mysql 优化(一)
数据库的操作越来越成为整个应用的瓶颈,mysql优化是提高应用性能的重中之重,今天来讲讲最近研究的mysql 的一些性能优化
Mysql的性能优化
(一) 开启查询缓存优化的你查询速度
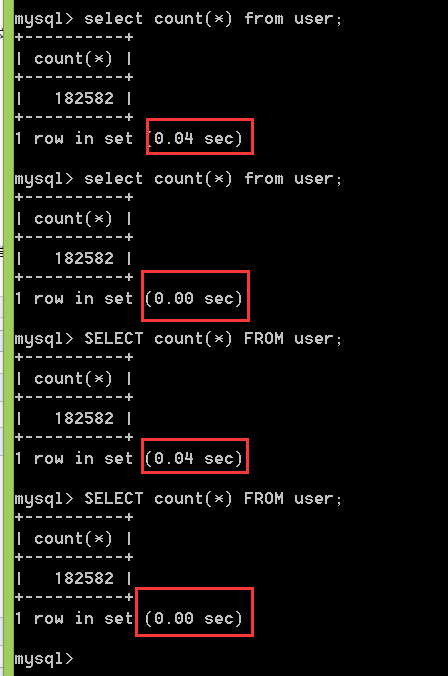
如何开启mysql的查询缓存?你的mysql数据库是否支持mysql查询缓存?? (查询缓存是一把双刃剑,这里就不多说了)
查询缓存的工作流程:
1. 服务器接收SQL,以SQL和一些其他条件为key查找缓存表(额外性能消耗)
2. 如果找到了缓存,则直接返回缓存(性能提升)
3. 如果没有找到缓存,则执行SQL查询,包括原来的SQL解析等.
4. 执行完SQL查询结果以后,将SQL查询结果存入缓存表(额外性能消耗)
打开命令行终端 输入 show variables like "%query_cache%"; 查看你是否开启缓存

这里的参数
have_query_cache: 你的mysql版本是否支持查询缓存
query_cache_size : 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同
query_cache_type: 缓存的方式 有三个值 1) OFF: 关闭 2) ON: 总是打开 3) DEMAND: 只有明确写了SQL_CACHE的查询才会吸入缓存
query_cache_min_res_unit: 分配内存块时的最小单位大小
如果你的 query_cache_type =0 or query_chache_size =0 那么表示没有开启缓存,可以修改配置文件来开启
当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表 而直接访问缓存结果了。
如果你的查询条件有包含一些mysql的内置函数 比如 有时间 now() ,rand()等,那么讲不会缓存.
比较一下下面我执行的sql语句, 当我开启查询缓存的时候 第一次执行所消耗的时间跟第二次执行所消耗的时间 以及相同查询语义但是大小写不一样.(sql语句绝对相等)
(2) EXPLAIN你的查询语句
EXPLAIN关键字能够让你知道索引的使用,如何搜索数据的,扫描行数等等
可以帮助你分析你SELECT 语句的瓶颈因此可以优化你的SELECT语句
选择一个复杂的sql语句

可以看到mysql是怎么样处理你的sql语句
select_type: 有三个参数(simple,primary, union,dependent union,union result) simple 它表示简单的select,没有union和子查询(这里只介绍simple)
table : 出自哪一 张表
type : 显示的访问类型, 从性能最好到最坏以此是 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
表中只有一行;const类型 的特例
2)const: 表中最有有一行匹配,co nst用户比较primary key或者unique索引,因为只有一行,所以很快
3)eq_ref : mysql手册是这样说的:"对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY"。即比较带索引的列
4)ref : 对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。这里的索引不包括 primary和unique.
5)rang : 给定范围内的索引,如 EXPLAIN SELECT * FROM user WHERE id IN (1,5) 或者是 BETWEEN
6)ALL : 全表扫描
possible_key :显示 使用的哪个索引在该表中找到行
key :该查询时所用到的索引
key_len :使用索引的长度
ref : ref列显示使用哪个列或常数与key一起从表中选择行。
rows :显示查询时扫描的行数,值越大越不好,所以根据这个可以判断mysql语句的好坏以及建立索引优化
extra:额外的信息
可以根据EXPLAIN你SELECT的查询语句 进行相关的优化
(3) 为你的表合理的建立索引
这里为什么是合理呢,索引不是建得越多就越好,索引太多 对于 UPDATE DELETE INSERT 的效率都会有影响,
上面提到的EXPLAIN SELECT 语句我们可以进行分析
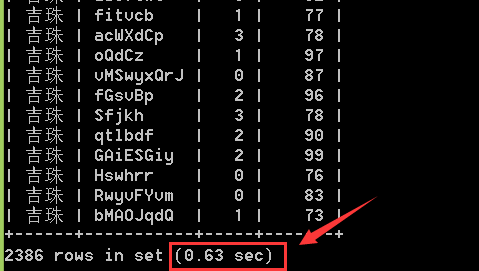
在table user(及table a)中 它的扫描行数是 180207行.而且是全表扫描,没有用到索引,
在命令行中我们来执行以下该sql,查询的时间是0.63sec
我们可以给user表中的school_id加个索引 CREATE INDEX schoolIndex ON `user`(school_id);

这时来看一下查询的时间和EXPLAIN SELECT 语句,
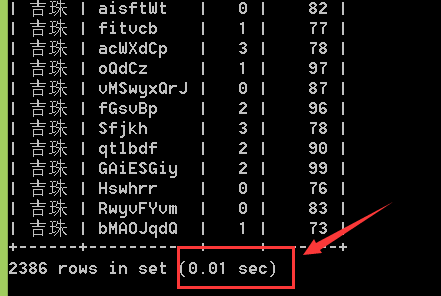

总结:可以很明显的看出 执行时间大大减少了,而且在EXPLAIN中可以看到 type相比于之前的ALL 现在是ref (索引) ,row也相比于180207行到2385行 性能大大的提升了许多
另外需要注意的是:当你的WHERE 后面的条件是 a.name like %陈%; 这样是不会的查询语句 就算你给name加一个索引 也会没有意义.
1、建立多表(三个表或以上)关联视图时,如果是主表和副表都有的字段,尽量使用主表的字段(特别是主表的主键)
2、副表的字段(无论是普通字段还是主键、索引字段)作为查询条件对查询都没有帮助,都需进行全表检索
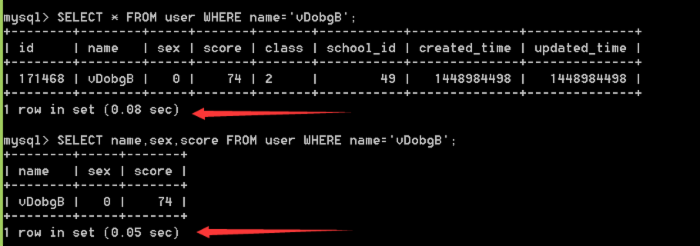
(4)如果查询一条数据的时候使用limit
举个例子 : SELECT * FROM user WHERE name='vDobgB';
当你知道 name='vDobgB'在数据库中只有一条数据的时候使用limit会大大提升效率,这个时候mysql找到该行的时候就会返回这条数据,而不会继续往下查找
(5)在join表的时候 连接条件的字段类型,应当一致,并且将其索引
如果你的应用中使用到了很多表连接查询,应该确认表与表连接字段已经建立了索引,并且两个字段类型是一致的.
向我上面两表连接的字段类型都是int类型,且已经加了索引.如果你要把DECIMAL(小数)类型字段和int(整形)类型的字段连接在一起,那么Mysql就无法使用它们的索引
(6)避免使用 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB 服务器是两台独立的服务 器的话,这还会增加网络传输的负载。
应该养成,需要什么数据就拿什么数据
(7)建立主键索引 即id
为每一个表都建立主键索引 id,而且这个id还是 AUTO_INCREMENT 最好是INT类型 ,
如果你有一张表name是唯一的,并且你给name这个字段设立为主键,这样效率会减低,因为使用VARCHAR类型的主键低于INT类型.
而且,在MySQL 数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如: mysql的分表, 集群等
(8)某些情况下使用ENUM而不是VARCHAR (但是也有一些人说慎用ENUM类型)
如果你的表中的某个字段 例如: 省份,而这个字段经常出现的且只会出现的只有 广东省,福建省,海南省等国家的所有省份.
那么你应该给该字段的类型应该是ENUM而不是VARCHAR.
ENUM 类型是非常快和紧凑的。在实际上,其保存的是TINYINT,但其外表上显示为字符串。
例如,指定为 ENUM("one", "two", "three") 的一个列,可以有下面所显示的任一值。每个值的索引值也如下所示:
| 值 | 索引值 |
NULL | NULL |
"" | 0 |
"one" | 1 |
"two" | 2 |
"three" | 3 |
(9) 使用PROCEDURE ANALYSE()取得建议
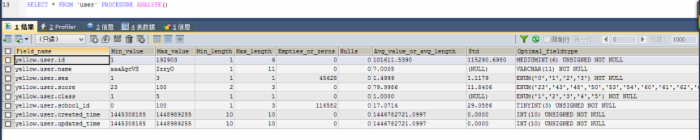
其中 optimal_fieldtype会推荐我们使用怎么样的数据类型,当表中数据了越大的时候,就越准确,但是不一定是完全准确的,你需要思考..哈哈哈哈
(10)建立表的时候使用NOT NULL,而且尽量给表设定默认值
NULL 需要额外的空间,mysql的上的文档是这么说的

如果你的表的字段是int 那么应该给默认值 DEFAULT 0 ,如果是varchar类型 DEFAULT ' '
mysql的部分优化先暂时讲这么多,如果有疑惑的或者是有其他见解的欢迎评论..
今天php7发布了,php7的性能相比于原来提高了百分之40%-200%.
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

