
TSpider 1.6功能介绍
TSpider 1.6功能介绍
【新功能】
1. 增加跨分区操作性能视图,通过Show query_response_times来显示
2. 在参数spider_get_sts_or_crd=1时,支持show table status和show index语句来收集统计信息
3. spider的错误日志增加当前语句和当前库信息
【优化】
1. 解决delete/update .. limit ..语句效率较低的问题
默认情况下,delete/update .. limit .. 无法使用direct_delete/direct_update优化,即都是先查询结果再根据主键逐行删除/更新,这样的效率较低。
解决方式: delete/update .. limit .. 支持direct_delete/direct_update
2. 修改spider_semi_split_read默认值为1,避免limit放大
在spider上执行类似limit语句 select id from test_incr limit 2;在remote每个节点是执行select id from test_incr limit 4; 每次都会将limit扩大2倍,存在无意义的性能损耗。这里是受参数spider_semi_split_read控制,默认为2(表示limit的两倍),现将默认值修改为1。
【Bug Fixed】
1. 修复group by结果错误的问题,涉及两个问题:
a) Select key1, min(key2) from t group by key1; (key1, key2)是一个索引。这个是由于direct aggregate使用不当导致。
b) select key from t group by key; key是索引唯一列
该语句使用了计划Using index for group-by,该优化在spider上不能得到正确结果,禁用该计划。
同理,select count (distinct key) from t;有同样的问题。
2. 解决预读导致spider备份异常的问题
原因分析:在spider_quick_mode = 1时, 执行mysqldump可能失败的原因是remote DB net_read_timeout/net_write_timeout超时。一个表共16个分区,当并发导出时,每个分区预先读取100条记录(pre_scan)。当拉取最后若干分区的数据,时间已超过默认的60s,remotedb就会kill掉当前连接,导致spider获取结果出错。
解决方式:
a) 当指定SQL_NO_CACHE(mysqldump)时,禁用pre_scan优化
b) 另外,新增参数spider_use_pre_scan,控制是否启用pre_scan优化,默认TRUE;
c) 解决insert .. select ..失败的问题
原因同上,解决方式:非select语句禁用pre_scan优化
4. 修改spider对索引的执行优化的bug
Select * from t1_spider where key1 = 1 or key2 = 1; 此语句spider会依次执行where key1=1, key2=1两个索引,再进行result union。对datetime类型会引发crash(修复)。但该spider分发语句方式效率低下,而且可能结果出错(重复结果),通过将index merge相关参数关闭解决。
![]()
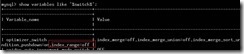
Select * from t1 where key1 = 1 or key1 = 2; 对spider同样会依次分发key1=1,key1=2到后端,优化后则一次性分发key1=1 or key1=2到后期,提升效率。控制参数是index_range,spider上关闭index range行为。
5. 修复时间类型如now()没有在spider正确计算的问题。这可能导致在线迁移数据不一致。
测例:
set timestamp=123456;
update t set c1=now() where id = 10;
spider发给remote的sql直接发的now()函数,故导致时间不对。
6. 修复包含timestamp列,direct_update未处理时间戳的问题。
测例:
CREATE TABLE `test_timestamp` (
`id` int(11) NOT NULL,
`c1` int(11) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=SPIDER DEFAULT CHARSET=latin1 COMMENT='shard_key "id"'
/*!50100 PARTITION BY LIST (crc32(id)%2)
(PARTITION pt0 VALUES IN (0) COMMENT = 'database "d1", table " test_timestamp", server "SPT0"' ENGINE = SPIDER,
PARTITION pt1 VALUES IN (1) COMMENT = 'database "d1", table " test_timestamp", server "SPT1"' ENGINE = SPIDER) */
update test_timestamp set c1 = 1 where id = 1时,spider未转发时间戳,则更新后的update_time字段时间不正确。
现在的处理是,同时满足以下条件,会执行非direct_udpate:
a. 有set timestamp = xxxx操作
b. 表有timestamp列,并且on update CURRENT_TIMESTAMP
c. update语句没有指定timestamp列的值
即:update t1 set c1 = 2 where id = 1 (表t1有update列)会转化为select c1 from t1 where id = 1;
如果c1值无变化,则返回。否则,执行update t1 set c1 = 2, update_time='根据timestamp计算' where id = 1 limit 1;
另外replace into t1(id, c1) values(1,2),可以继续保持direct_dup_insert,因为timestamp值总是更新的。
7. 修复上述问题后,引发timestamp 类型的的SQL在非dierct_update可能出现部分列没取,导致更新失败的问题。
测例:
CREATE TABLE `t_account_loginstatus_0` (
`uuid` varchar(128) NOT NULL,
`openid` varchar(128) NOT NULL,
`context` tinyblob NOT NULL,
`updatetime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`createtime` int(11) unsigned DEFAULT '0',
KEY `uuid` (`uuid`),
KEY `uuid_2` (`uuid`,`openid`),
KEY `uuid_3` (`uuid`,`context`(32))
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='shard_key "uuid"'
/*!50100 PARTITION BY LIST (crc32(`uuid`)%2)
(PARTITION pt0 VALUES IN (0) COMMENT = 'database "d1", table " t_account_loginstatus_0",
server "SPT0"' ENGINE = SPIDER,
PARTITION pt1 VALUES IN (1) COMMENT = 'database "d1", table " t_account_loginstatus_0",
server "SPT1"' ENGINE = SPIDER) */;
insert into t_account_loginstatus_0 values('007b02fd-d068-4caf-81ef-2860f842b48e','79d7a7eb-b3bc-40e8-b208-68fbbc52285a', 'aaabbb', '2015-06-08 15:20:03',1403218866);
SET TIMESTAMP=1442820567;
update t_account_loginstatus_0 set openid='2e8d2577-624b-44e0-b7eb-14558fdfadfe', context='aaabbb' where
(uuid='007b02fd-d068-4caf-81ef-2860f842b48e' and openid='2e8d2577-624b-44e0-b7eb-14558fdfadfe') or
(uuid='007b02fd-d068-4caf-81ef-2860f842b48e' and context='aaabbb');
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

