Spark 内核研究
1、Spark介绍
Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目。随着Spark在大数据计算领域的暂露头角,越来越多的企业开始关注和使用。2014年11月,Spark在Daytona Gray Sort 100TB Benchmark竞赛中打破了由Hadoop MapReduce保持的排序记录。Spark利用1/10的节点数, 把100TB数据的排序时间从72分钟提高到了23分钟 。
Spark在架构上包括内核部分和4个官方子模块--Spark SQL、Spark Streaming、机器学习库MLlib和图计算库GraphX。图1所示为Spark在伯克利的数据分析软件栈 BDAS (Berkeley Data Analytics Stack)中的位置。可见Spark专注于数据的计算,而数据的存储在生产环境中往往还是由Hadoop分布式文件系统HDFS承担。

图1 Spark在BDAS中的位置
Spark被设计成支持多场景的通用大数据计算平台,它可以解决大数据计算中的批处理,交互查询及流式计算等核心问题。Spark可以从多数据源的读取数据,并且拥有不断发展的机器学习库和图计算库供开发者使用。数据和计算在Spark内核及Spark的子模块中是打通的,这就意味着Spark内核和子模块之间成为一个整体。Spark的各个子模块以Spark内核为基础,进一步支持更多的计算场景,例如使用Spark SQL读入的数据可以作为机器学习库MLlib的输入。表1列举了一些在Spark平台上的计算场景。

表1 Spark的应用场景举例
在本文写作是,Spark的最新版本为1.2.0,文中的示例代码也来自于这个版本。
2、Spark内核介绍
相信大数据工程师都非常了解Hadoop MapReduce一个最大的问题是在很多应用场景中速度非常慢,只适合离线的计算任务。这是由于MapReduce需要将任务划分成map和reduce两个阶段,map阶段产生的中间结果要写回磁盘,而在这两个阶段之间需要进行shuffle操作。Shuffle操作需要从网络中的各个节点进行数据拷贝,使其往往成为最为耗时的步骤,这也是Hadoop MapReduce慢的根本原因之一,大量的时间耗费在网络磁盘IO中而不是用于计算。在一些特定的计算场景中,例如像逻辑回归这样的迭代式的计算,MapReduce的弊端会显得更加明显。
那Spark是如果设计分布式计算的呢?首先我们需要理解Spark中最重要的概念--弹性分布数据集(Resilient Distributed Dataset),也就是RDD。
2.1 弹性分布数据集RDD
RDD是Spark中对数据和计算的抽象,是Spark中最核心的概念,它表示已被分片(partition),不可变的并能够被并行操作的数据集合。对RDD的操作分为两种transformation和action。Transformation操作是通过转换从一个或多个RDD生成新的RDD。Action操作是从RDD生成最后的计算结果。在Spark最新的版本中,提供丰富的transformation和action操作,比起MapReduce计算模型中仅有的两种操作,会大大简化程序开发的难度。
RDD的生成方式只有两种,一是从数据源读入,另一种就是从其它RDD通过transformation操作转换。一个典型的Spark程序就是通过Spark上下文环境(SparkContext)生成一个或多个RDD,在这些RDD上通过一系列的transformation操作生成最终的RDD,最后通过调用最终RDD的action方法输出结果。
每个RDD都可以用下面5个特性来表示,其中后两个为可选的:
- 分片列表(数据块列表)
- 计算每个分片的函数
- 对父RDD的依赖列表
- 对key-value类型的RDD的分片器(Partitioner)(可选)
- 每个数据分片的预定义地址列表(如HDFS上的数据块的地址)(可选)
虽然Spark是基于内存的计算,但RDD不光可以存储在内存中,根据useDisk、useMemory、useOffHeap, deserialized、replication五个参数的组合Spark提供了12种存储级别,在后面介绍RDD的容错机制时,我们会进一步理解。值得注意的是当StorageLevel设置成OFF_HEAP时,RDD实际被保存到 Tachyon 中。Tachyon是一个基于内存的分布式文件系统,目前正在快速发展,本文不做详细介绍,可以通过其官方网站进一步了解。
class StorageLevel private( private var _useDisk: Boolean, private var _useMemory: Boolean, private var _useOffHeap: Boolean, private var _deserialized: Boolean private var _replication: Int = 1) extends Externalizable { //… } val NONE = new StorageLevel(false, false, false, false) val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(false, false, true, false) 2.2 DAG、Stage与任务的生成
Spark的计算发生在RDD的action操作,而对action之前的所有transformation,Spark只是记录下RDD生成的轨迹,而不会触发真正的计算。
Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是DAG。举个例子,在图2中,从输入中逻辑上生成A和C两个RDD,经过一系列transformation操作,逻辑上生成了F,注意,我们说的是逻辑上,因为这时候计算没有发生,Spark内核做的事情只是记录了RDD的生成和依赖关系。当F要进行输出时,也就是F进行了action操作,Spark会根据RDD的依赖生成DAG,并从起点开始真正的计算。
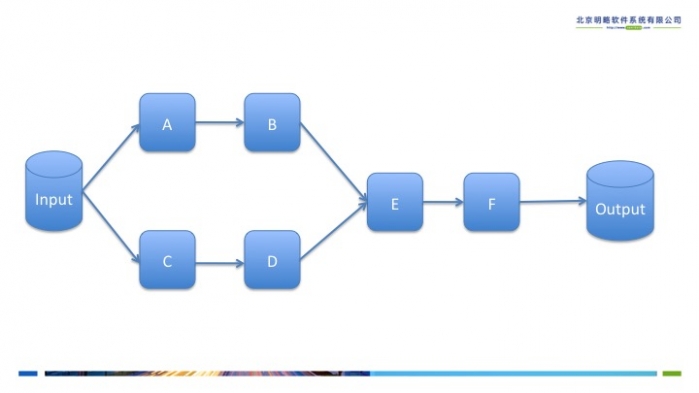
图2 逻辑上的计算过程:DAG
有了计算的DAG图,Spark内核下一步的任务就是根据DAG图将计算划分成任务集,也就是Stage,这样可以将任务提交到计算节点进行真正的计算。Spark计算的中间结果默认是保存在内存中的,Spark在划分Stage的时候会充分考虑在分布式计算中可流水线计算(pipeline)的部分来提高计算的效率,而在这个过程中,主要的根据就是RDD的依赖类型。根据不同的transformation操作,RDD的依赖可以分为窄依赖(Narrow Dependency)和宽依赖(Wide Dependency,在代码中为ShuffleDependency)两种类型。窄依赖指的是生成的RDD中每个partition只依赖于父RDD(s) 固定的partition。宽依赖指的是生成的RDD的每一个partition都依赖于父 RDD(s) 所有partition。窄依赖典型的操作有map, filter, union等,宽依赖典型的操作有groupByKey, sortByKey等。可以看到,宽依赖往往意味着shuffle操作,这也是Spark划分stage的主要边界。对于窄依赖,Spark会将其尽量划分在同一个stage中,因为它们可以进行流水线计算。
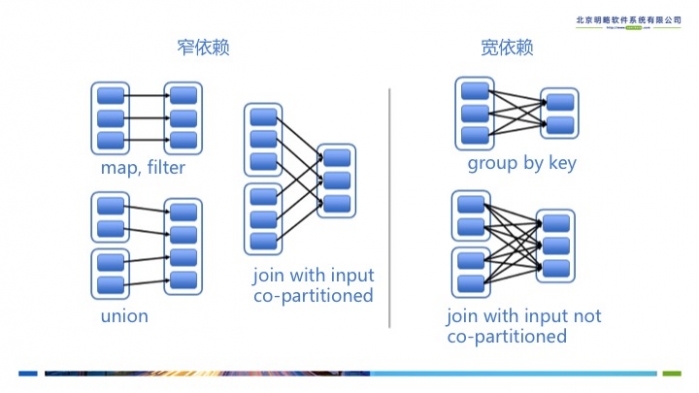
图3 RDD的宽依赖和窄依赖
我们再通过图4详细解释一下Spark中的Stage划分。我们从HDFS中读入数据生成3个不同的RDD,通过一系列transformation操作后再将计算结果保存回HDFS。可以看到这幅DAG中只有join操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage. 同时我们可以注意到,在图中Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,通过map操作生成的partition可以不用等待整个RDD计算结束,而是继续进行union操作,这样大大提高了计算的效率。

图4 Spark中的Stage划分
Spark在运行时会把Stage包装成任务提交,有父Stage的Spark会先提交父Stage。弄清楚了Spark划分计算的原理,我们再结合源码看一看这其中的过程。下面的代码是DAGScheduler中的得到一个RDD父Stage的函数,可以看到宽依赖为划分Stage的边界。
/** * Get or create the list of parent stages for a given RDD. The stages will be assigned the * provided jobId if they haven't already been created with a lower jobId. */ private def getParentStages(rdd: RDD[_], jobId: Int): List[Stage] = { val parents = new HashSet[Stage] val visited = new HashSet[RDD[_]] // We are manually maintaining a stack here to prevent StackOverflowError // caused by recursively visiting val waitingForVisit = new Stack[RDD[_]] def visit(r: RDD[_]) { if (!visited(r)) { visited += r // Kind of ugly: need to register RDDs with the cache here since // we can't do it in its constructor because # of partitions is unknown for (dep <- r.dependencies) { dep match { case shufDep: ShuffleDependency[_, _, _] => parents += getShuffleMapStage(shufDep, jobId) case _ => waitingForVisit.push(dep.rdd) } } } } waitingForVisit.push(rdd) while (!waitingForVisit.isEmpty) { visit(waitingForVisit.pop()) } parents.toList } 上面提到Spark的计算是从RDD调用action操作时候触发的,我们来看一个action的代码
RDD的collect方法是一个action操作,作用是将RDD中的数据返回到一个数组中。可以看到,在此action中,会触发Spark上下文环境SparkContext中的runJob方法,这是一系列计算的起点。
abstract class RDD[T: ClassTag]( @transient private var sc: SparkContext, @transient private var deps: Seq[Dependency[_]] ) extends Serializable with Logging { //…. /** * Return an array that contains all of the elements in this RDD. */ def collect(): Array[T] = { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) } } SparkContext拥有DAGScheduler的实例,在runJob方法中会进一步调用DAGScheduler的runJob方法。在此时,DAGScheduler会生成DAG和Stage,将Stage提交给TaskScheduler。TaskSchduler将Stage包装成TaskSet,发送到Worker节点进行真正的计算,同时还要监测任务状态,重试失败和长时间无返回的任务。整个过程如图5所示。

图5 Spark中任务的生成
2.3 RDD的缓存与容错
上文提到,Spark的计算是从action开始触发的,如果在action操作之前逻辑上很多transformation操作,一旦中间发生计算失败,Spark会重新提交任务,这在很多场景中代价过大。还有一些场景,如有些迭代算法,计算的中间结果会被重复使用,重复计算同样增加计算时间和造成资源浪费。因此,在提高计算效率和更好支持容错,Spark提供了基于RDDcache机制和checkpoint机制。
我们可以通过RDD的toDebugString来查看其递归的依赖信息,图6展示了在spark shell中通过调用这个函数来查看wordCount RDD的依赖关系,也就是它的Lineage.
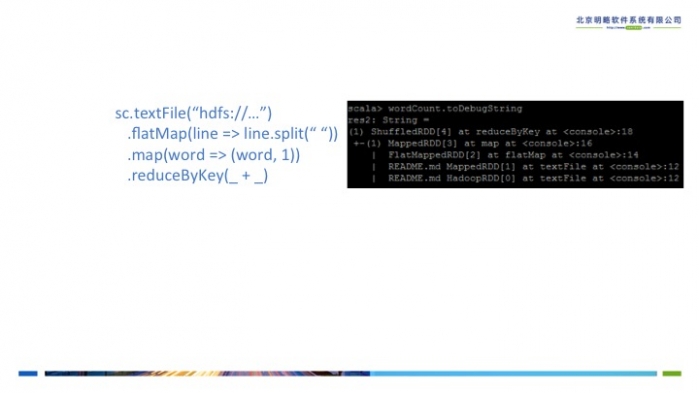
图6 RDD wordCount的lineage
如果发现Lineage过长或者里面有被多次重复使用的RDD,我们就可以考虑使用cache机制或checkpoint机制了。
我们可以通过在程序中直接调用RDD的cache方法将其保存在内存中,这样这个RDD就可以被多个任务共享,避免重复计算。另外,RDD还提供了更为灵活的persist方法,可以指定存储级别。从源码中可以看到RDD.cache就是简单的调用了RDD.persist(StorageLevel.MEMORY_ONLY)。
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) def cache(): this.type = persist()
同样,我们可以调用RDD的checkpoint方法将其保存到磁盘。我们需要在SparkContext中设置checkpoint的目录,否则调用会抛出异常。值得注意的是,在调用checkpoint之前建议先调用cache方法将RDD放入内存,否则将RDD保存到文件的时候需要重新计算。
/** * Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint * directory set with SparkContext.setCheckpointDir() and all references to its parent * RDDs will be removed. This function must be called before any job has been * executed on this RDD. It is strongly recommended that this RDD is persisted in * memory, otherwise saving it on a file will require recomputation. */ def checkpoint() { if (context.checkpointDir.isEmpty) { throw new SparkException("Checkpoint directory has not been set in the SparkContext") } else if (checkpointData.isEmpty) { checkpointData = Some(new RDDCheckpointData(this)) checkpointData.get.markForCheckpoint() } } Cache机制和checkpoint机制的差别在于cache将RDD保存到内存,并保留Lineage,如果缓存失效RDD还可以通过Lineage重建。而checkpoint将RDD落地到磁盘并切断Lineage,由文件系统保证其重建。
2.4 Spark任务的部署
Spark的集群部署分为Standalone、Mesos和Yarn三种模式,我们以Standalone模式为例,简单介绍Spark程序的部署。如图7示,集群中的Spark程序运行时分为3种角色,driver, master和worker(slave)。在集群启动前,首先要配置master和worker节点。启动集群后,worker节点会向master节点注册自己,master节点会维护worker节点的心跳。Spark程序都需要先创建Spark上下文环境,也就是SparkContext。创建SparkContext的进程就成为了driver角色,上一节提到的DAGScheduler和TaskScheduler都在driver中运行。Spark程序在提交时要指定master的地址,这样可以在程序启动时向master申请worker的计算资源。Driver,master和worker之间的通信由 Akka 支持。Akka 也使用 Scala 编写,用于构建可容错的、高可伸缩性的Actor 模型应用。关于Akka,可以访问其官方网站进行进一步了解,本文不做详细介绍。

图7 Spark任务部署
3、更深一步了解Spark内核
了解了Spark内核的基本概念和实现后,更深一步理解其工作原理的最好方法就是阅读源码。最新的Spark源码可以从 Spark官方网站下载 。源码推荐使用IntelliJ IDEA阅读,会自动安装Scala插件。读者可以从core工程,也就是Spark内核工程开始阅读,更可以设置断点尝试跟踪一个任务的执行。另外,读者还可以通过分析Spark的日志来进一步理解Spark的运行机制,Spark使用log4j记录日志,可以在启动集群前修改log4j的配置文件来配置日志输出和格式。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

