关于高性能Web服务的一点思考
下面这些概念对于专业做性能测试的会比较熟悉,但是对于开发人员不一定都那么清楚。
- 并发用户数: 某一时刻同时请求服务器的用户总数,通常我们也称并发数,并发连接数等。
- 吞吐率:对于web服务器来说就是每秒处理的请求数,req/sec.
- 服务器平均请求处理时间:服务内部的处理时间,可以理解为我们平时log里的时间。
- 用户平均请求延迟时间:用户发送一个请求到接收到响应的时间间隔。
并发用户数和吞吐率容易被人混淆,除非服务器刚好1秒内能处理完并发用户的请求,否则两者数值上没有必然联系。一般的服务器都有并发的限制,比如MongoDB的maxConns,Tomcat的maxThreads。
吞吐率和服务器的请求处理时间则互为倒数,其实都是用来衡量服务器内部质量的,而用户平均请求延迟时间则是在一定并发下用来衡量对单个用户的服务质量。
一般的随着并发越来越大,吞吐率是先升后降,因为平均服务器处理时间是吞吐率的倒数,所以它是先降后升,存在一个平衡点,往往超过这个点,吞吐率明显下降,服务器平均处理时间也会明显变大。这个平衡点就是我们做压力测试要寻找的,叫做服务器的最大吞吐率,有时候我们习惯了干脆直接叫做吞吐率了,这时的并发可以叫做最大并发数或者叫最佳并发数。很多人习惯说:某某服务支持多大多大并发,我理解应该就是指的这个数。
而用户平均请求延迟时间则会随着并发数的增加而变大,一般在达到服务器的最大并发数之前增加的会比较缓慢,超过之后会骤增。如果一直只有一个用户请求,那么用户平均请求延迟时间自然等于服务器平均请求处理时间(忽略网络耗时),但随着并发用户的增加,无论服务器的并发策略如何,用户的等待时间都会变长,因为假设理想情况,服务器资源无限,所有的请求都是并行处理也仅仅是“等于”,但现实是上下文切换,请求排队等等的代价不可忽略,所以具体到某个用户的等待时间就会变长。而服务器平均请求处理时间,随着资源的充分利用一开始反而可能会下降。
综上所述,如果用户平均请求延迟时间 » 服务器平均处理时间,忽略网络耗时的话,可以说服务器已经存在瓶颈了,说明实际大并发数已经超过服务器的最大并发处理能力了。
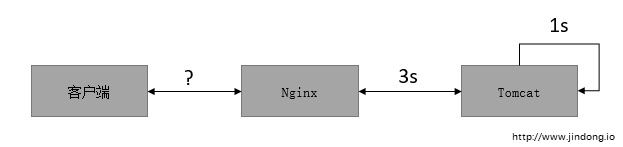
我们的生产环境现在就面临这样的问题,每天的峰值期间从前面Nginx看平均的响应时间已经达到了3s,但是Tomcat内部的处理时间其实并不到1s,剩下的时间耗在了哪?线程切换,请求排队…
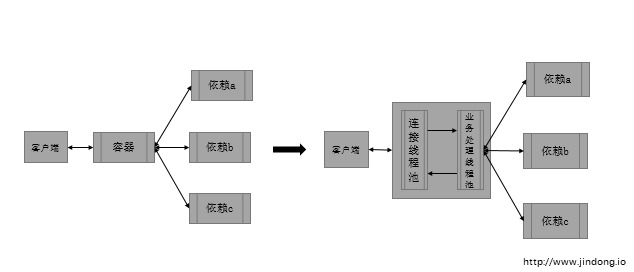
那么如何在不加机器的情况下优化这个问题呢?既然瓶颈是服务器并发,那么就得想办法提高并发能力。具体到Tomcat可能是一些参数调优之内的,比如NIO,APR,但这些都做过了之后还有没有优化的空间呢。最近我准备验证下Servlet3.0的异步和Jetty的Continuation,总体的思路就是将容器线程和业务线程分开,减小并发的粒度来提高并发。但具体有没有效果很难说,只有测了才知道,想要并发越高,逻辑就得拆的越细,代价就越高。
最后,实际情况要复杂的多,考虑网络因素,用户实际的平均请求延迟时间会更大,而且通常我们缺少这样的数据参考,所以现在很多都在做端到端的监控。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

