数据分析
注:图片来源于网络

数据分析本身也是目标驱动,而目标会转化为问题,通过问题定义和分解会搞清楚究竟需要采集和分析哪些数据,得出你想要的分析结果。不论是VOC还是QFD等方法本身也体现的是客户需求和目标驱动。
数据是离散的还是连续的?数据本身是否符合正态分布?对于正态分布式当前数据最常见的一种连续概率分布,其集中性和对称性的钟形曲线是其基本特征。正态分布让我们可以更加科学,系统的看待数据,了解数据的出现概率,抓住数据分析的重点。
数据有抽样产生概率,概率本身又离不开置信区间,样本量越大往往置信区间越窄,数据更加可信,但是往往花费在样本采集上的工作量和投入越大。
测量系统是一个相对重要的内容,在当前很多数据分析中我们往往并不太关注测量系统,即我们再通过各种渠道采集或互联网搜索拿到数据后就进行数据分析,但是采集的数据本身是否可靠?数据本身的测量误差和过程误差是否在可以接受的范围?
测量系统要解决的问题就是通过采集和测量的数据最终是可靠的,是可以用于数据统计和分析的。
对于单列的数据刚才谈到过可以看其数据分布情况,比如是否符合正态分布。如果单列数据本身和时间相关,则可以进行时间序列分析。
对于表格类型的数据是我们经常看到的数据呈现形势,即数据呈现行和列两个属性,如果存在多个列则实际最终的数据表格是一个拥有多维属性的二维数据表。分组和维度是表格数据分析的基础,即通过分组可以产生各种数量上的统计和聚合,通过多维度可以形成多个角度的数据透视表。大多数的数据统计分析基本都是以上两种方式的组合。
维度是数据最核心的一个内容,理解清楚维度,维度组合就容易形成各种方式的聚合和统计。
数据和数据之间还需要进行相关性分析,在大数据里面往往更加强调数据之间的相关性,那么对于不同的两组数据就首先要看是否具备相关性。即首先判断是否具备相关性,再通过回归或其它方式去拟合具体的函数关系。
一个Y可以和多个X(x1,x2,x3...xn)间存在相关性,那么这种场景下的难度首先是要找到可能潜在存在哪些x,先提出假设,然后再去检验是否和目标y存在相关性。在大数据里面虽然强调相关性,但是仍然不能忽视了因果关系的找寻,即相关性表现是结果,那么导致这种结果的内因究竟是什么?很多真正的优化和改进是在内因上,而不是简单的模仿结果。
数据分析这个说法本身也不准确,实际可以看到数据统计和分析往往是结合的,而数据统计里面本身又有概率的内容,概率统计是能够做更加深入的数据分析的基础。即:
要做好数据分析一个是概率统计基础,一个是底层数据建模能力,这两个基础内容解决后,往往再往上层走的分析语句,R语言等反而更加容易。对于数据分析师更多是偏业务的岗位而非基础,你不需要去考虑Hadoop平台如何搭建和运行,但是你必须清楚如何建立数据模型和分析指标体系。
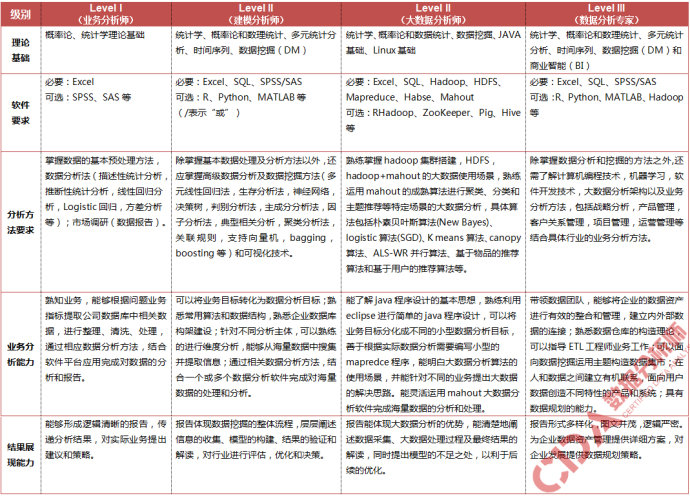
在数据分析师网有个图可以参考:http://cda.pinggu.org/view/39.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

