概述
这段时间花了部分时间在处理 消息总线 跟日志的对接上。这里分享一下在日志采集和日志解析中遇到的一些问题和处理方案。
日志采集-flume
logstash VS flume
首先谈谈我们在日志采集器上的选型。由于我们选择采用ElasticSearch作为日志的存储与搜索引擎。而基于ELK(ElasticSearch,Logstash,Kibana)的技术栈在日志系统方向又是如此流行,所以把Logstash列入考察对象也是顺理成章,Logstash在几大主流的日志收集器里算是后起之秀,被Elastic收购之后更加成熟,社区也比较活跃。
Logstash的设计: input , filter , output 。flume的设计 source , channel , sink ,当然flume也有 interceptor 。具体的设计就不多废话,大致上都是 拆分 , 解耦 , pipeline(管道) 的思想。同时,它们都支持分布式扩展,比如Logstash既可以作为shipper也可作为indexer,flume可以多个agent组成分布式事件流。
我对flume的接触早于Logstash。最近调研Logstash的时候,对它强大的filter印象深刻,特别是 grok 。而之前flume阵营强调最多的是它的source,sink,channel对各种开源组件的扩展支持非常强大。
Logstash固然是一个不错的,但它采用 JRuby 语言(一种形似Ruby语法的JVM平台的语言)实现使得它的 定制性不够灵活 ,这是我放弃Logstash的主要原因。因为生态的原因,我确实需要Java技术栈提供的扩展性(这里主要目标是将 消息总线 作为日志采集的缓存队列),而这正是flume的强项。但flume里很少有提及对日志的解析支持,即便有支持正则的interceptor,也只是很有限的查找、替换之类的。经过一番调研发现其实flume提供了这样一个interceptor—— morphline 。它可以完成对日志的解析。
日志解析-morphline
morphline简介
morphline是由flume的母公司cloudera开源的一个ETL框架。它用于构建、改变基于Hadoop进行ETL(extract、transfer、load)的流式处理程序。(值得一提的是flume是由cloudera捐献给Apache的,后来经过重构成了flume-ng)。morphline使得你在构建ETL Job不需要编码并且不需要大量的MapReduce技巧。
morphline是一个富配置文件可以很简单得定义一个转化链,用于从任何数据源消费任何类型的数据,处理数据然后加载结果到Hadoop组件中。它用简单的配置步骤代替了Java编程。
morphline是一个类库,可以嵌入任何java程序中。morphline是一个内存容器可以存储转化命令。这些命令以插件的形式被加载到morphline中以执行任务,比如加载、解析、转化或者处理单条记录。一个记录是在内存中的名称-值对的数据结构。而且morphline是可扩展的,可以集成已存在的功能和第三方系统。
这篇文章不是morphline的软文,所以更多介绍请移步 cloudera的CDK官方文档 。
这里有副图,形象地展示了morphline大致的处理模型:

这里还有一幅图,展示了在大数据生态系统中,morphline的架构模型:
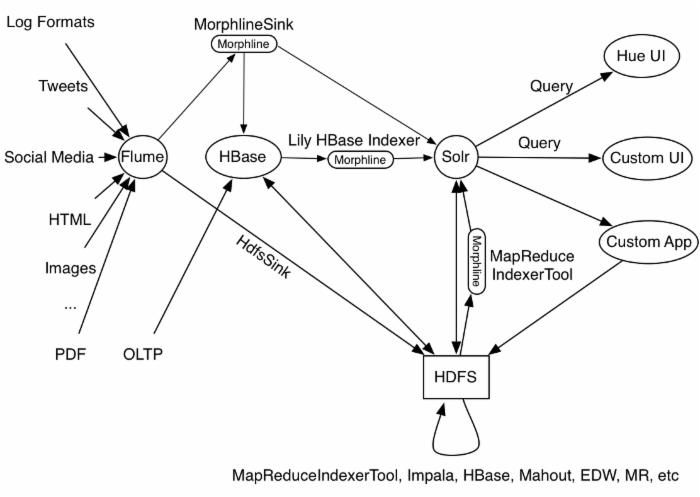
后来morphline的开发主要由Kite主导,它是构建于Hadoop上的一套抽象的数据模型层的API接口。这里有 kiteSDK关于morphline的文档说明 。
强大的正则提取器——grok
其实我找morphline就是为了找grok,或者找到一种提供grok的切入口。grok利用正则的解析能力从非结构化的日志数据中提取结构化的字段。因为Logstash已经提供了一大堆的经过验证的grok规则,这是Logstash的优势,如果能够将这些规则直接在flume里使用,那么将能够直接集成Logstash的能力(其实,只要有文本是规则的,正则都能提取出来,但已经有成熟的东西就没必要自己再花费巨大的功夫去验证)。这里有 grok的说明文档 ,就不再过多介绍了。
服务端使用morphline
flume在agent里利用morphline。在client端对日志进行ETL的优势可以利用客户端PC分散的计算能力以省去服务端解析的麻烦,但agent的数量非常之多,而且散布在各个生产服务器上,日志的格式也是五花八门。也就是说,在agent做太多的事情将使得我们在应对改变的时候缺乏灵活性。所以,我们在客户端只收集不解析。而在服务端利用morphline对日志进行解析。相当于启动一个解析服务,从日志采集队列中提取日志,用morphline进行解析转换,然后再将解析过的更结构化的日志发送到索引队列,等到索引服务将其存入ElasticSearch。整个过程大致如下图:
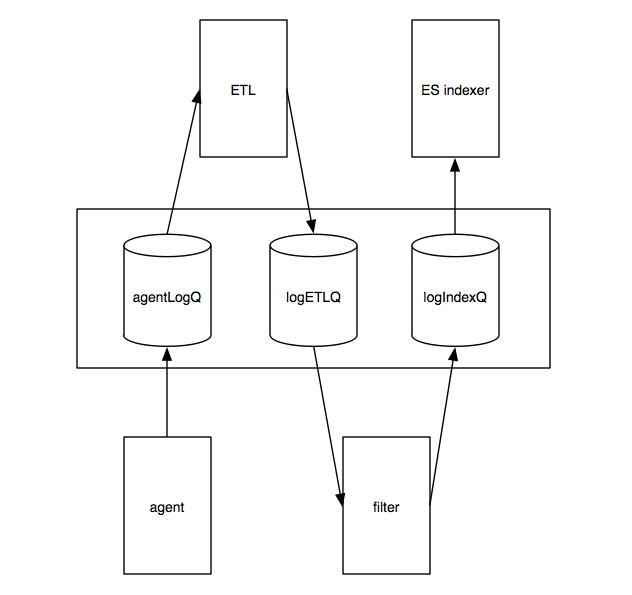
这种异步的基于队列的pipeline其实跟Storm这样的流处理器的同步pipeline本质上殊途同归,都是在利用廉价的PC来平摊计算量。
程序示例
为了在你的程序中使用morphline,首先需要添加对morphline的maven依赖:
<dependency>
<groupId>org.kitesdk</groupId>
<artifactId>kite-morphlines-all</artifactId>
<version>${kite.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
</exclusions>
<type>pom</type>
<optional>true</optional>
</dependency>
版本是 1.0.0 。需要注意的是,这里面有些依赖,需要从twitter的仓库里去下载,所以你懂的:请自备梯子。
示例程序:
private void process(Message message) {
msgBuffer.add(message);
if (msgBuffer.size() < MESSAGE_BUFFER_SIZE) return;
try {
Notifications.notifyBeginTransaction(morphline);
for (Message msg : msgBuffer) {
Event logEvent = GSON.fromJson(new String(msg.getContent()), Event.class);
String originalLog = new String(logEvent.getBody());
logEvent.getHeaders().put(MORPHLINE_GROK_FIELD_NAME, originalLog);
logEvent.setBody(null);
Record record = new Record();
for (Map.Entry<String, String> entry : logEvent.getHeaders().entrySet()) {
record.put(entry.getKey(), entry.getValue());
}
byte[] bytes = logEvent.getBody();
if (bytes != null && bytes.length > 0) {
logger.info("original : " + new String(bytes));
record.put(Fields.ATTACHMENT_BODY, bytes);
}
Notifications.notifyStartSession(morphline);
boolean success = morphline.process(record);
if (!success) {
logger.error("failed to process record! from : " + morphlineFileAndId);
logger.error("record body : " + new String(logEvent.getBody()));
}
}
//do some ETL jobs
List<Record> records = this.extract();
List<Event> events = this.transfer(records);
this.load(events);
} catch (JsonSyntaxException e) {
logger.error(e);
Notifications.notifyRollbackTransaction(morphline);
} finally {
//clear buffer and extractor
this.extracter.getRecords().clear();
this.msgBuffer.clear();
Notifications.notifyCommitTransaction(morphline);
Notifications.notifyShutdown(morphline);
}
}
这里只是部分代码,展示morphline的大致用法。主要的逻辑在配置文件中:
morphlines : [
{
id : morphline1
importCommands : ["org.kitesdk.**"]
commands : [
{
grok {
dictionaryString : """
"""
expressions : {
original : """"""
}
extract : true
numRequiredMatches : atLeastOnce # default is atLeastOnce
findSubstrings : false
addEmptyStrings : false
}
}
{ logInfo { format : "output record: {}", args : ["@{}"] } }
]
}
]
如上所述,我们最主要的是想利用grok来解析日志,而logstash已经提供了 大量的grok patterns 供你开箱即用,但对于自定义的日志格式类型,你通常都需要自行解析。这里有个 grok 在线debug工具 。
综述
其实,业界使用flume都是规模较大的互联网公司,比如美团。它们通常会使用flume+kafka+storm+hadoop生态系统。利用storm stream做实时解析,利用mapreduce做离线分析,这种高度定制化的使用场景,几乎不需要flume的agent在客户端进行解析的能力,因此flume的morphline也就很少被提及。
但morphline还是不可多得的文本ETL利器,无论你是在采集的时候直接用morphline 做ETL还是在服务端做,flume+morphline加起来带来的灵活性也不输Logstash。
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

