日前,Google CEO Sundar Pichai 通过 Google 的官方博客宣布了 Google 的机器学习系统 TensorFlow 免费开源的消息。
在 Pichai 宣布 TensorFlow 的同时,微软亚洲研究院发布消息,「微软亚洲研究院于日前将分布式机器学习工具包 (DMTK)通过 GitHub 开源。DMTK 由一个服务于分布式机器学习的框架和一组分布式机器学习算法构成,是一个将机器学习算法应用在大数据上的强大工具包。无论是学术界的研究人员还是工业界的开发者,DMTK 都可以帮助他们在超大规模数据上灵活稳定地训练大规模机器学习模型。」与 TensorFlow 类似,DMTK 提供 API 接口,未来的版本中提供更多的功能和算法。
「AI 会变为可以购买的服务,像亚马逊提供的 API 一样,小的创业公司不需要制造和生产 AI 的能力,可以直接购买服务注入到产品中。」就在 上个月极客公园与 Kevin Kelly 的访谈中 ,他曾以此描述 AI 未来的应用方式。如今一语成谶,AI 真的变为大公司为所有人提供的 API 接口,并且是完全开源的。
写到这里不得不提到早些时候微软推出的牛津计划,你可以理解成基于微软云服务 Azure 的多种 API 接口,之前开放的有人脸识别、语音识别、计算机视觉、语言理解四大类。技术(与人工智能交织的技术)同样以 API 和 SDK 的方式,开放给所有第三方开发者使用。而近日,牛津计划宣布了新工具公开测试版本的开放计划,包括基于人脸识别的面部情绪分析工具等。
日前由微软亚洲研究院主办的 21 世纪的计算大会上,微软亚洲研究院院长洪小文曾以《AI 时代》(Age of AI)为主题发表演讲,其中提到牛津计划便是「Adaptive Intelligence」的代表——今年早些时候风靡社交网络的 How-Old.net,正是微软牛津计划(Project Oxford)API 的应用之一。

不久前,极客公园与微软亚洲研究院的洪小文院长进行过一次访谈,包括技术与表象、人工智能的进展、需要跨越的困境。
「最困难的问题是我们对人的了解还不够多」,洪小文认为我们可能永远不会了解人的创造力和意识是如何产生的,但计算机的「小心求证」仍然无比重要。
极客公园 :小冰、小娜因为跟人接触比较多,大家都很熟悉。微软研究院有哪些技术已经抵达了我们的生活,或者藏在产品中影响了我们的生活,但是我们并没有意识到?
洪小文 :因为计算机和移动互联网的普及,特别是人工智能的发展,用户所想用的东西变成了一种隐形的、无所不在的东西。隐形的另外一层意思是无缝。今天你用的可能是手机,也可能是云服务,同时有物联网和摄像头等。对于用户而言,他们并不需要知道人工智能是发生在云端还是手机端。事实上,现在的人工智能或自然人机界面只需要用语音和面部表情就能完成,这就是一种隐形的创新。我知道很多读者对技术感兴趣,而大多数读者需要的是最直接和可用的技术。大家看到的小冰和小娜,而在背后包含的有计算机图像识别、语音识别、自然语言处理、社交网络情感计算等等技术。
另外,微软的产品很多元化。如果大家使用 Windows 10 就可以发现,以前的系统每一个进化版本都需要更多的内存,但是如今 Windows 10 比 Windows 8 所需要的机器内存容量变得更少。Windows 10 中的小冰和小娜代表了新的技术,Windows 10 已经发展为听你说出指令并且做出反应,我们可以通过说「小冰」发出让机器人运转的指令。同时,我们还在做「Speaker ID」,就是计算机需要对说话者的说话声音和内容进行辨认,而这样的功能都是不为用户熟知的。
还有跟生物信息有关的技术,比如人脸识别、指纹识别、瞳孔识别和虹膜识别等,我们可以在很暗的光线下使用红外线技术进行人脸识别。我们把这些都加入到 Windows 和其他应用服务当中。
在 10 月披露的微软财报当中,智能云(intelligent cloud)是一大亮点,包括像今年推出的牛津计划(Project Oxford)和前段时间出现的 How-Old.net 等。我们一开始推出 How-Old.net 只是进行技术展示,但是现在变得很流行、应用范围更广,比如我们可以实现对上百人的公司进行人脸识别。我们也把一款名为 Windows Hello 的生物信息技术搬到了智能云。在将来,大家可以看到更多智能云的应用,而传统 Windows 应用软件开发商也会利用我们的技术改进他们的系统。
极客公园 :微软研究院一直做一些前瞻性研究,也取得了很多成绩。您能介绍一下最近的进展吗?
洪小文 :牛津计划是我们的一个系列或品牌,我们在今年推出一部分,到明年年初还会有更新的技术。这些技术主要包括:
第一个是语音识别。语音的应用范围很广,包括物联网等。目前不仅微软的平台,像中国也有自己的语音技术平台等等。
第二个是语言理解智能服务(LUIS)。这里面主要是自然语言处理技术,比如我们的微软学术搜索就实现了从关键词搜索到自然语言搜索的技术飞跃,还没有输入完搜索内容机器就可以猜测出你想要搜索的内容。同时,该服务还可以对知识按照不同领域范围进行分类。例如,有开发人员想要做一个自然语言搜索的应用,那么他可以通过利用牛津计划所提供的自然语言 API 来实施。
第三类是图像(计算机视觉和人脸识别)。帮助用户在上千种物种当中搜索到既定目标,比如说在必应上面进行图片搜索,可以找到十亿以上或百亿以上数量级的资源。
 风靡一时的 How-Old.net,使用的就是牛津计划的 API 服务
风靡一时的 How-Old.net,使用的就是牛津计划的 API 服务
搜索的规律分为两种,一种是重复、复制,比如说如果你搜索的照片跟网上某个照片很接近,很多时候是在复制;第二种是相似,比如这个房间我在这个角度照和那个角度照相差别很多,其实是相似的。人脸识别技术就是根据人的一些特性,比如年龄、性别、人种(黄种人、白种人)、表情(普通表情、笑、忧伤、哭泣)等进行区分。很多人会根据这些方面去做一些不同的应用。这个是我们在智能云里面的一个巨大尝试。
此外,还有可视化技术(visualization),也就是做大数据分析。我们通过表格把数据可视化,这些都是智能云里面非常重要的项目。微软最近的产品不仅仅代表了研究院的技术而且也预示着更加深入和广阔的发展前景。我们现在推出的产品只是一部分,未来可以做的东西还非常多。
极客公园 :过去一年人工智能有哪些进展让您感到兴奋?
洪小文 :业界、学术界的许多人都在谈人工智能、机器学习或大数据,我认为在很大程度上这三样是一件事。因为人工智能有很多不同的领域,但是今天的人工智能百分之八九十是收集数据之后去进行机器学习。
可以说我们人类文明的进展都是大数据。先从科学的角度来看待这个问题。当代的科学之父伽利略通过观察发现运动跟物质的大小无关,发现地球不是宇宙的中心,可能是太阳。这样的结论在当时受到了很多人的挑战。
我们做实验或做产品,会有一个假设,我们会收集资料、数据来验证假设。收集资料之后发现假设需要修改,或发现需要再做一个实验,或要修改实验部分的内容再循环一次。这是一种闭环反馈或者试错。现在很多电视剧,也是每天写剧本,根据观众的反应再进行修改。许多过程都是这样的循环,通过每一个循环可以慢慢进步。农业、工业也是这样。
这就叫大数据,有了移动互联网之后,大数据飞速发展。有了互联网,内容就变成数字化,利用移动互联网,可以很快地让用户帮我们做实验。比如新一代互联网创新就是把一个想法先让用户体验来看用户的反馈,根据反馈确定修改的方向,再来改进。科学家、互联网公司、任何人都可以通过这种方法达到最优的状态。人工智能、机器学习都是这种运作的方式。
这就造就了数据为王的时代,反馈回路越快到达,就相当于可以在相同时间里做更多的实验,也就可以取得胜利。以前很多人要一年、十年或一个世纪才能得到反馈,现在可以得到反馈很快地去改善,可以预见未来会更快。现在有一个新的称呼是数据科学家(data scientist),每天通过看大量数据,看用户反馈、脉动等等,包括市场调查等,利用数据去解决问题。
在这个过程中,如何能够不遗漏数据,让数据为我所用,微软投入了许多心血。不仅是对人工智能、机器学习、大数据,包括里面传统的数据库、系统、网络上都使用了大数据技术。其中,速度很重要。大数据的搜集是一方面,数据处理的速度如果没有,那数据就没有意义。
更深入一点是跟技术有关的。比如一个人博学多文,意思是这个人知道很多数据、很聪明。但是另外一方面,有时他因为信息不够而难以决定,这并不代表这个人很笨。更何况许多事情牵涉到商业机密、国家机密或个人隐私,正常人是没有办法知道的。回到人工助手的问题,我的人工助手知道我喜欢坐哪班飞机、坐哪个位置,如果突然换一个人工助手可能就不知道我的偏好了,因为它还没收集到我的数据。因此我认为凭借数据量的大小来判断一个机器是否智能是值得商榷的。
到最后还有隐私权和安全的问题,用户可能不希望自己的所有嗜好都被机器知道,但是他又想要方便。让哪一个程序和服务知道呢?这不是简单的问题,因为它牵涉到国家安全、公司商业安全。
讲到人工智能,一般人工智能是做算法,但是信息多了之后的确是会比较聪明。我认为未来一个大的方向,是如何通过机器和人的结合使得人类变成「超人」。因为人善于思考,但是人会忘事,计算有时也可能算错、可能看不清所有的东西,但是机器可以。机器看东西可以通过扫描,但是要用人的算法去提取知识。假设,我是做证券交易的,我希望看到今天所有公司与股票有关的数据。机器可以扫描比人眼看到更多的数据,但是扫描之后还是识别不出涨跌,就需要用到人类的算法。人类如果能够和机器结合,就可以做出最好的证券交易或推荐。这就是未来的兵家必争之地。
但是信息安全是未来一个很重要的问题。在这个过程中什么信息可以让什么样的人、什么样的程序看到,是一个很大的问题。因为牵涉到了安全、个人隐私方面的问题,这也是将来很重要的研究方向,我们在微软的基础研究、应用研究也在开始尝试。
极客公园 :如果机器给人类帮助,势必要从智能跨越到智力,在这个过程中有哪些困难需要解决?
洪小文 : 最困难的问题是我们对人的了解还不够 ,这其中还会涉及到哲学的东西。人的左脑和右脑,左脑是处理逻辑的事情,科学常常讲大胆假设、小心求证,左脑是小心求证,右脑是大胆假设,右脑就是负责语言和创造力,关键是在创造力。
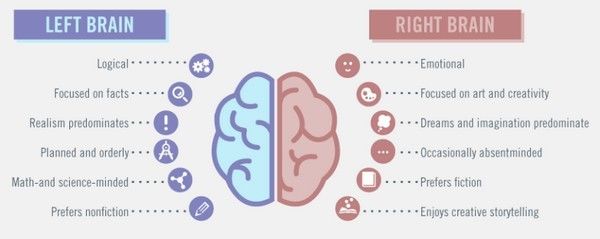 左右脑分工不同,左脑偏向逻辑,右脑偏向情感
左右脑分工不同,左脑偏向逻辑,右脑偏向情感
计算机是最好的左脑。计算机需要人去编写程序,即算法,通过算法人告诉计算机动作的指令。比如开根号,我们通过一个算法,可以让计算机一直开根号。人也可以去开根号,但是有时候会算错。算法有很多重复性的东西,但是机器做重复性的事情不会出错,也不会叫累。算法是人制定的而不是计算机,因为基本没有证据证明,有一个程序可以使程序产生新的算法。
但是创造力是另一回事。今天可以让机器做选择题,基于大数据分析后可能选 A,这个机器可以做到很好。但是人不是这样,人可以说不是 A、B、C、D 的任何选项,而提出一个新的选项,这就是创造力。爱因斯坦自己也很难说为什么他会想出相对论。如果这能够讲清楚,岂不是能够产生许多个爱因斯坦,这是无法实现的。很多时候我们的创造讲不清楚原由,可能与以前的经验有关,但也讲不清楚。如果人类了解了创造力的产生过程,我想就有可能教会计算机,最难的就在这里。可能我们永远不会了解到,那更不要说人的意识。笛卡儿说「我思故我在」,意思是我是有意识知道做这件事情、为什么做这件事情,也知道你会怎么看我做这件事情。今天计算机都是大数据分析,像数学问题在不断优化自己的结果。小冰在与用户交谈的时候,可以不回答这个问题,做一些类似有情感、明知而不说的反应。但是这样做很有限,不像人类每件事情都是有意识的。甚至许多聪明的动物都还没有自我的意识。
有趣的是人睡觉的时候是没有意识的。人之所以成为人,与机器还是有非常大的差别。机器到目前为止证明的是能成为最好的左脑,但是右脑真的不知道怎么去做,人对右脑的理解也是不够的。
我更相信人加机器变成一个超人, 所以人工智能(AI)的 A 本来是 Artificial,我觉得 A 应该变成增强(Augment) 。博学广闻也是一种智慧,人不可能读所有的书,但是机器可以。但是让机器去扫描很简单,可机器读了以后不去理解就没有意义了,其中还是需要人的算法。如果人的算法能够想清楚,至少对于特定的行业,可以叫机器去读一些文章,然后反馈一些总结或是图表的呈现,来帮助我们优化算法,在此基础上再去看文章。这样配合,未来人类很有可能用电脑来帮助左脑的能力。左脑算法来小心求证,右脑算法来大胆假设,两者都是很重要的。
传统理工科主要利用左脑,右脑的创造力在将来是最了不起的。右脑不仅是计算机无法取代的,而且是人类最珍贵的东西,是我们强调的创造力。当然只有大胆假设也不行,计算机的小心求证也是必要的。
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

