http协议基础
由来
自人类有了文字之后,用来记事、著书、立说乃至写情书,用的文本之间都是以线性结构组织的,各个文本之间不能有链接跳转。比如有个妹子在看情书的时候想点个链接跳到男朋友信上说给买的爱疯6的介绍上去,这在当时是办不到的。
于是在1945年的“大西洋月刊”由Vannevar Bush发布了一篇关于文本的新结构:非线性结构,该篇文章呼唤在有思维的人和所有的知识之间建立一种新的关系。但在当时的条件下,Bush的思想并没有变成现实。
直到1965年 美国 学者 Ted Nelson 创造了超文本这个术语,即“ 非连续性著述,分叉的、允许读者作出选择、最好在交互屏幕上阅读的文本 ”,各文本之间 通过链结可以跳转 。但是具体到这些超文本如何展示在交互屏幕上,如何组织乃至于如何传输交换这些超文本,Nelson大爷就果断的把这些留给了后人去实现,深藏功与名。
1989年,由 Tim Berners-Lee 及其团队终于没有辜负Nelson大爷对后人的期望,发明了最初的Web服务器和展示这些超文本的Web浏览器,及其用于描述超文本之间关系的标记语言HTML,当然还有用于在Web服务器和浏览器之间传输超文本的协议,也就是我们今天介绍的超文本传输协议HTTP。
工作机制

我们先来看下HTTP的工作步骤:
- 首先客户端发送HTTP请求服务器建立起TCP连接
- 连接建立起之后,客户端开始发送请求
- 服务器在接收到请求之后,开始进行相应的处理
- 服务器把处理后的结果返回给客户端
- 客户端通过浏览器解析响应内容生成页面
下面我们用Chrome浏览器打开一个页面,并用F12->Network->Timing看下其中的各个步骤,如下示例:
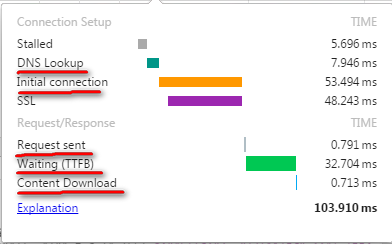
DNS Lookup用来定位服务器地址的
Initial Connection就是上面说到的第1步:建立TCP连接
Request Sent就是第2步,发送请求
Waitting 是等待服务器返回第1个字节的时间,这里先简单的理解为服务器处理时间,对应第3步
Content Download 从服务器端接收完所有的响应数据,对应第4步
以上为HTTP的一个大概流程,下面我们来看下上文提到的“请求”和“响应”的组成
HTTP报文组成
请求报文和响应报文都是由 起始行 、 头部 和 主体 部分组成,其中其实行和头部是必须有的,主体部分是可选的,下图是用Fiddler抓的一个GET请求报文,各位可以观察一下的组成:

- 请求行:提供HTTP方法、URL、及HTTP协议版本信息,常见的HTTP方法有GET、POST
- 请求头:给服务器提供一些额外信息,常用的比如有客户端类型、Cookie、缓存控制等,这些在后续的文章中会详细解释,请关注我们的公众号
- 请求体:通常POST类的请求会有主体部分,比如载有用户注册信息的表单数据。由于上例中展示的是GET请求,所以图中并没有请求体
同样的,我们再看下回应报文
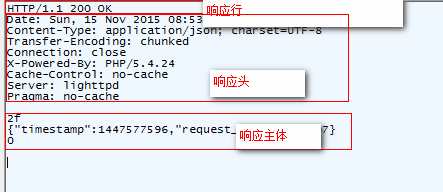
- 响应行:包括请求的结果状态码及状态的摘要信息,比如200代表正常返回,404表示服务器不存在请求的资源,500代表服务器错误
- 响应头:服务器给客户端的额外信息,常用的比如有主体内容类型、缓存控制、传输编码等,这些我们在后续的文章中也会详细解释
- 响应体:主体内容,比如HTML、XML、JSON、图片等
以上只是关于HTTP协议的一个大概介绍,但对与我们作为一个有理想、有情操的屌丝测试来说,知道这些还是远远不够的,在研发面前、在妹子面前还是逼格不起来。不过后续我们还会有更深入、更详细的剖析。每天一分钟!敬请期待!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

