干货:漫谈游戏中的人工智能

文/fingerpass
写在前面
今天我们来谈一下游戏中的人工智能。当然,内容可能不仅仅限于游戏人工智能,还会扩展一些其他的话题。
游戏中的人工智能,其实还是算是游戏开发中有点挑战性的模块,说简单点呢,是状态机,说复杂点呢,是可以帮你打开新世界大门的一把钥匙。有时候看到知乎上一些可能还是前公司同事的同学的一些话,感觉还是挺哭笑不得的,比如这篇: http://zhi.hu/qu1h ,吹捧机器学习这种玄学,对游戏开发嗤之以鼻。我只能说,技术不到家、Vision不够,这些想通过换工作可培养不来。
这篇文章其实我挺早就想写了,在我刚进工作室不久,看了内部的AI workflow有感而发,evernote里面这篇笔记的创建时间还是今年1月份,现在都8个月过去了,唉。
废话不说了,还是聊聊游戏中的人工智能吧。
从一个简单的情景开始
怪物,是游戏中的一个基本概念。游戏中的单位分类,不外乎玩家、NPC、怪物这几种。其中,AI一定是与三类实体都会产生交集的游戏模块之一。
以我们熟悉的任意一款游戏中的人形怪物为例,假设有一种怪物的AI需求是这样的:
-
大部分情况下,漫无目的巡逻。
-
玩家进入视野,锁定玩家为目标开始攻击。
-
Hp低到一定程度,怪会想法设法逃跑,并说几句话。
我们以这个为模型,进行这篇文章之后的所有讨论。为了简化问题,以省去一些不必要的讨论,将文章的核心定位到人工智能上,这里需要注意几点的是:
-
不再考虑entity之间的消息传递机制,例如判断玩家进入视野,不再通过事件机制触发,而是通过该人形怪的轮询触发。
-
不再考虑entity的行为控制机制,简化这个entity的控制模型。不论是底层是基于SteeringBehaviour或者是瞬移,不论是异步驱的还是主循环轮询,都不在本文模型的讨论之列。
首先可以很容易抽象出来IUnit:
public interface IUnit { void ChangeState(UnitStateEnum state); void Patrol(); IUnit GetNearestTarget(); void LockTarget(IUnit unit); float GetFleeBloodRate(); bool CanMove(); bool HpRateLessThan(float rate); void Flee(); void Speak(); } 然后,我们可以通过一个简单的有限状态机(FSM)来控制这个单位的行为。不同状态下,单位都具有不同的行为准则,以形成智能体。
具体来说,我们可以定义这样几种状态:
-
巡逻状态: 会执行巡逻,同时检查是否有敌对单位接近,接近的话进入战斗状态。
-
战斗状态: 会执行战斗,同时检查自己的血量是否达到逃跑线以下,达成检查了就会逃跑。
-
逃跑状态: 会逃跑,同时说一次话。
最原始的状态机的代码:
public interface IState where TState : IConvertible { TState Enum { get; } TUnit Self { get; } void OnEnter(); void Drive(); void OnExit(); } 以逃跑状态为例:
public class FleeState : UnitStateBase { public FleeState(IUnit self) : base(UnitStateEnum.Flee, self) { } public override void OnEnter() { Self.Flee(); } public override void Drive() { var unit = Self.GetNearestTarget(); if (unit != null) { return; } Self.ChangeState(UnitStateEnum.Patrol); } } 决策逻辑与上下文分离
上述是一个最简单、最常规的状态机实现。估计只有学生会这样写,业界肯定是没人这样写AI的,不然游戏怎么死的都不知道。
首先有一个非常明显的性能问题:状态机本质是描述状态迁移的,并不需要记录entity的context,如果entity的context记录在State上,那么状态机这个迁移逻辑就需要每个entity都来一份instance,这么一个简单的状态迁移就需要消耗大约X个字节,那么一个场景1w个怪,这些都属于白白消耗的内存。就目前的实现来看,具体的一个State实例内部hold住了Unit,所以State实例是没办法复用的。
针对这一点,我们做一下优化。对这个状态机,把Context完全剥离出来。
修改状态机接口定义:
public interface IState where TState : IConvertible { TState Enum { get; } void OnEnter(TUnit self); void Drive(TUnit self); void OnExit(TUnit self); } 还是拿之前实现好的逃跑状态作为例子:
public class FleeState : UnitStateBase { public FleeState() : base(UnitStateEnum.Flee) { } public override void OnEnter(IUnit self) { base.OnEnter(self); self.Flee(); } public override void Drive(IUnit self) { base.Drive(self); var unit = self.GetNearestTarget(); if (unit != null) { return; } self.ChangeState(UnitStateEnum.Patrol); } } 这样,就区分了动态与静态。静态的是状态之间的迁移逻辑,只要不做热更新,是不会变的结构。动态的是状态迁移过程中的上下文,根据不同的上下文来决定。
分层有限状态机
最原始的状态机方案除了性能存在问题,还有一个比较严重的问题。那就是这种状态机框架无法描述层级结构的状态。
假设需要对一开始的需求进行这样的扩展:怪在巡逻状态下有可能进入怠工状态,同时要求,怠工状态下也会进行进入战斗的检查。
这样的话,虽然在之前的框架下,单独做一个新的怠工状态也可以,但是仔细分析一下,我们会发现,其实本质上巡逻状态只是一个抽象的父状态,其存在的意义就是进行战斗检查;而具体的是在按路线巡逻还是怠工,其实都是巡逻状态的一个子状态。
状态之间就有了层级的概念,各自独立的状态机系统就无法满足需求,需要一种分层次的状态机,原先的状态机接口设计就需要彻底改掉了。
在重构状态框架之前,需要注意两点:
-
因为父状态需要关注子状态的运行结果,所以状态的Drive接口需要一个运行结果的返回值。
-
子状态,比如怠工,一定是有跨帧的需求在的,所以这个Result,我们定义为Continue、Sucess、Failure。
-
子状态一定是由父状态驱动的。
考虑这样一个组合状态情景:巡逻时,需要依次得先走到一个点,然后怠工一会儿,再走到下一个点,然后再怠工一会儿,循环往复。这样就需要父状态(巡逻状态)注记当前激活的子状态,并且根据子状态执行结果的不同来修改激活的子状态集合。这样不仅是Unit自身有上下文,连组合状态也有了自己的上下文。
为了简化讨论,我们还是从non-ContextFree层次状态机系统设计开始。
修改后的状态定义:
public interface IState where TState : IConvertible { // ... TResult Drive(); // ... } 组合状态的定义:
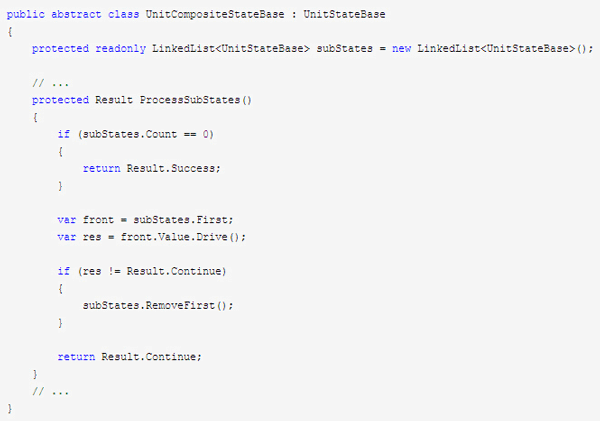
巡逻状态现在是一个组合状态:
public class PatrolState : UnitCompositeStateBase { // ... public override void OnEnter() { base.OnEnter(); AddSubState(new MoveToState(Self)); } public override Result Drive() { if (subStates.Count == 0) { return Result.Success; } var unit = Self.GetNearestTarget(); if (unit != null) { Self.LockTarget(unit); return Result.Success; } var front = subStates.First; var ret = front.Value.Drive(); if (ret != Result.Continue) { if (front.Value.Enum == CleverUnitStateEnum.MoveTo) { AddSubState(new IdleState(Self)); } else { AddSubState(new MoveToState(Self)); } } return Result.Continue; } } 看过《游戏人工智能编程精粹》的同学可能看到这里就会发现,这种层次状态机其实就是这本书里讲的目标驱动的状态机。组合状态就是组合目标,子状态就是子目标。父目标/状态的调度取决于子目标/状态的完成情况。这种状态框架与普通的trivial状态机模型的区别仅仅是增加了对层次状态的支持,状态的迁移还是需要靠显式的ChangeState来做。
这本书里面的状态框架,每个状态的执行status记录在了实例内部,不方便后续的优化,我们这里实现的时候首先把这个做成纯驱动式的。但是还不够。现在之前的ContextFree优化成果已经回退掉了,我们还需要补充回来。
分层的上下文
我们对之前重构出来的层次状态机框架再进行一次Context分离优化。
要优化的点有这样几个:
-
首先是继续之前的,unit不应该作为一个state自己的内部status。
-
组合状态的实例内部不应该包括自身执行的status。目前的组合状态,可以动态增删子状态,也就是根据status决定了结构的状态,理应分离静态与动态。巡逻状态组合了两个子状态——A和B,逻辑中是一个完成了就添加另一个,这样一想的话,其实巡逻状态应该重新描述——先进行A,再进行B,循环往复。
-
由于有了父状态的概念,其实状态接口的设计也可以再迭代,理论上只需要一个drive即可。因为状态内部的上下文要全部分离出来,所以也没必要对外提供OnEnter、OnExit,提供这两个接口的意义只是做一层内部信息的隐藏,但是现在内部的status没了,也就没必要隐藏了。
具体分析一下需要拆出的status:
-
一部分是entity本身的status,这里可以简单的认为是unit。
-
另一部分是state本身的status。
-
对于组合状态,这个status描述的是我当前执行到哪个substate。
-
对于原子状态,这个status描述的种类可能有所区别。
-
例如MoveTo/Flee,OnEnter的时候,修改了unit的status,然后Drive的时候去check。
-
例如Idle,OnEnter时改了自己的status,然后Drive的时候去check。
经过总结,我们可以发现,每个状态的status本质上都可以通过一个变量来描述。一个State作为一个最小粒度的单元,具有这样的Concept: 输入一个Context,输出一个Result。
Context暂时只需要包括这个Unit,和之前所说的status。同时,考虑这样一个问题:
-
父状态A,子状态B。
-
子状态B向上返回Continue的同时,status记录下来为b。
-
父状态ADrive子状态的结果为Continue,自身也需要向上抛出Continue,同时自己也有status为a。
这样,再还原现场时,就需要即给A一个a,还需要让A有能力从Context中拿到需要给B的b。因此上下文的结构理应是递归定义的,是一个层级结构。
Context如下定义:

修改State的接口定义为:

已经相当简洁了。
这样,我们对之前的巡逻状态也做下修改,达到一个ContextFree的效果。利用Context中的Continuation来确定当前结点应该从什么状态继续:



subStates是readonly的,在组合状态构造的一开始就确定了值。这样结构本身就是静态的,而上下文是动态的。不同的entity instance共用同一个树的instance。
语义结点的抽象
优化到这个版本,至少在性能上已经符合要求了,所有实例共享一个静态的状态迁移逻辑。面对之前提出的需求,也能够解决。至少算是一个经过对《游戏人工智能编程精粹》中提出的目标驱动状态机模型优化后的一个符合工业应用标准的AI框架。拿来做小游戏或者是一些AI很简单的游戏已经绰绰有余了。
不过我们在这篇博客的讨论中是不能仅停留在能解决需求的层面上。目前的方案至少还存在一个比较严重的问题,那就是逻辑复用性太差。组合状态需要coding的逻辑太多了,具体的状态内部逻辑需要人肉维护,更可怕的是需要程序员来人肉维护,再多几个组合状态简直不敢想象。程序员真的没这么多时间维护这些东西好么。所以我们应该尝试抽象一下组合状态是否有一些通用的设计pattern。
为了解决这个问题,我们再对这几个状态的分析一下,可以对结点类型进行一下归纳。
结点基本上是分为两个类型:组合结点、原子结点。
如果把这个状态迁移逻辑体看做一个树结构,那其中组合结点就是非叶子结点,原子结点就是叶子结点。
对于组合结点来说,其行为是可以归纳的。
-
巡逻结点,不考虑触发进入战斗的逻辑,可以归纳为一种具有这样的行为的组合结点:依次执行每个子结点(移动到某个点、休息一会儿),某个子结点返回Success则执行下一个,返回Failure则直接向上返回,返回Continue就把Continuation抛出去。命名具有这样语义的结点为Sequence。
-
设想攻击状态下,单位需要同时进行两种子结点的尝试,一个是释放技能,一个是说话。两个需要同时执行,并且结果独立。有一个返回Success则向上返回Success,全部Failure则返回Failure,否则返回Continue。命名具有如此语义的结点为Parallel。
-
在Parallel的语义基础上,如果要体现一个优先级/顺序性质,那么就需要一个具有依次执行子结点语义的组合结点,命名为Select。
Sequence与Select组合起来,就能完整的描述一”趟“巡逻,Select(ReactAttack, Sequence(MoveTo, Idle)),可以直接干掉之前写的Patrol组合状态,组合状态直接拿现成的实现好的语义结点复用即可。
组合结点的抽象问题解决了,现在我们来看叶子结点。
叶子结点也可以归纳一下pattern,能归纳出三种:
-
Flee、Idle、MoveTo三个状态,状态进入的时候调一下宿主的某个函数,申请开始一个持续性的动作。
-
四个原子状态都有的一个pattern,就是在Drive中轮询,直到某个条件达成了才返回。
-
Attack状态内部,每次都轮询都会向宿主请求一个数据,然后再判断这个“外部”数据是否满足一定条件。
pattern确实是有这么三种,但是叶子结点自身其实是两种,一种是控制单位做某种行为,一种是向单位查询一些信息,其实本质上是没区别的,只是描述问题的方式不一样。
既然我们的最终目标是消除掉四个具体状态的定义,转而通过一些通用的语义结点来描述,那我们就首先需要想办法提出一种方案来描述上述的三个pattern。
前两个pattern其实是同一个问题,区别就在于那些逻辑应该放在宿主提供的接口里面做实现,哪些逻辑应该在AI模块里做实现。调用宿主的某个函数,调用是一个瞬间的操作,直接改变了宿主的status,但是截止点的判断就有不同的实现方式了。
-
一种实现是宿主的API本身就是一个返回Result的函数,第一次调用的时候,宿主会改变自己的状态,比如设置单位开始移动,之后每帧都会驱动这个单位移动,而AI模块再去调用MoveTo就会拿到一个Continue,直到宿主这边内部驱动单位移动到目的地,即向上返回Success;发生无法让单位移动完成的情况,就返回Failure。
-
另一种实现是宿主提供一些基本的查询API,比如移动到某一点、是否到达某个点、获得下一个巡逻点,这样的话就相当于是把轮询判断写在了AI模块里。这样就需要有一个Check结点,来包裹这个查询到的值,向上返回一个IO类型的值。
-
而针对第三种pattern,可以抽象出这样一种需求情景,就是:
AI模块与游戏世界的数据互操作
假设宿主提供了接受参数的api,提供了查询接口,ai模块需要通过调用宿主的查询接口拿到数据,再把数据传给宿主来执行某种行为。
我们称这种语义为With,With用来求出一个结点的值,并合并在当前的env中传递给子树,子树中可以resolve到这个symbol。
有了With语义,我们就可以方便的在AI模块中对游戏世界的数据进行操作,请求一个数据 => 处理一下 => 返回一个数据,更具扩展性。
With语义的具体需求明确一下就是这样的:由两个子树来构造,一个是IOGet,一个是SubTree。With会首先求值IOGet,然后binding到一个symbol上,SubTree 可以直接引用这个symbol,来当做一个普通的值用。
然后考虑下实现方式。
C#中,子树要想引用这个symbol,有两个方法:
-
ioget与subtree共同hold住一个变量,ioget求得的值赋给这个变量,subtree构造的时候直接把值传进来。
-
ioget与subtree共同hold住一个env,双方约定统一的key,ioget求完就把这个key设置一下,subtree构造的时候直接从env里根据key取值。
考虑第一种方法,hold住的不应该是值本身,因为树本身是不同实例共享的,而这个值会直接影响到子树的结构。所以应该用一个class instance object对值包裹一下。
这样经过改进后的第一种方法理论上速度应该比env的方式快很多,也方便做一些优化,比如说如果子树没有continue就不需要把这个值存在env中,比如说由于树本身的驱动一定是单线程的,不同的实例可以共用一个包裹,执行子树的时候设置下包裹中的值,执行完子树再把包裹中的值还原。
加入了with语义,就需要重新审视一下IState的定义了。既然一个结点既有可能返回一个Result,又有可能返回一个值,那么就需要这样一种抽象:
有这样一种泛化的concept,他只需要提供一个drive接口,接口需要提供一个环境env,drive一下,就可以输出一个值。这个concept的instance,需要是pure的,也就是结果唯一取决于输入的环境。不同次输入,只要环境相同,输出一定相同。
因为描述的是一种与外部世界的通信,所以就命名为IO吧:
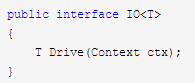
这样,我们之前的所有结点都应该有IO的concept。
之前提出了Parallel、Sequence、Select、Check这样几个语义结点。具体的实现细节就不再细说了,简单列一下代码结构:

With结点的实现,采用我们之前说的第一种方案:
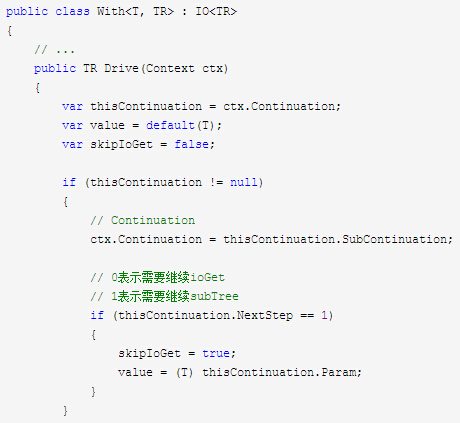


这样,我们的层次状态机就全部组件化了。我们可以用通用的语义结点来组合出任意的子状态,这些子状态是不具名的,对构建过程更友好。
具体的代码例子:

看起来似乎是变得复杂了,原来可能只需要一句new XXXState(),现在却需要自己用代码拼接出来一个行为逻辑。但是仔细想一下,改成这样的描述其实对整个工作流是有好处的。之前的形式完全是硬编码,而现在,似乎让我们看到了转数据驱动的可能性。
对行为结点做包装
当然这个示例还少解释了一部分,就是叶子结点,或者说是行为结点的定义。
我们之前对行为的定义都是在IUnit中,但是这里显然不像是之前定义的IUnit。
如果把每个行为都看做是树上的一个与Select、Sequence等结点无异的普通结点的话,就需要实现IO的接口。抽象出一个计算的概念,构造的时候可以构造出这个计算,然后通过Drive,来求得计算中的值。
包装后的一个行为的代码:

经过包装的行为结点的代码都是有规律可循的,所以我们可以比较容易的通过一些代码生成的机制来做。比如通过反射拿到IUnit定义的接口信息,然后直接在这基础之上做一下包装,做出来个行为结点的定义。
现在我们再回忆下讨论过的With,构造一个叶子结点的时候,参数不一定是literal value,也有可能是经过Box包裹过的。所以就需要对Boax和literal value抽象出来一个公共的概念,叶子结点/行为结点可以从这个概念中拿到值,而行为结点计算本身的构造也只需要依赖于这个概念。
我们把这个概念命名为Thunk。Thunk包裹一个值或者一个box,而就目前来看,这个Thunk,仅需要提供一个我们可以通过其拿到里
面的值的接口就够了。
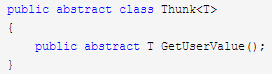
对于常量,我们可以构造一个包裹了常量的thunk;而对于box,其天然就属于Thunk的concept。
这样,我们就通过一个Thunk的概念,硬生生把树中的结点与值分割成了两个概念。这样做究竟正确不正确呢?
如果一个行为结点的参数可能有的类型本来就是一些primitive type,或者是外部世界(相对于AI世界)的类型,那肯定是没问题的。但如果需要支持这样一种特性:外部世界的函数,返回值是AI世界的某个概念,比如一个树结点;而我的AI世界,希望的是通过这个外部世界的函数,动态的拿到一个结点,再动态的加到我的树中,或者再动态的传给不通的外部世界的函数,应该怎么做?
对于一颗With子树(Negate表示对子树结果取反,Continue仍取Continue):
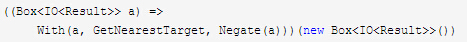
语义需要保证,这颗子树执行到任意时刻,都需要是ContextFree的。
假设IOGet返回的是一个普通的值,确实是没问题的。
但是因为Box包裹的可能是任意值,例如,假设IOGet返回的是一个IO,
-
instance a,执行完IOGet之后,结构变为Negate(A)。
-
instance b,再执行IOGet,拿到一个B,设置box里的值为B,并且拿出来A,这时候再run subtree,其实就是按Negate(B)来跑的。
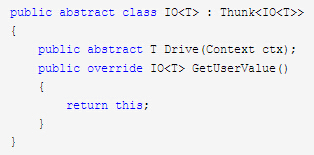
我们只有把IO本身,做到其就是Thunk这个Concept。这样所有的Message对象,都是一个Thunk。不仅如此,所以在这个树中出现的数据结构,理应都是一个Thunk,比如List。
再次改造IO:
BehaviourTree
对AI有了解的同学可能已经清楚了,目前我们实现的就是一个行为树的引擎,并且已经基本成型。到目前为止,我们接触过的行为树语义有:
Sequence、Select、Parallel、Check、Negate。
其中Sequence与Select是两个比较基本的语义,一个相当于逻辑And,一个相当于逻辑Or。在组合子设计中这两类组合子也比较常见。
不同的行为树方案,对语义结点的选择也不一样。
比如以前在行为树这块比较权威的一篇halo2的行为树方案的paper,里面提到的几个常用的组合结点有这样几种:
-
prioritized-list : 每次执行优先级最高的结点,高优先级的始终抢占低优先级的。
-
sequential : 按顺序执行每个子结点,执行完最后一个子结点后,父结点就finished。
-
sequential-looping : 同上,但是会loop。
-
probabilistic : 从子结点中随机选择一个执行。
-
one-off : 从子结点中随机选择或按优先级选择,选择一个排除一个,直到执行完为止。
而腾讯的behaviac对组合结点的选择除了传统的Select和Seqence,halo里面提到的随机选择,还自己扩展了SelectorProbability(虽然看起来像是一个select,但其实每次只会根据概率选择一个,更倾向于halo中的Probabilistic),SequenceStochastic(随机地决定执行顺序,然后表现起来确实像是一个Sequence)。
其他还有各种常用的修饰结点,比如前文实现的Check,还有一些比较常用的:
-
Wait :子树返回Success的时候向上Success,否则向上Continue。
-
Forever : 永远返回Continue。
-
If-Else、Switch-Cond : 对于有编程功底的我想就不需要再多做解释了。
-
forcedXX : 对子树结果强制取值。
还有一类属于特色结点,虽然通过其他各种方式也都能实现,但是在行为树这个层面实现的话肯定扩展性更强一些,毕竟可以分离一部分程序的职责。一个比较典型的应用情景是事件驱动,halo的paper中提到了Behaviour Impulse,但是我在在behaviac中并没有找到类似的概念。
halo的paper里面还提到了一些比较细节的hack技巧,比如同一颗行为树可以应用不同的Style,Parameter Creep等等,有兴趣的同学也可以自行研究。
至此,行为树的runtime话题需要告一段落了,毕竟是一项成熟了十几年的技术。虽然这是目前游戏AI的标配,但是,只有行为树的话,离一个完整的AI工作流还很远。到目前为止,行为树还都是程序写出来的,但是正确来说AI应该是由策划或者AI脚本配出来的。因此,这篇文章的话题还需要继续,我们接下来就讨论一下这个程序与策划之间的中间层。
之前的优化思路也好,从其他语言借鉴的设计pattern也好,行为树这种理念本身也好,本质上都是术。术很重要,但是无助于优化工作流。这时候,我们更需要一种略。那么,
略是什么
这里我们先扩展下游戏AI开发中的一种比较经典的工作流。策划输出AI配置,直接在游戏内调试效果。如果现有接口不满足需求,就向程序提开发需求,程序加上新接口之后,策划可以在AI配置里面应用新的接口。这个AI配置是个比较广义的概念,既可以像很多从立项之初并没有规划AI模块的游戏那样,逐渐地、自发地形成了一套基于配表做的决策树;也可以是像腾讯的behaviac那样的,用XML文件来描述。XML天生就是描述数据的,腾讯系的组件普遍特别钟爱,tdr这种配表转数据的工具是xml,tapp tcplus什么的配置文件全是XML,倒不是说XML,而是很多问题解决起来并不直观。
配表也好,XML也好,json也好,这种描述数据的形式本身并没有错。配表帮很多团队跨过了从硬编码到数据驱动的开发模式的转变,现在国内小到创业手游团队,大到天谕这种几百人的MMO,策划的工作量除了配关卡就是配表。
但是,配表无法自我进化( 点击查看 ),配表无法自己描述流程是什么样,而是流程在描述配表是什么样。
针对策划配置AI这个需求,我们希望抽象出来一个中间层,这样,基于这个中间层,开发相应的编辑器也好,直接利用这个中间层来配AI也好,都能够灵活地做到调试AI这个最终需求。如何解决?我们不妨设计一种DSL。
DSL
Domain-specific Language,领域特定语言,顾名思义,专门为特定领域设计的语言。设计一门DSL远容易于设计一门通用计算语言,我们不用考虑一些特别复杂的特性,不用加一些增加复杂度的模块,不需要care跟领域无关的一些流程。Less is more。
游戏AI需要怎样一种DSL
痛点:
-
对于游戏AI来说,需要一种语言可以描述特定类型entity的行为逻辑。
-
而对于程序员来说,只需要提供runtime即可。比如组合结点的类型、表现等等。而具体的行为决策逻辑,由其他层次的协作者来定义。
-
核心需求是做另一种/几种高级语言的目标代码生成,对于当前以及未来几年来说,对C#的支持一定是不能少的,对python/lua等服务端脚本的支持也可以考虑。
-
对语言本身的要求是足够简单易懂,declarative,这样既可以方便上层编辑器的开发,也可以在没编辑器的时候快速上手。
分析需求:
-
因为需要做目标代码生成,而且最主要的目标代码应该是C#这种强类型的,所以需要有简单的类型系统,以及编译期简单的类型检查。可以确保语言的源文件可以最终codegen成不会导致编译出错的C#代码。
-
决定行为树框架好坏的一个比较致命的因素就是对With语义的实现。根据我们之前对With语义的讨论,可以看到,这个With语义的描述其实是天然的可以转化为一个lambda的,所以这门DSL同样需要对lambda进行支持。
-
关于类型系统,需要支持一些内建的复杂类型,目前来看仅需要List,只有在seq、select等结点的构造时会用到。还是由于需要支持lambda的原因,我们需要支持Applicative Type,也就是形如A -> B应该是first class type,而一个lambda也应该是first class function。根据之前对runtime的实现讨论,我们的DSL还需要支持Generic Type,来支持IO
这样的类型,以及List<IO >这样的类型。对内建primitive类型的支持只要有String、Bool、Int、Float即可。需要支持简单的类型推导,实现hindley-milner的真子集即可,这样至少我们就不需要在声明lambda的时候写的太复杂。 -
需要支持模块化定义,也就是最基本的import语义。这样的话可以方便地模块化构建AI接口,也可以比较方便地定义一些预制件。
模块分为两类:
-
一类是抽象的声明,只有declare。比如Prelude,seq、select等一些结点的具体实现逻辑一定是在runtime中做的,所以没必要在DSL这个层面填充这类逻辑。具体的代码转换则由一些特设的模块来做。只需要类型检查通过,目标语言的CodeGenerator生成了对应的目标代码,具体的逻辑就在runtime中直接实现了。
-
一类是具体的定义,只有define。比如定义某个具体的AIXXX中的root结点,或者定义某个通用行为结点。具体的定义就需要对外部模块的define以及declare进行组合。import语义就需要支持从外部模块导入符号。
一种non-trivial的DSL实现方案
由于原则是简单为主,所以我在语言的设计上主要借鉴的是Scheme。S表达式的好处就是代码本身即数据,也可以是我们需要的AST。同时,由于需要引入简单类型系统,需要混入一些其他语言的描述风格。我在declare类型时的语言风格借鉴了haskell,import语句也借鉴了haskell。
具体来说,declare语句可能类似于这样:
(declare (HpRateLessThan :: (Float -> IO Result)) (GetFleeBloodRate :: Float) (IsNull :: (Object -> Bool)) (Idle :: IO Result)) (declare (check :: (Bool -> IO Result)) (loop :: (IO Result -> IO Result)) (par :: (List IO Result -> IO Result)))
因为是以Scheme为主要借鉴对象,所以内建的复杂类型实现上本质是一个ADT,当然,有针对list构造专用的语法糖,但是其parse出来拿到的AST中一个list终究还是一个ADT。
直接拿例子来说比较直观:
(import Prelude) (import BaseAI) (define Root (par [(seq [(check IsFleeing) ((/a (check (IsNull a))) GetNearestTarget)]) (seq [(check IsAttacking) ((/b (HpRateLessThan b)) GetFleeBloodRate)]) (seq [(check IsNormal) (loop (par [((/c (seq [(check (IsNull c)) (LockTarget c)])) GetNearestTarget) (seq [(seq [(check ReachCurrentPatrolPoint) MoveToNextPatrolPoiont]) Idle])]))])]))
可以看到,跟S-Expression没什么太大的区别,可能lambda的声明方式变了下。
然后是词法分析和语法分析,这里我选择的是Haskell的ParseC。一些更传统的选择可能是lex+yacc/flex+bison。但是这种两个工具一起混用学习成本就不用说了,也违背了simple is better的初衷。ParseC使用起来就跟PEG是一样的,PEG这种形式,是天然的结合了正则与top-down parser。haskell支持的algebraic data types,天然就是用来定义AST结构的,简单直观。haskell实现的hindly-miner类型系统,又是让你写代码基本编译通过就能直接run出正确结果,从一定程度上弥补了PEG天生不适合调试的缺陷。一个haskell的库就能解决lexical&grammar,实在方便。
先是一些AST结构的预定义:
module Common where import qualified Data.Map as Map type Identifier = String type ValEnv = Map.Map Identifier Val type TypeEnv = Map.Map Identifier Type type DecEnv = Map.Map Identifier (String,Dec) data Type = NormalType String | GenericType String Type | AppType [Type] data Dec = DefineDec Pat Exp | ImportDec String | DeclareDec Pat Type | DeclaresDec [Dec] data Exp = ConstExp Val | VarExp Identifier | LambdaExp Pat Exp | AppExp Exp Exp | ADTExp String [Exp] data Val = NilVal | BoolVal Bool | IntVal Integer | FloatVal Float | StringVal String data Pat = VarPat Identifier
我在这里省去了一些跟这篇文章讨论的DSL无关的语言特性,比如Pattern的定义我只保留了VarPat;Value的定义我去掉了ClosureVal,虽然语言本身仍然是支持first class function的。
algebraic data type的一个好处就是清晰易懂,定义起来不过区区二十行,但是我们一看就知道之后输出的AST会是什么样。
haskell的ParseC用起来其实跟PEG是没有本质区别的,组合子本身是自底向上描述的,而parser也是通过parse小元素的parser来构建parse大元素的parser。
例如,haskell的ParseC库就有这样几个强大的特性:
-
提供了char、string,基元的parse单个字符或字符串的parser。
-
提供了sat,传一个predicate,就可以parse到符合predicate的结果的parser。
-
提供了try,支持parse过程中的lookahead语义。
-
提供了chainl、chainr,这样就省的我们在构造parser的时候就无需考虑左递归了。不过这个我也是写完了parser才了解到的,所以基本没用上,更何况对于S-expression来说,需要我来处理左递归的情况还是比较少的。
我们可以先根据这些基本的,封装出来一些通用combinator。
比如正则规则中的star:
star :: Parser a -> Parser [a] star p = star_p where star_p = try plus_p (return []) plus_p = (:) p star_p 比如plus: plus :: Parser a -> Parser [a] plus p = plus_p where star_p = try plus_p (return []) "plus_star_p" plus_p = (:) p star_p "plus_plus_p"
基于这些,我们可以做组装出来一个parse lambda-exp的parser(p_seperate是对char、plus这些的组装,表示形如a,b,c这样的由特定字符分隔的序列):
p_lambda_exp :: Parser Exp
p_lambda_exp = p_between '(' ')' inner "p_lambda_exp" where inner = make_lambda_exp <$ char '//' p_seperate (p_parse p_pat) "," p_parse p_exp make_lambda_exp [] e = (LambdaExp NilPat e) make_lambda_exp (p:[]) e = (LambdaExp p e) make_lambda_exp (p:ps) e = (LambdaExp p (make_lambda_exp ps e)) 有了所有exp的parser,我们就可以组装出来一个通用的exp parser:
p_exp :: Parser Exp p_exp = listplus [p_var_exp, p_const_exp, p_lambda_exp, p_app_exp, p_adt_exp, p_list_exp] "p_exp"
其中,listplus是一种具有优先级的lookahead:
listplus :: [Parser a] -> Parser a listplus lst = foldr () mzero (map try lst)
对于parser来说,其输入是源文件其输出是AST。具体来说,其实就是parse出一个Dec数组,拿到AST,供后续的pipeline消费。
我们之前举的AI的例子,parse出来的AST大概是这副模样:
-- Prelude.bh Right [DeclaresDec [ DeclareDec (VarPat "seq") (AppType [GenericType "List" (GenericType "IO" (NormalType "Result")),GenericType "IO" (NormalType "Result")]) ,DeclareDec (VarPat "check") (AppType [NormalType "Bool",GenericType "IO" (NormalType "Result")])]] -- BaseAI.bh Right [DeclaresDec [ DeclareDec (VarPat "HpRateLessThan") (AppType [NormalType "Float",GenericType "IO" (NormalType "Result")]) ,DeclareDec (VarPat "Idle") (GenericType "IO" (NormalType "Result"))]] -- AI00001.bh Right [ ImportDec "Prelude" ,ImportDec "BaseAI" ,DefineDec (VarPat "Root") (AppExp (VarExp "par") (ADTExp "Cons" [ AppExp (VarExp "seq") (ADTExp "Cons" [ AppExp (VarExp "check") (VarExp "IsFleeing") ,ADTExp "Cons" [ AppExp (LambdaExp (VarPat "a")(AppExp (VarExp "check") (AppExp (VarExp "IsNull") (VarExp "a")))) (VarExp "GetNearestTarget") ,ConstExp NilVal]]) ,ADTExp "Cons" [ AppExp (VarExp "seq") (ADTExp "Cons" [ AppExp (VarExp "check") (VarExp "IsAttacking") ,ADTExp "Cons" [ AppExp (LambdaExp (VarPat "b") (AppExp (VarExp "HpRateLessThan") (VarExp "b"))) (VarExp "GetFleeBloodRate") ,ConstExp NilVal]]) ,ADTExp "Cons" [ AppExp (VarExp "seq") (ADTExp "Cons" [ AppExp (VarExp "check") (VarExp "IsNormal") ,ADTExp "Cons" [ AppExp (VarExp "loop") (AppExp (VarExp "par") (ADTExp "Cons" [ AppExp (LambdaExp (VarPat "c") (AppExp (VarExp "seq") (ADTExp "Cons" [ AppExp (VarExp "check") (AppExp (VarExp"IsNull") (VarExp "c")) ,ADTExp "Cons" [ AppExp (VarExp "LockTarget") (VarExp "c") ,ConstExp NilVal]]))) (VarExp "GetNearestTarget") ,ADTExp "Cons" [ AppExp (VarExp"seq") (ADTExp "Cons" [ AppExp (VarExp "seq") (ADTExp "Cons" [ AppExp (VarExp "check") (VarExp "ReachCurrentPatrolPoint") ,ADTExp "Cons" [ VarExp "MoveToNextPatrolPoiont" ,ConstExp NilVal]]) ,ADTExp "Cons" [ VarExp "Idle" ,ConstExp NilVal]]) ,ConstExp NilVal]])) ,ConstExp NilVal]]) ,ConstExp NilVal]]]))]
前面两部分是我把在其他模块定义的declares,选择性地拿过来两条。第三部分是这个人形怪AI的整个的AST。其中嵌套的Cons展开之后就是语言内置的List。
正如我们之前所说,做代码生成之前需要进行一步类型检查的工作。类型检查工具其输入是AST其输出是一个检查结果,同时还可以提供AST中的一些辅助信息,包括各标识符的类型信息等等。
类型检查其实主要的逻辑在于处理Appliacative Type,这中间还有个类型推导的逻辑。形如(/a (Func a)) 10,AST中并不记录a的type,我们的DSL也不需要支持concept、typeclass等有关type、subtype的复杂机制,推导的时候只需要着重处理AppExp,把右边表达式的类型求出,合并一下env传给左边表达式递归检查即可。
这部分的代码:

此外,还需要有一个通用的CodeGenerator模块,其输入也是AST,其输出是另一些AST中的辅助信息,主要是注记下各标识符的import源以及具体的define内容,用来方便各目标语言CodeGenerator直接复用逻辑。
目标语言的CodeGenerator目前只做了C#的。
目标代码生成的逻辑就比较简单了,毕竟该有的信息前面的各模块都提供了,这里根据之前一个版本的runtime,代码生成的大致样子:

总的来说,大致分为这几个模块:Parser、TypeChecker、CodeGenerator、目标语言的CodeGenerator。再加上目标语言的runtime,基本上就可以组成这个DSL的全部了。上面列出来的代码风格比较混搭,毕竟是前后差的时间比较久了。。parser部分大概是7月左右完成的,那时候喜欢applicative的风格,大量用了<$><*>;后面的TypeChecker和CodeGenerator都是最近写的,写monad expression的时候,Maybe Monad我比较倾向于写原生的>>=调用,IO Monad如果这样写就烦了,所以比较多的用了do-notaion。优化什么的由于时间原因还没看RWH的后面几章,而且DSL的compiler对性能需求的优先级其实很低了,所以暂时没有考虑过,各位看官将就一下。
再扩展runtime
对比DSL,我们可以发现,DSL支持的特性要比之前实现的runtime版本多。比如:
runtime中压根就没有Closure的概念,但是DSL中我们是完全可以把一个lambda作为一个ClosureVal传给某个函数的。
缺少对标准库的支持。比如常用的math函数。
基于上面这点,还会引入一个With结点的性能问题,在只有runtime的时候我们也许不会With a<- 1+1。但是DSL中是有可能这样的,而且生成出来的代码会每次run这棵树的时候都会重新计算一次1+1。
针对第一个问题,我们要做的工作就多了。首先我们要记录下这个闭包hold住的自由变量,要传给runtime,runtime也要记录,也要做各种各种,想想都麻烦,而且完全偏离了游戏AI的话题,不再讨论。
针对第二个问题,我们可以通过解决第三个问题来顺便解决这个问题。
针对第三个问题,我们重新审视一下With语义。
With语义所要表达的其实是这样一个概念:
把一个可能会Continue/Lazy Evaluation的计算结果,绑定到一个variable上,对于With下面的子表达式来说,这个variable的值具有lexical scope。
但是在runtime中,我们按照之前的写法,subtree中直接就进行了函数调用,很显然是存在问题的。
With结点本身的返回值不一定只是一个IO
举例:

这里Math.Plus属于这门DSL标准库的一部分,实现上我们就对底层数学函数做一层简单的wrapper。但是这样由于C#语言是pass-by-value,我们在构造这颗With的时候,Math.Plus(a, 0.1)已经求值。但是这个时候Box的值还没有被填充,求出来肯定是有问题的。
先明确下函数调用有哪几种情况:
-
对UnitAI,也就是外部世界的定义的接口的调用。这种调用,对于AI模块来说,本质上是pure的,所以不需要考虑这个延迟计算的问题
-
对标准库的调用
按我们之前的runtime设计思路,Math.Plus这个标准库API也许会被设计成这样:

如果a和b都是literal value,那就没问题,但是如果有一个是被box包裹的,那就很显然是有问题的。
所以需要对Thunk这个概念做一下扩展,使之能区别出动态的值与静态的值。一般情况下的值,都是pure的;box包裹的值,是impure的。同时,这个pure的性质具有值传递性,如果这个值属于另一个值的一部分,那么这个整体的pure性质与值的局部的pure性质是一致的。这里特指的值,包括List与IO。
整体的概念我们应该拿haskell中的impure monad做类比,比如haskell中的IO。haskell中的IO依赖于OS的输入,所以任何返回IO monad的函数都具有传染性,引用到的函数一定还会被包裹在IO monad之中。
所以,对于With这种情况的传递,应该具有这样的特征:
-
With内部引用到了With外部的symbol,那么这个With本身应该是impure的。
-
With内部只引用了自己的IOGet,那么这个With本身是pure的,但是其SubTree是impure的。
所以With结点构造的时候,计算pure应该特殊处理一下。但是这个特殊处理的代码污染性比较大,我在本文就不列出了,只是这样提一下。
有了pure与impure的标记,我们在对函数调用的时候,就需要额外走一层。
本来一个普通的函数调用,比如UnitAI.Func(p0, p1, p2)与Math.Plus(p0, p1)。前者返回一种computing是毫无疑问的,后者就需要根据参数的类型来决定是返回一种计算还是直接的值。
为了避免在这个Plus里面改来改去,我们把Closure这个概念给抽象出来。同时,为了简化讨论,我们只列举T0 -> TR这一种情况,
对应的标准库函数取Abs。


其中,UserFuncApply就是之前所说的一层计算的概念。UserFunc表示的是等效于可以编译期计算的一种标准库函数。
这样定义:

Message类型的Closure构造,都走FuncThunk构造函数;普通函数类型的构造,走Func构造函数,并且包装一层。
Help.Apply是为了方便做代码生成,描述一种declarative的Application。其实就是直接调用Closure的Apply。
考虑以下几种case:

与之前的runtime版本唯一表现上有区别的地方在于,对于纯pure参数的userFunc,在Apply完之后会直接计算出来值,并重新包装成一个Thunk;而对于参数中有impure的情况,返回一个UserFuncApply,在GetUserValue的时候才会求值。
TODO
到目前为止,已经形成了一套基本的、non-trivial的游戏AI方案,当然后续还有很多要做的工作,比如:
更多的语言特性:
-
DSL中支持注释、函数作为普通的value传递等等。
-
parser、typechecker支持更完善的错误处理,我之前单独写一个用例的时候,就因为一些细节问题,调试了老半天。
-
标准库支持更多,比如Y-Combinator
编辑器化:
国内游戏工业落后国外的一个比较重要的因素就是工作流太落后,要不是因为unity的兴起带动了国内编辑器化风潮,可能现在还有大部分团队配技能配战斗效果都还会对着excel盲配。
AI的配置也需要有编辑器,这个编辑器至少能实现的需求有这样几个:
-
与自己定义的中间层对接良好(配置文件也好、DSL也好),具有codegen功能
-
支持工作空间、支持模块化定义,制作一些prefab什么的
-
支持可视化调试
我们工作室自己做的编辑器是基于java的某个开源库做的,看起来比较炫,但是性能不行。behaviac的编辑器就是纯C#,性能应该不错,没有用过不了解。这方面的具体话题就不再展开了。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

