一个60亿数据表改分区表+数据清理的改进思路
今天有个同学问我一个问题,也是一个实际的案例,我简单分析了一下,发现还是有很多可以考究的地方。仅做参考。
问题是,系统里目前有一个大表,因为历史数据的沉淀,目前有60多亿的数据,不是分区表,现在得到反馈说insert的操作比较满,想优化一下,同时把部分历史数据需要做一些清理。
对于这类操作,要求停机时间尽可能短,有什么好的办法。
对于这个问题看起来问题似乎是很明显的。
目前反应出的问题是Insert慢,可能有下面的几个原因。
1.表索引巨大,索引维护管理要复杂一些
2.表中可能含有一些冗余索引,或者多个索引。
3.insert操作可能也是误导,很有可能是查询更慢。
对于这类问题还是需要琢磨一下。简单做了确认,查询其实也很慢。
那么问题的原因可以再补充几个。
4.sql语句导致的性能问题
5.高水位线导致的问题
整个问题的改进思路可以大体描述为下面的情况。
需要把表改为分区表,建立分区索引
表中的数据需要做清理,只保留部分的数据,比如按照50%的比例。



如果是这样的情况,很自然的就想到了在线重定义,不过在线重定义在使用的时候,分区肯定是可以的,能够保证在线,但是性能上还是会差一些,毕竟需要内部去同步一遍数据。
数据清理的部分还是不好做,还得进一步清理。
如果使用exp/imp或者expdp/impdp的时候,除了工具本身的效率外,还有一个部分就是对于导入数据都基本是串行,如果一个分区表有100个分区,那么100个分区都会同时持有锁。
如果使用sqlldr来做,都可以实现,不过主要的问题不在分区上了,而是在于历史数据清理,都需要先同步导入再进一步清理
同时分区表还需要创建所有匹配的分区,然后导入数据之后再清理分区。
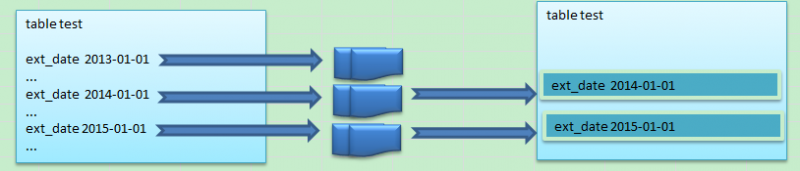
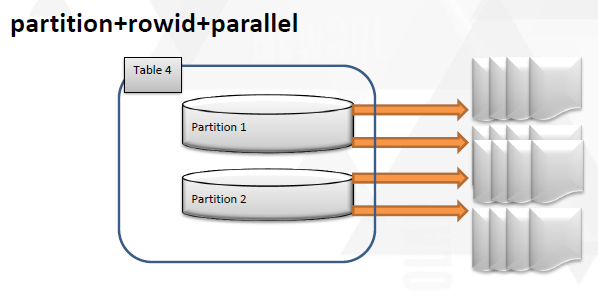
画图来说明就是下面的形式。
首先抽取的时候是按照时间分区来抽取生成相应的dump文件,比如分区是2013-01-01的可以根据ext_date来抽取,得到相应的外部表dump
其它的时间段都是类似的处理,那么导出这些“分区”数据之后,在导入的时候就可以并行+并发来做了。可以对每个分区单独开启一个导入的处理进程,对每一个处理进程可以开启并行来处理。
而且一个重要的地方就是,如果2013年的分区不需要,那么我就压根不导入。
当然这个过程还是需要窗口时间,个人觉得还是尽快完成,在这个代价上应该比在线要好一些,毕竟在线重定义在大数据量的时候在线处理时间还是有些长了。
如果采用了外部表的备份方式,历史数据还可以保留这种可读的备份。
最后还有一些细节需要说明的是,分区表test算是一个重新建立的分区表,还是需要考虑在清除原来的test表时保留原表的ddl,权限,相关的同义词,对应的pl/sql(包,存储过程,函数等等)保证在重建的这个表还是能够保留原来的“味道”
其实这个部分,使用外部表也是一个思路,其实对于拆表,分表自己也有一些心得,在以前的数据迁移中也尝试了一部分,在dtcc上也做了分享,简单说明一下。
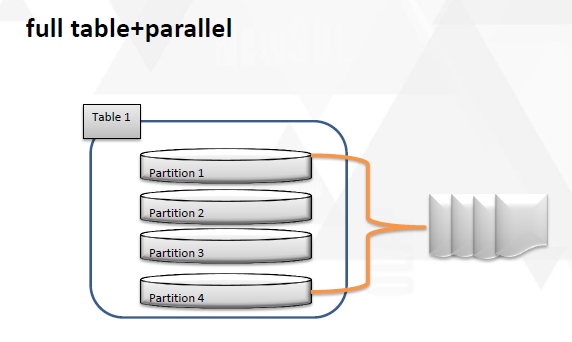
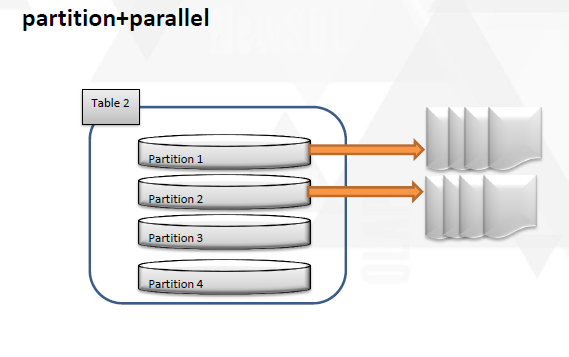
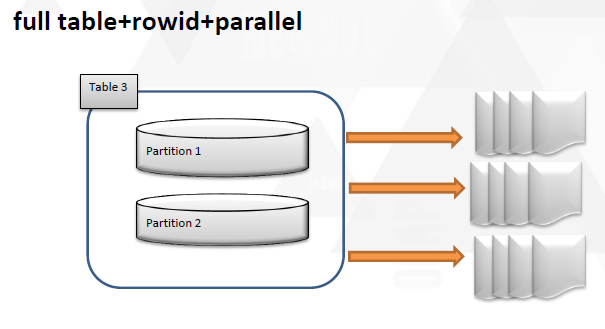
这几种方式都可以在一定程度上把表拆分成更小的粒度。能够尽可能全面的利用起来。
问题是,系统里目前有一个大表,因为历史数据的沉淀,目前有60多亿的数据,不是分区表,现在得到反馈说insert的操作比较满,想优化一下,同时把部分历史数据需要做一些清理。
对于这类操作,要求停机时间尽可能短,有什么好的办法。
对于这个问题看起来问题似乎是很明显的。
目前反应出的问题是Insert慢,可能有下面的几个原因。
1.表索引巨大,索引维护管理要复杂一些
2.表中可能含有一些冗余索引,或者多个索引。
3.insert操作可能也是误导,很有可能是查询更慢。
对于这类问题还是需要琢磨一下。简单做了确认,查询其实也很慢。
那么问题的原因可以再补充几个。
4.sql语句导致的性能问题
5.高水位线导致的问题
整个问题的改进思路可以大体描述为下面的情况。
需要把表改为分区表,建立分区索引
表中的数据需要做清理,只保留部分的数据,比如按照50%的比例。
如果是这样的情况,很自然的就想到了在线重定义,不过在线重定义在使用的时候,分区肯定是可以的,能够保证在线,但是性能上还是会差一些,毕竟需要内部去同步一遍数据。
数据清理的部分还是不好做,还得进一步清理。
如果使用exp/imp或者expdp/impdp的时候,除了工具本身的效率外,还有一个部分就是对于导入数据都基本是串行,如果一个分区表有100个分区,那么100个分区都会同时持有锁。
如果使用sqlldr来做,都可以实现,不过主要的问题不在分区上了,而是在于历史数据清理,都需要先同步导入再进一步清理
同时分区表还需要创建所有匹配的分区,然后导入数据之后再清理分区。
画图来说明就是下面的形式。
首先抽取的时候是按照时间分区来抽取生成相应的dump文件,比如分区是2013-01-01的可以根据ext_date来抽取,得到相应的外部表dump
其它的时间段都是类似的处理,那么导出这些“分区”数据之后,在导入的时候就可以并行+并发来做了。可以对每个分区单独开启一个导入的处理进程,对每一个处理进程可以开启并行来处理。
而且一个重要的地方就是,如果2013年的分区不需要,那么我就压根不导入。
当然这个过程还是需要窗口时间,个人觉得还是尽快完成,在这个代价上应该比在线要好一些,毕竟在线重定义在大数据量的时候在线处理时间还是有些长了。
如果采用了外部表的备份方式,历史数据还可以保留这种可读的备份。
最后还有一些细节需要说明的是,分区表test算是一个重新建立的分区表,还是需要考虑在清除原来的test表时保留原表的ddl,权限,相关的同义词,对应的pl/sql(包,存储过程,函数等等)保证在重建的这个表还是能够保留原来的“味道”
其实这个部分,使用外部表也是一个思路,其实对于拆表,分表自己也有一些心得,在以前的数据迁移中也尝试了一部分,在dtcc上也做了分享,简单说明一下。
这几种方式都可以在一定程度上把表拆分成更小的粒度。能够尽可能全面的利用起来。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

