产生背景
简介
历史
架构
查询流程和事例
IMPALA Presto HIVE
Presto TODO 9
Reference 9产生背景
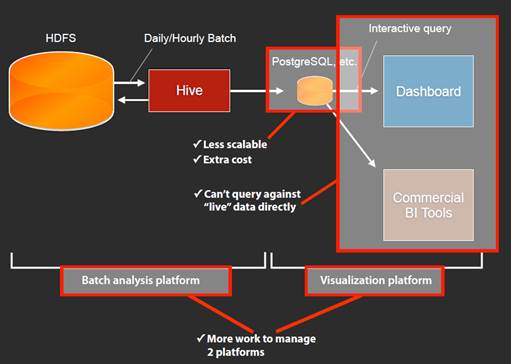
数据量急速增长到了 PB 量级,查询有这么大数据量的数据库出现问题,我们需要运行更多的交互式查询并快速获得结果。虽然 HDFS 支持大数据存储,但是不能通过面板或者 BI 工具直观展现,因为 HIVE 太慢或者 ODBC 还不可用。
Presto 是由facebook开发的一个分布式SQL查询引擎, 它被设计为用来专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。它采用 Java 实现。它的数据源包括 HIVE、HBase、关系数据库,甚至专有数据存储。
2012 年秋天 Facebook 启动 Presto 项目,目的包括交互式查询、加速商业数据仓库以及扩展 Facebook 处理数据的规模。2013 年春季在整个 Facebook 使用。2013 年冬天在 Github 上开源。在最初的 6 个月有 30 多个 contributor,其中还有 Facebook 外部开发者。到现在有 99 个 contributor,包括 129 个Release,6000+ commits。
HDFS 一般数据分析框架:
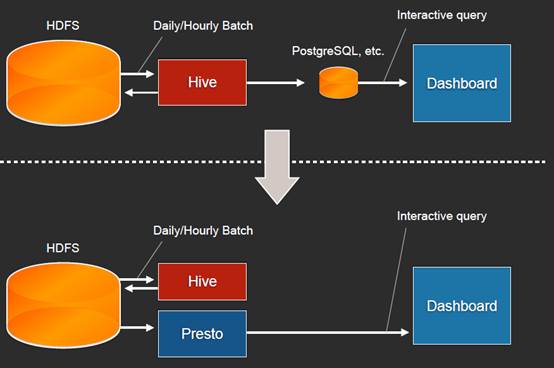
Facebook 希望做成这样:
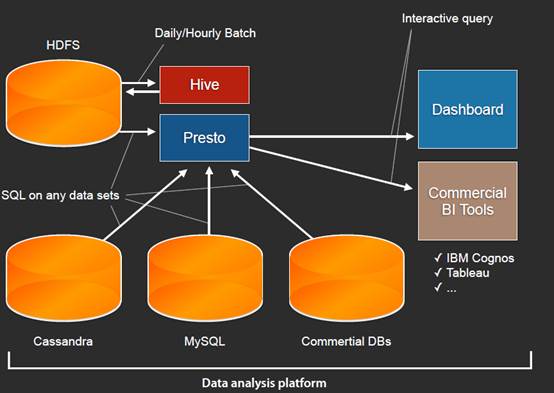
然后再扩充数据源:
Presto分布式框架:
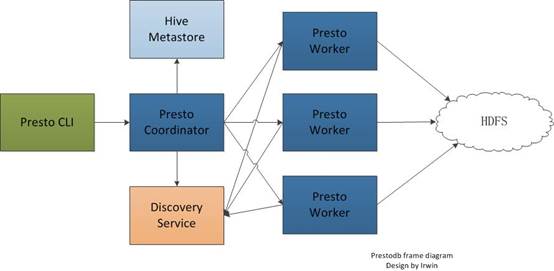
下面的架构图中展现了简化的Presto系统架构。客户端(client)将SQL查询发送到Presto的协调员(coordinator)。协调员会进行语法检查、分析和规划查询计划。计划员(scheduler)将执行的管道组合在一起,将任务分配给那些里数据最近的节点,然后监控执行过程。客户端从输出段中将数据取出,这些数据是从更底层的处理段中依次取出的。
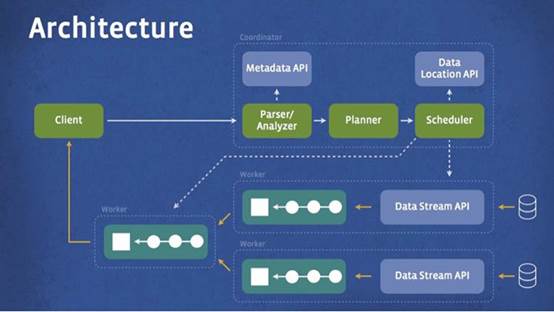
Presto 的运行模型和 Hive 或 MapReduce 有着本质的区别。Hive 将查询翻译成多阶段的 MapReduce 任务,一个接着一个地运行。每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然而Presto引擎没有使用MapReduce。为支持 SQL 语法,它实现了一个定制的查询、执行引擎和操作符。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的时候就会将数据从一个处理段传入到下一个处理段。这样的方式会大大的减少各种查询的端到端延迟。
Presto 动态编译部分查询计划为字节码,使得 JVM 能够优化并生成本地机器码。
在扩展性方面,Presto 只设计了一种简单的存储抽象,使得能够在多种数据源上进行 SQL 查询。连接器只需要提供获取元数据的接口,获得数据地址后自动访问数据。
至于缺点方面,Presto 对表的连接以及 group by操作有比较严格的大小限制,这可能是因为所有数据处理都是在内存中完成。另外 Presto 查询的结果只会返回到客户端,还不支持写回到表。
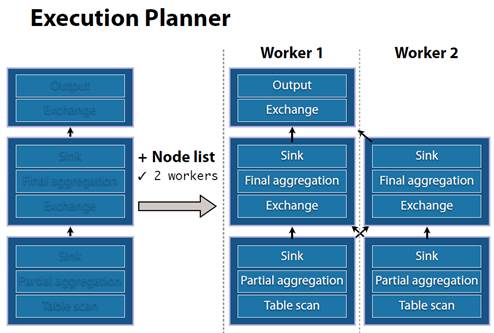
查询流程和事例
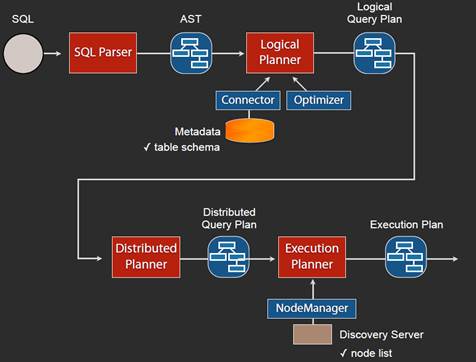
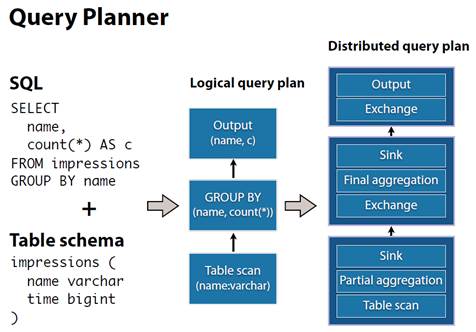
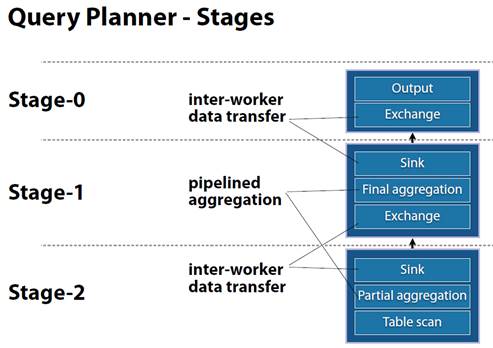
如果有2个worker:
IMPALA Presto HIVE
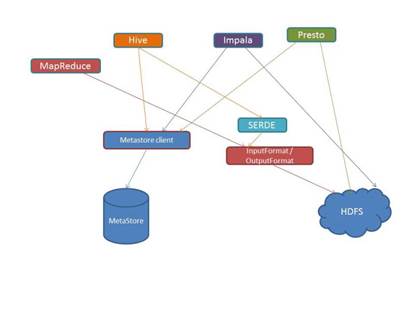
下面是 Hive、Impala、Presto 和 HDFS 交互的示意图
总的来说,Hive 把 HiveQL 查询语句转换为一系列 MapReduce 任务,而 Impala 和 Presto 则受 Google Dremel 论文的启发,实现了自己的分布式查询引擎。
HiveQL
这三者之间的一个共同点是它们都支持称为 HiveQL 的公共标准。尽管 HiveQL 是基于 SQL,但它并不严格支持 SQL-92。
ØHive 如何工作
Hive 维护它自己的元数据存储,其中存储了模式定义、表定义、数据保存所在节点等信息。有一个 Hive 元数据存储客户端,以服务的方式向外暴露元数据信息。它可以通过 Thrift 访问,这使得 Hive 元数据存储能方便地和外部系统交互。这也使得 Impala 和 Presto 可以使用现有的基础在上面继续开发(Impala 和 Presto 都可以使用 Hive 存储元数据)。
Hive 获取 HiveQL 查询语句,经过语法解析形成一系列的 MapReduce 作业。
ØImpala 和 Presto如何工作
Impala 和 Presto 都使用 Hive 元数据存储引擎获得节点信息。然后它们直接和name node 以及 hdfs 文件系统交互,并行执行查询。然后合并结果并以流的形式返回给用户。整个过程都在内存中完成,因此可以消除MapReduce作业带来的磁盘IO延迟。
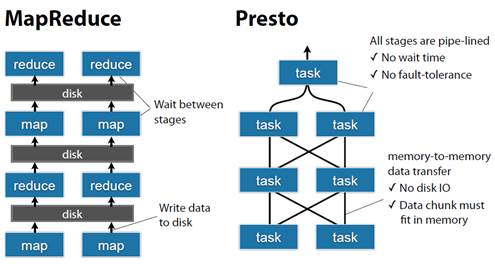
ØHive
| 优势 | 缺点 |
| 已经发布5年,可以说是成熟的解决方案 | 由于使用了MapReduce,它有所有MapReduce的缺陷,例如昂贵的shuffle过程和巨大的IO开销 |
| 运行在原生的MapReduce框架之上 | 仍然不支持多个reducers,使得group by、order by等查询语句非常慢 |
| 高度支持用户定义函数 | 和其它对手相比性能差的比较大 |
| 能轻易的和 HBase 等系统结合 |
ØCloudera Impala
| 优势 | 缺点 |
| 轻量快速,支持几乎近实时查询 | 对运行的查询无容错处理,如果某个节点失败,必须重新发送查询请求,而不能从失败的地方恢复继续。 |
| 计算都在内存中完成,极大地减少了延迟和磁盘IO开销 | UDF支持不完善 |
ØFacebook Presto
| 优势 | 缺点 |
| 轻量快速支持近实时交互查询 | New born,有待进一步观察 |
| 在Facebook得到广泛使用,扩展性和稳定性毋容置疑 | 现在只支持Hive管理的表。尽管网站上说可以在Hbase上查询,但这个功能还在开发状态 |
| 自从开源以来发展势头强劲 | 还不支持UDF,这是最需要添加的功能 |
| 使用分布式查询引擎,和传统的MapReduce相比消除了延迟和磁盘IO开销 | |
| 文档完善 |
下面是第三方机构 Radiant Advisors 关于 Hive、Impala、Presto 和 InfiniDB的一个 Benchmark 对比:
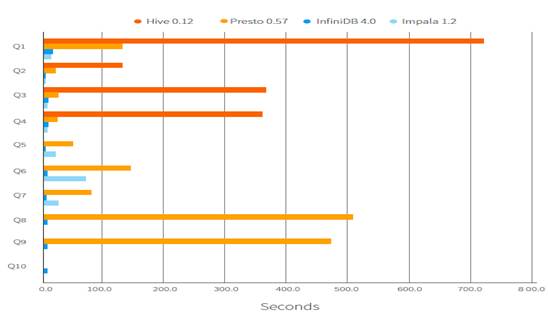
| 支持查询数/10 | 用时/s | |
| InfiniDB | 10 | 1.28-17.62 |
| Impala | 7 | 3.1-69.38 |
| Presto | 9 | 18.89-506.84 |
| Hive0.11 | 7 | 102.59-277.18 |
| Hive0.12 | 7 | 91.39-325.68 |
其中Hive支持的7个查询中有3个由于资源问题没有执行完成。
Presto TODO
ØHuge JOIN 和 Group by
ØSpill to Disk,Insert
ØTask 恢复
现在某个task fail 时,所有 task 也会 fail,也就是 query fail(worker doesn’t die);另外,内存不够也会导致查询失败。
Øcreate view
Ø本地存储 cache host data
ØAuthentication and permission
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

