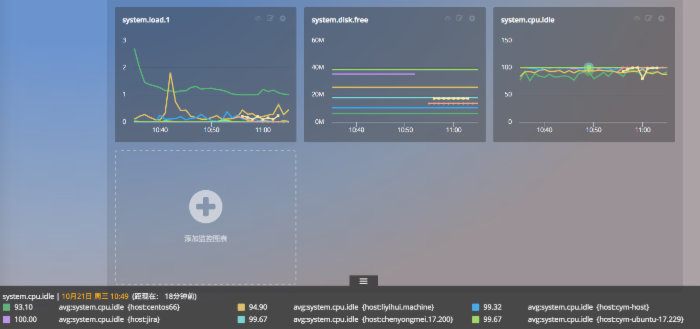
灵活查询,聚合&分组并存
除开单纯的聚合和分组,Cloud Insight 还支持聚合和分组的复合查询。如:
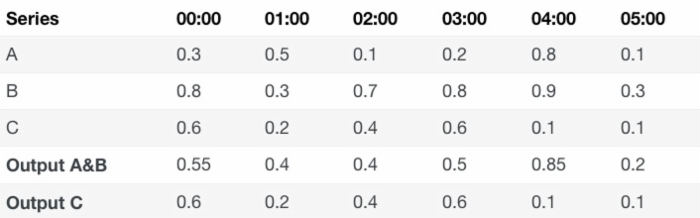
avg: system.cpu.idle {} by {owner} 
此时,虽然有 3 个 host,但是分组是以 owner 来进行的。所以,A 与 B 会聚合为一条曲线,而 C 和 A&B 的关系则是分组的关系。
当然,Cloud Insight 的功能在未来,还远远不止这些,高效运维的时代才刚刚开启。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

