58同城数据库架构学习
上周六去听upyun的技术分享.
其中非常受用的是沈剑老师分享的58同城数据库架构.
58同城都是服务化架构.他们主要的架构如下.
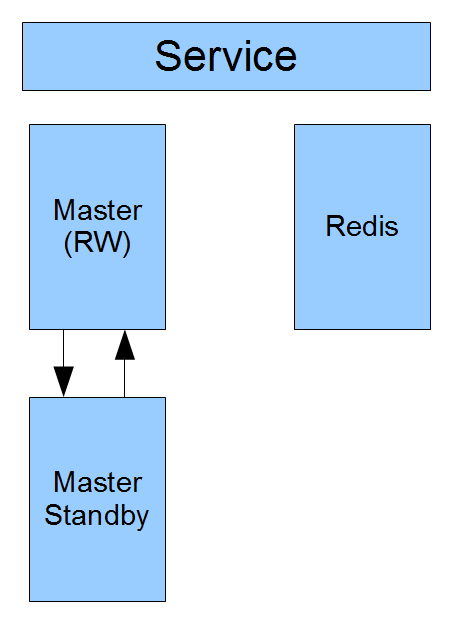
他们每个构建,或者说服务,都是由两个双向同步的数据库和一个redis缓存组成.
一般来说,保障数据库读能力的高可用比较简单,多搭建几个Slave即可.但是M-S架构有同步延迟的问题.
但是保障数据库写能力的高可用,则比较复杂.
因为双向复制问题很多.两个Master的数据可能会相互覆盖.
另外主键生成,也需要应用层使用UUID或者 全局事务ID生成器这种东西
虽然使用步长的方式,也可以使用Auto_increment.但是DBA管理这么多库,谁能记着这么多库的Auto_increment步长的信息呢?
以后万一扩容(原始的DBA可能已经离职),可能会造成数据丢失的事故.所以这种东西,就别留在数据库层坑自己了..
58同城保障读写高可用的方式,还是很巧的.
首先,他们的Service层,都是读写 主Master的数据库,这样读写都在一台库,自然没有同步延迟的问题.
他们的读扩展,并不通过MySQL Slave,而是通过Redis.
这样就可以控制需要实时的数据,直接读数据库;非实时的数据,走Redis缓存.
他们写扩展,是通过一台MySQL Standby数据库实现.
Master和Standby数据库是双向复制的关系.但是平时,这个StandBy数据库没有任何的读写请求.
Master和Standby通过一个VIP对外提供服务.平时VIP指向Master.
一旦Master故障,则切换VIP到StandBy数据库.这样就实现了写的高可用.
这个方案的缺点就是浪费了50%的计算资源.但是我觉得Standby数据库处理一些读请求,也是可以的.
他们不用的原因,也许和我们一样.因为经过SQL调优之后,Master数据库的资源使用率甚至不到10%.
Master尚且用不完,还琢磨StandBy,就没有意义了.
扩容:
这个方案对扩容是非常友好的.
首先,停止双向复制,这时候两个库的数据是一模一样的.
然后,增加分库策略(Hash,范围,路由表)
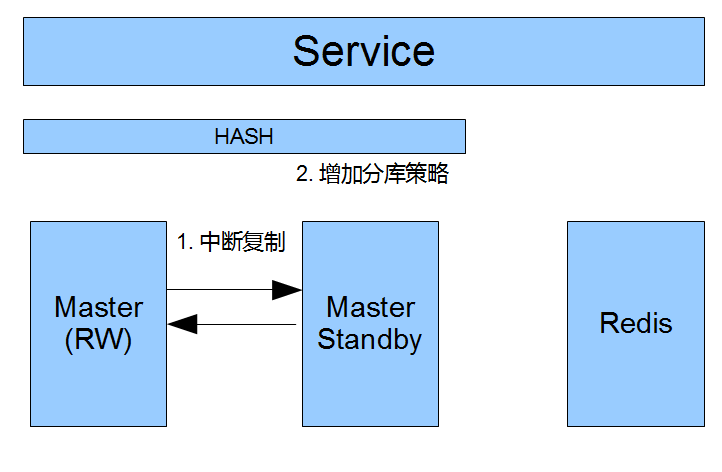
最后,给每个Master,增加StandBy
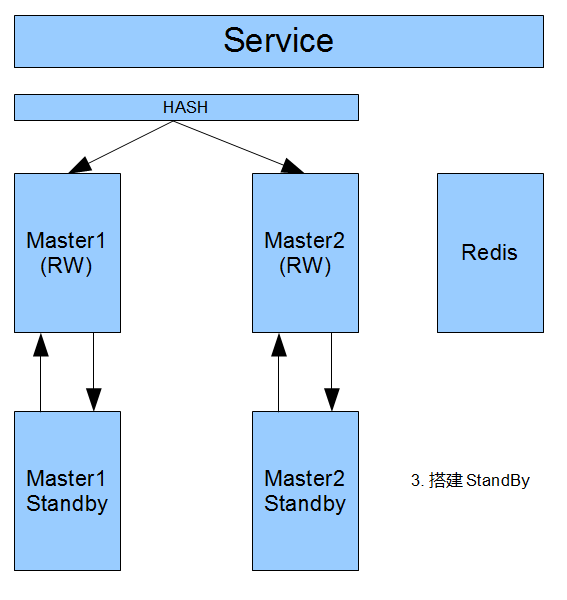
这种扩容的方式,也比较简单.停机的时间很短.但是只能按照倍数扩容.
2台扩4台,4台扩8台,8台就得扩成16台.
如果4台扩展为5台,58同城使用服务层双写的方式,切换之前,校验数据.但是我觉得这种方式侵入代码,对于我们这种公司,基本不现实.因为我们甚至没有服务化...
另外,他们的缓存一致性策略如下
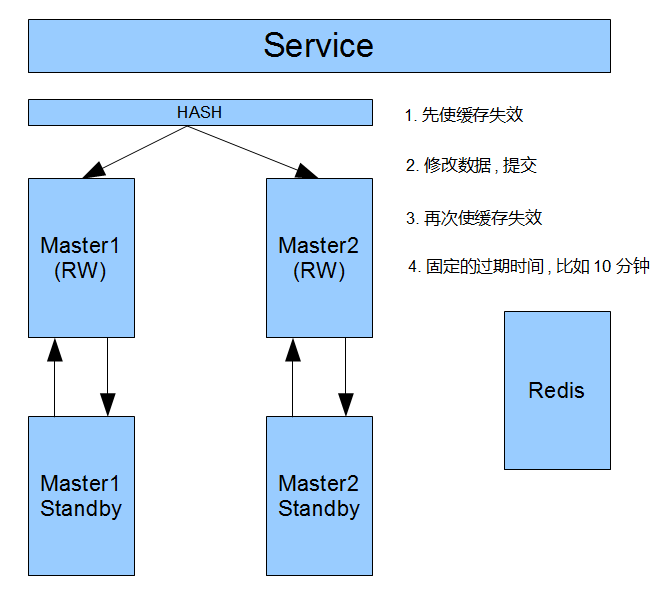
他们第一步先使缓存失效
他们怕先更新数据库,然后再操作缓存的时候,万一失败.则缓存会有不一致的情况.
如果先使缓存失效,出现异常是可以捕获,进而做异常处理.(我觉得这点没必要,如果Redis不能失效,就不让用户提交事务吗?显然也是不合理的)
第二步,修改数据库并提交.
第三步,再次使缓存失效
因为第一步和第二步之间的空隙,如果有读请求,在redis层miss了,则会将旧数据从新读入redis.所以数据库提交之后,要重新使缓存失效.
第一步在我看来,只是Redis是否正常的一个测试.忽略感觉也是可以接受的.
第四步,给每个缓存一个固定的过期时间
这样即使缓存不一致,也可以限制在一个时间范围内.
其中非常受用的是沈剑老师分享的58同城数据库架构.
58同城都是服务化架构.他们主要的架构如下.
他们每个构建,或者说服务,都是由两个双向同步的数据库和一个redis缓存组成.
一般来说,保障数据库读能力的高可用比较简单,多搭建几个Slave即可.但是M-S架构有同步延迟的问题.
但是保障数据库写能力的高可用,则比较复杂.
因为双向复制问题很多.两个Master的数据可能会相互覆盖.
另外主键生成,也需要应用层使用UUID或者 全局事务ID生成器这种东西
虽然使用步长的方式,也可以使用Auto_increment.但是DBA管理这么多库,谁能记着这么多库的Auto_increment步长的信息呢?
以后万一扩容(原始的DBA可能已经离职),可能会造成数据丢失的事故.所以这种东西,就别留在数据库层坑自己了..
58同城保障读写高可用的方式,还是很巧的.
首先,他们的Service层,都是读写 主Master的数据库,这样读写都在一台库,自然没有同步延迟的问题.
他们的读扩展,并不通过MySQL Slave,而是通过Redis.
这样就可以控制需要实时的数据,直接读数据库;非实时的数据,走Redis缓存.
他们写扩展,是通过一台MySQL Standby数据库实现.
Master和Standby数据库是双向复制的关系.但是平时,这个StandBy数据库没有任何的读写请求.
Master和Standby通过一个VIP对外提供服务.平时VIP指向Master.
一旦Master故障,则切换VIP到StandBy数据库.这样就实现了写的高可用.
这个方案的缺点就是浪费了50%的计算资源.但是我觉得Standby数据库处理一些读请求,也是可以的.
他们不用的原因,也许和我们一样.因为经过SQL调优之后,Master数据库的资源使用率甚至不到10%.
Master尚且用不完,还琢磨StandBy,就没有意义了.
扩容:
这个方案对扩容是非常友好的.
首先,停止双向复制,这时候两个库的数据是一模一样的.
然后,增加分库策略(Hash,范围,路由表)
最后,给每个Master,增加StandBy
这种扩容的方式,也比较简单.停机的时间很短.但是只能按照倍数扩容.
2台扩4台,4台扩8台,8台就得扩成16台.
如果4台扩展为5台,58同城使用服务层双写的方式,切换之前,校验数据.但是我觉得这种方式侵入代码,对于我们这种公司,基本不现实.因为我们甚至没有服务化...
另外,他们的缓存一致性策略如下
他们第一步先使缓存失效
他们怕先更新数据库,然后再操作缓存的时候,万一失败.则缓存会有不一致的情况.
如果先使缓存失效,出现异常是可以捕获,进而做异常处理.(我觉得这点没必要,如果Redis不能失效,就不让用户提交事务吗?显然也是不合理的)
第二步,修改数据库并提交.
第三步,再次使缓存失效
因为第一步和第二步之间的空隙,如果有读请求,在redis层miss了,则会将旧数据从新读入redis.所以数据库提交之后,要重新使缓存失效.
第一步在我看来,只是Redis是否正常的一个测试.忽略感觉也是可以接受的.
第四步,给每个缓存一个固定的过期时间
这样即使缓存不一致,也可以限制在一个时间范围内.
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

