【Git 项目推荐】目前为止性能最强的 JSON 框架
Jfire-codejson框架
标签: 最高性能 Json
[TOC]
框架说明
Jfier-codejson是目前为止**性能最强的json框架**。序列化性能**超越fastjson50%**,反序列化性能**几倍于**fastjson. 在性能强劲的同时具备非常简单的API接口。对于常规操作,序列化和反序列化各自只有一个接口调用,非常简单易用。同时框架还具备策略模式,针对同一对象可以有任意内容的输出格式
快速入门
假设存在以下几个类
public class Person { private String name; private int age; private boolean boy; } public class Home { privaet String name; private Person host; private float height; private float weidth; } public static void main(String args[]) { Home home = new Home(); home.setPerson(new Person()); //这样就完成了将home转换为json字符串的动作 String json = JsonTool.write(home); //这样就完成了将json字符串转换为json对象的动作 JsonObject jsonObject =(JsonObject)jsonTool.fromString(json); //这样就完成了将json字符串转换为java对象的动作 Home result = JsonTool.read(Home.class,json); WriteStrategy strategy = new WriteStrategy(); //指定一个输出策略,将name这个属性名在输出的时候替换成hello strategy.addRenameField("Home.name", "hello"); json = strategy.write(home); }
代码说明
代码托管于osc:地址 编译包的下载链接: 链接 依赖基础包的下载链接: 链接
性能分析
Jfire-codejson性能如此之强原因在于采用了与众不同的算法。 序列化 传统的序列化框架,或者说相对比较优秀的序列化框架大部分都采用了分析对象内容,而后通过反射调用方法或者反射取出属性值的方式将对象进行序列化。这种思想产生的框架最大的瓶颈在反射导致的性能消耗。**Jfire-codejson独特的使用了为序列化对象动态编译一个输出对象**,输出对象中全部是调用序列化对象的get方法来得到属性值。并且在拼接json中的key名称时,由于动态编译代码,所以编译代码中是事先知道并且写入的,这样又减少了获取对象属性名称的这一步骤。**使得Jfire-codejson的序列化能力逼近理论上限**(为每个对象编写代码的这种理论方式) 反序列化 反序列化首先是解析json字符串。在这一步,框架设计了一种无回退的单次字符读取方式。大致原理是依次读取每一个字符,如果遇到一些特殊的表示字符,比如 { , } , : , [ , ] 等等。在遇到这些字符的时候生成jsonObject或者jsonArray来进行相应的读取处理。使用两个堆栈,一个堆栈存储jsonKey,一个堆栈存储当前待处理的json对象(jsonObject或者jsonArray)。这样子在处理的过程中就可以达到顺序处理的效果。**解析的速度非常快,可以达到数倍于fastjson的性能**。 将一个json对象反序列化成pojo,原理上和序列化大致相同。通过将对象的所有set方法得到。动态编译一个设置类,该类中对于每一个set方法,都生成类似 if(jsonObject.containsKey("name")){entity.setName(jsonObject.getString("name"))} 这样的代码。由于是动态编译,所以事先知道需要进行哪些判断,而且判断完之后是原生代码的set操作,节省了判断时间和调用反射时间,故而反序列化的性能也是非常的优秀。**几倍于fastjson**。
序列化
如果要将一个对象序列化,最快的方式无疑是针对这个对象,写出一段特定的代码。代码当中通过调用对象的get方法来得到对象属性值。参考下面的代码
public class User { private String name; private int age; } //针对上面的类,最快的序列化json的代码应该是 public static void main(String args[]) { User user = new User(); StringBuilder str = new StringBuilder(); str.append("{"); str.append("/"name/":");//无需放入变量值,采用固定值节省了变量获取的时间还有利于jvm优化 str.append("/"").append(user.getName()).append("/","); str.append("/"age/":").append(user.getAge()); str.append("}"); }
在上面的示例代码中,没有反射,没有任何分析。针对对象给出特定的序列化代码。如果说我们的框架也能够模拟这样的方式,就可以达到最大化的序列速度。并且可以逼近理论的上限。为了达到这样的效果,采用了动态代码编译的方式来完成。
- 首先获得目标类的Class对象。获取该对象的所有get方法(或者是is方法,方法需符合javabean规范)
- 编译动态代码,首先生成一个StringBuilder用来存储json字符串。动态代码中还需要有要序列化的对象实例
- 针对第1步获得的每一个方法,根据javabean规范提取出属性名称。生成类似的
builder.append("name").append(":/"").append(entity.getName()).append("/",")代码。 - 所有get方法完成后就可以编译这份代码形成一个特定的序列化类。创建一个Map结构,用来存储对象和序列化类之间的映射关系。如果在第3步的处理过程中发现非基本类型的属性,则编译类似
builder.append("anotherObject").append(":");WriteContext.write(entity.getAnotherObject(),builder)的代码,形成嵌套的分析过程。当嵌套结束时这个对象也就彻底分析完毕.
通过上面这样的步骤,框架针对每一个对象,都能生成一个针对该该对象的特定输出类,这个输出类为原生代码编译,获取对象内容以及属性名称都是原生代码调用,性能非常高。 当然,动态代码生成中有很多需要判断的地方。比如如果是对象的情况下,要在字符串中添加 {} 。比如字符串需要使用 " 包围内容,而数字和布尔值不需要,比如遇到数组需要 [] 等等。但是大体的思想就是通过动态代码编译,在运行的时候针对一个特定的对象,生成针对该对象的输出类。并且对这个类进行编译生成Class文件。动态编译这个部分采用Javassist来完成。 生成的代码例子如下 序列化一个如下对象
public class com.jfire.codejson.Home { private String name = "home"; private int length = 113; private int wdith = 89; //省略get set方法 }
框架针对这个对象生成的动态类的内容是
public class JsonWriter_Home_231313131 { StringCache cache = (StringCache)$2; com.jfire.codejson.Home entity =(com.jfire.codejson.Home )$1; cache.append('{'); cache.append("/"length/":").append(entity.getLength()).append(','); String name = entity.getName(); if(name!=null) { cache.append("/"name/":/"").append(name).append("/","); } cache.append("/"wdith/":").append(entity.getWdith()).append(','); if(cache.isCommaLast()) { cache.deleteLast(); } cache.append('}'); }
序列化的算法思路流程如下 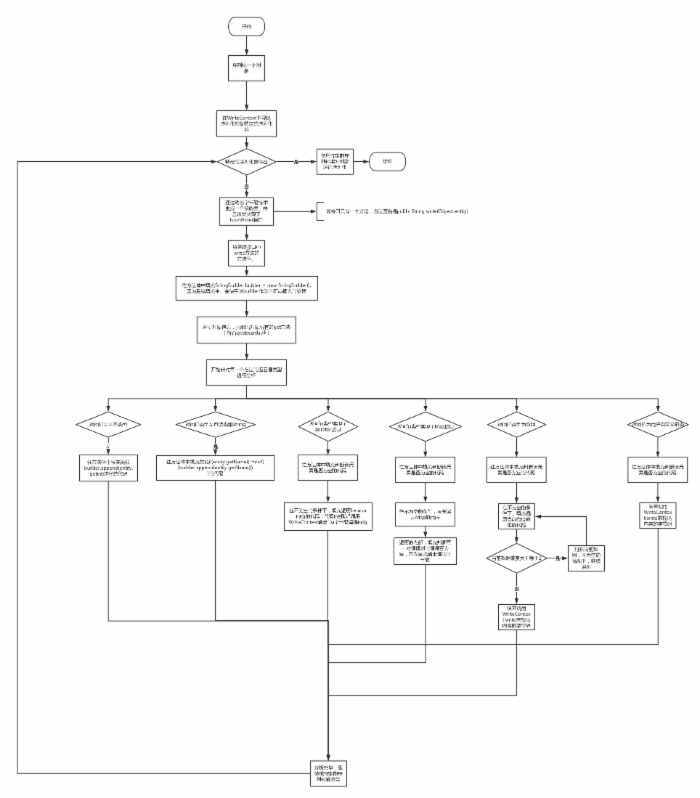
反序列化
解析json字符串
因为json是一个kv结构。所以算法设计了两个堆栈结构。堆栈结构,在数据顺序上和算法要求的*一遍读取无回溯*是相吻合的。
- 键堆栈用来压入待处理的jsonkey
- 值堆栈用来压入每次发现的jsonObject或者jsonArray
解析json字符串的算法的思路大致可以描述为
- 创建两个堆栈结构用来存储数据
- 逐个字符的读取数据。如果遇到标志字符,比如
{,},:,[,],,,'"'等进行特别处理,记录发现位置,根据发现位置决定是否创建新的jsonObject或者jsonArray进行嵌套等。 - 重复过程2,直到字符读取完毕。如果全部读取完毕则返回值堆栈最上方的json(此时键堆栈应该为空,值堆栈只有一个数据)。如果json字符串不符合规范,则在解析过程中会被发现。程序抛出异常。
下面是解析过程的详细流程图 
反序列化
将一个json对象反序列化成Pojo,和序列化的流程相似。算法的大致思路如下
- 获取pojo的所有set方法。
- 编译动态代码。在动态代码的开始处,创建类似代码
EntityClass entity = new EntityClass();。使用pojo的类创建一个Pojo对象供后面使用 - 针对第一步获得的每一个set方法。根据javabean规范取得该set方法对应的属性名。构建类似这样
if(json.containsKey("name")){entity.setName(json.getString("name"))}的代码。其中name就是根据set方法计算出来的属性名。 - 所有set方法完成后就将这份代码编译生成一个针对特定对象的转换类,将这个读取类放入一个Map中管理,key为需要转换的类,value为生成的转换类。如果在第3步分析的过程中,发现了非基本属性,也就是嵌套对象。则嵌套执行1-4的步骤。并且针对这个属性,生成类似
if(json.containsKey("anotherObject")){entity.setAnotherObject(readContext.read(AnotherObject.class,json.getString("name")))}的代码。其中readContext就是一个保存pojo和转换类映射关系的Map容器。
经过以上的四个步骤,就完成了一个输出类的代码生成。使用这个输出类对特定的对象进行反序列化就可以达到非常高的性能。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

