【R】有助于提高数据处理效率的7个包
引言
数据处理是建立预测模型时不可避免的一步。一个稳健的预测模型不是仅仅依靠机器学习算法就可以建立的,相反,它还需要依靠一定的方法,这些方法帮助人们理解商业问题,了解潜在数据集,进行必要的数据处理工作并提取出有用的商业信息。
在这些建模阶段里,大多数时间通常都被花在了解潜在数据集和进行必要数据处理上。这也是这篇文章的焦点——谈一谈R中可提高数据处理效率的包。
什么是数据处理?
如果你不清楚这个术语的含义,让我来给你解释一下它。数据处理是和数据探索一起使用的一个没有严格定义的术语。它包括用可获得的变量集“操纵”数据,以提高数据的准确性和精度。
事实上,数据收集的过程会有很多的漏洞。有各种各样不可控的因素会导致数据不精确,比如被调查者的精神状况,个人偏见,数据的读数差异或错误等。为了降低不精确程度,我们运用数据处理来(最大)可能性的增加数据精度。
这一阶段有时也被称为数据整理或数据清洗。
处理数据的不同方式
数据处理方式没有对错之分,只要你能理解数据并采取正确的方法处理数据。但通常人们在尝试进行数据处理时一般会用到以下几个宽泛的方法:
- 通常来说,R的初学者觉得用R内置的基础函数处理数据就很舒服。这个作为第一步很好,但是通常重复度高且耗时,因此是一个相对低效的解决问题方法。
- 使用专门的数据处理包。如今CRAN有超过7000个可供使用的包,这些包不过是一些事先写好的常用代码集合。他们可以帮你更快地完成重复性工作,减少编程差错并从专业人士写的代码中得到帮助(通过R的开源系统),使你的代码运行起来更加高效。这通常是数据处理中最常用的方法。
- 使用机器学习算法进行数据处理工作。你可以使用基于树的改进算法来处理缺失值和异常值。尽管这个方法无疑更省时,但通常它们会让你觉得对数据的理解不够,并想要找到更好的方法来认识数据。
因此,通常情况下,事实上都是使用包来进行数据处理。在这篇文章中,我将介绍几个使得R的数据处理更方便的包。
这篇文章最适宜于R语言的初学者。你可以这样安装一个包:

软件包的清单
为了理解更清楚,我会通过一些常见的指令来示范如何使用它们。下面是这篇文章要讨论的几个R包:
- dplyr
- data.table
- ggplot2
- reshape2
- readr
- tidyr
- lubridate
注:我知道ggplot2是一个用来画图的包,但是,它通常会帮助人们进行数据可视化并相应地进行处理数据工作。因此我把它加进了这个单子里。对所有包,我只写了有关数据处理的常用命令。
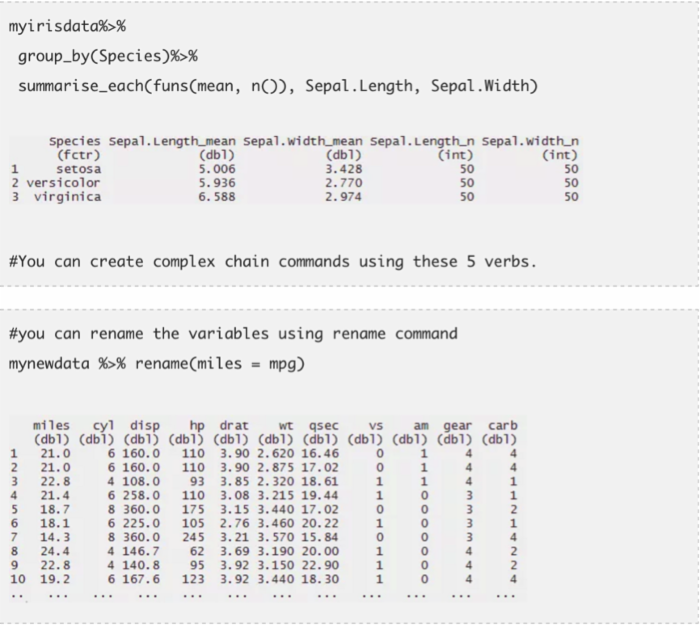
dplyr包
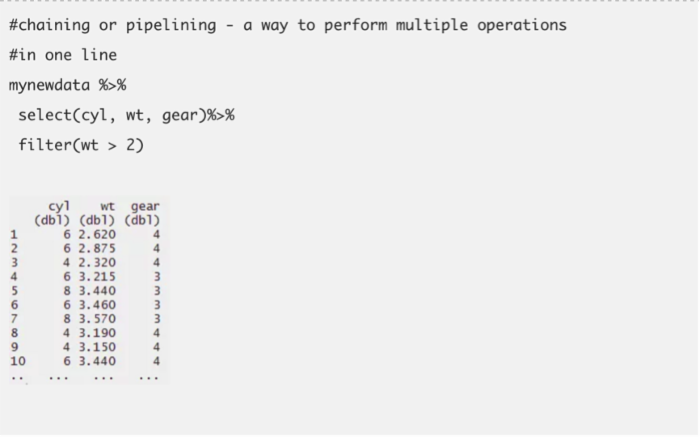
这个包是Hadley Wickham创建和维护的。它包括了(几乎)全部可以用来加快数据处理进程的内容。它最有名的是数据探索和数据转换功能。它的链式语法让它使用起来很方便。它包括5个主要的数据处理指令:
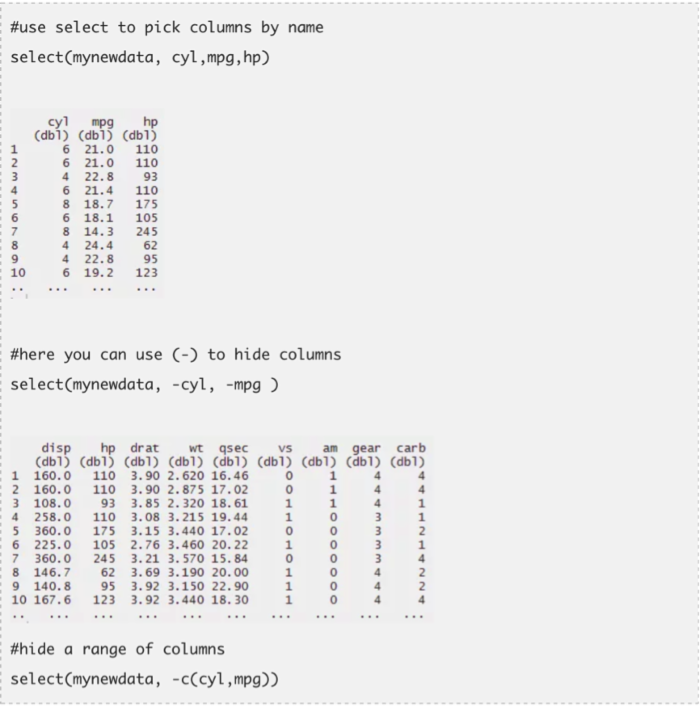
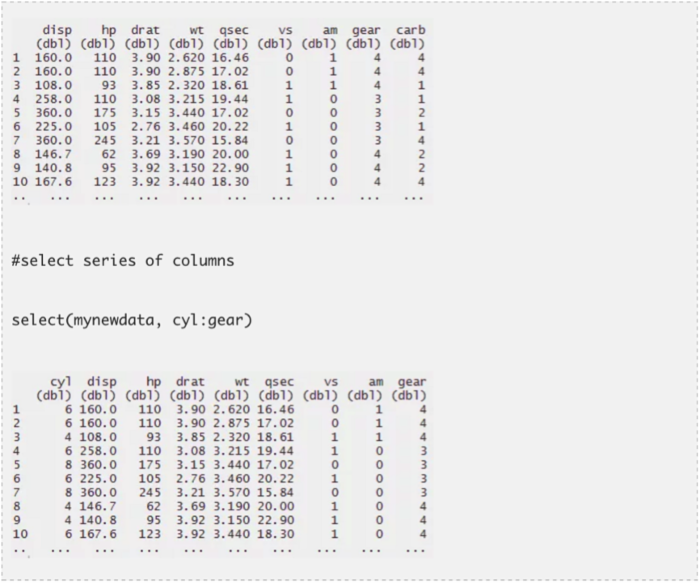
- 过滤——集于某一条件过滤数据
- 选择——选出数据集中感兴趣的列
- 排列——升序或降序排列数据集中的某一个值域
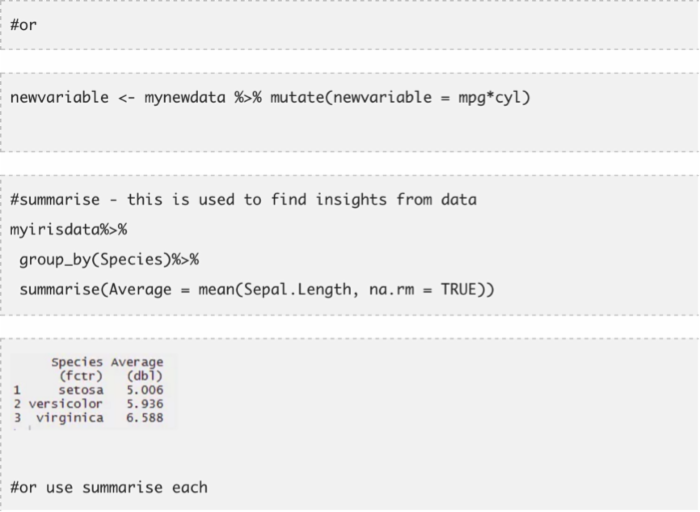
- 变换——从已有变量生成新的变量
- 概括(通过group_by)——提供常用的操作分析,如最小值、最大值、均值等
只需要关注这些指令便可以完成很好的数据探索工作。让我们一起逐一了解一下这些指令。我用到了两个R中内置的数据集mtcars和iris.






data.table包
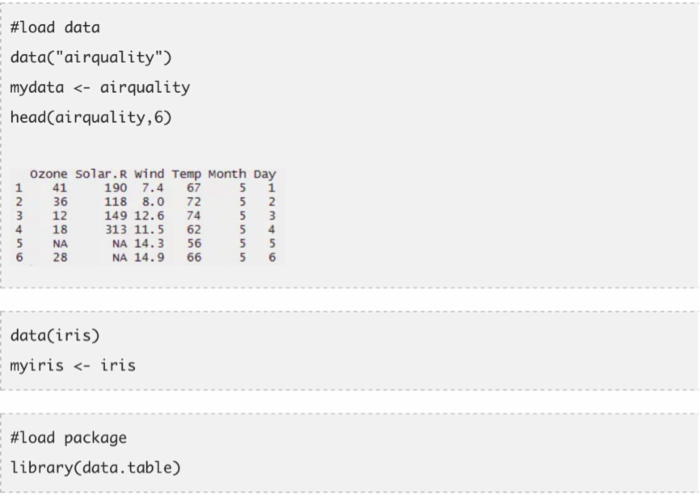
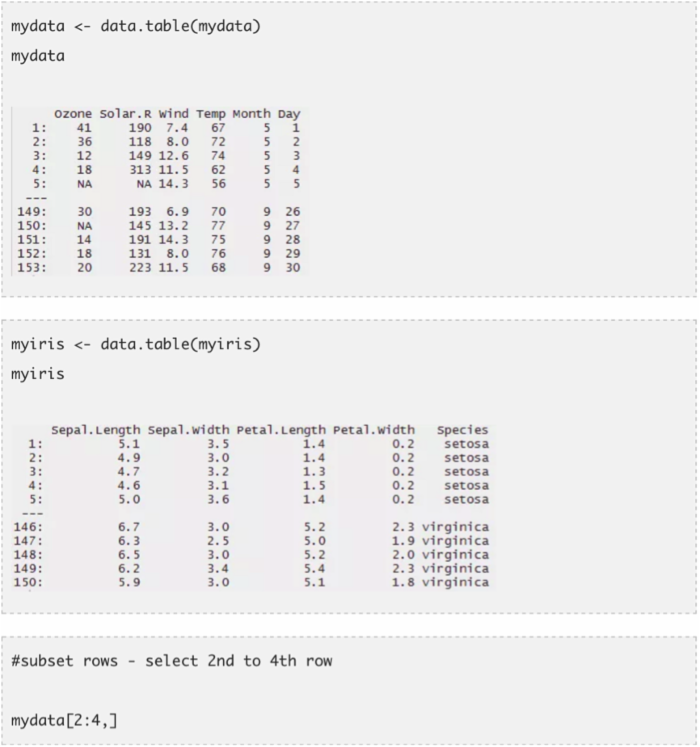
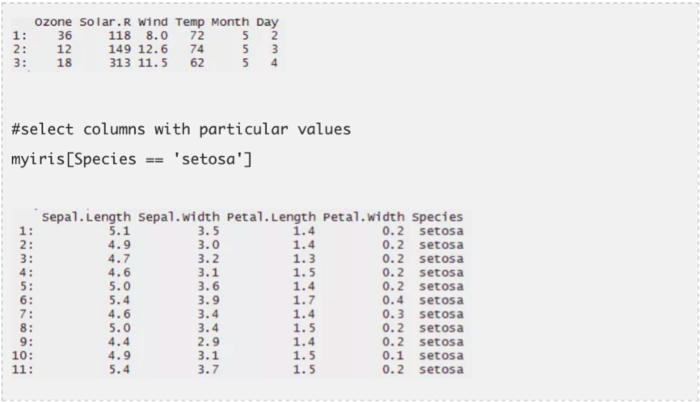
这个包让你可以更快地完成数据集的数据处理工作。放弃选取行或列子集的传统方法,用这个包进行数据处理。用最少的代码,你可以做最多的事。相比使用data.frame,data.table可以帮助你减少运算时间。你一定会对这个包的简洁性感到震惊。
一个数据表格包含三部分,即DT[i, j, by]。你可以理解为我们告诉R用i来选出行的子集,并计算通过by来分组的j。大多数时候,by是用于类别变量的。在下面的代码中,我用了两个数据集(airquality和iris)。



ggplot2包
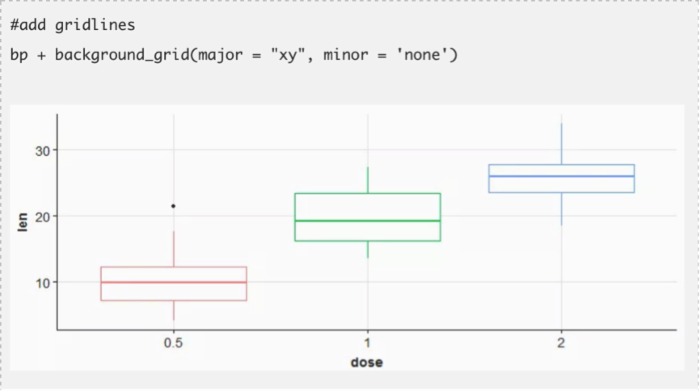
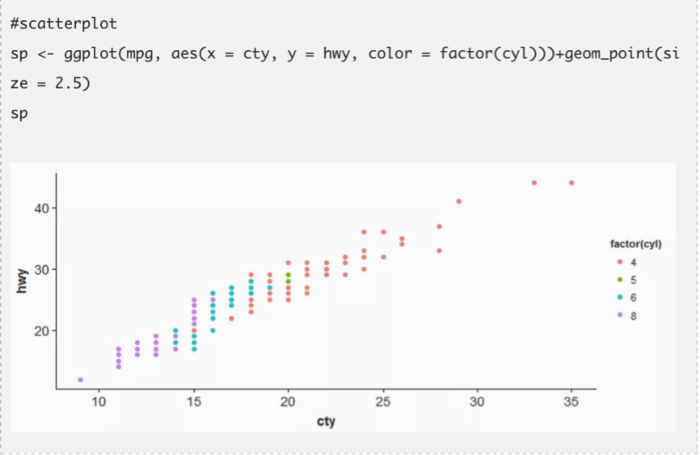
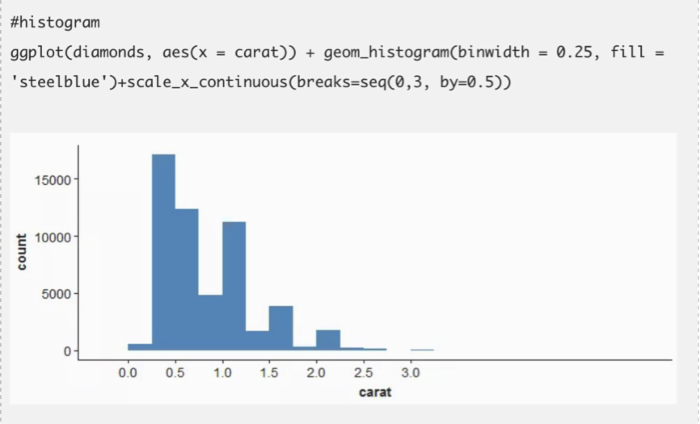
ggplot包展示了一个全新的色彩与图案世界。如果你是一个富有创意的人,你会非常喜欢这个包。但是如果你是想了解如何开始使用这个包,请依据下面的代码。你至少需要学会画这三个图的方法:散点图,条形图和直方图。
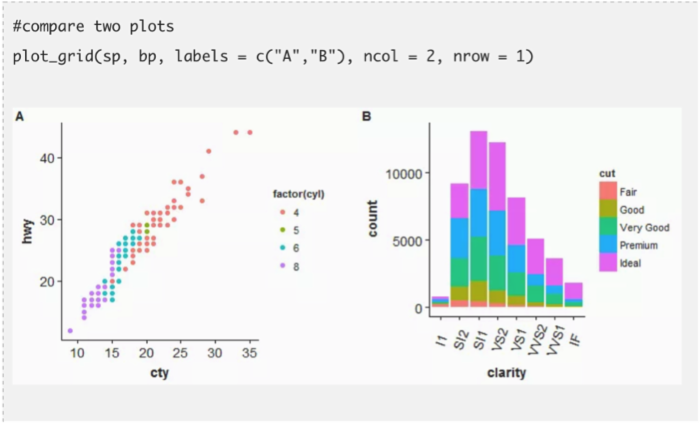
这三个图表涵盖了除了地图外几乎所有的数据展示类别。ggplot有丰富的自定义特征使你的数据可视化变得更好。当和其他诸如cowplot,gridExtra包一起使用时,它会变得更强大。事实上,它有很多特色指令。因此,你必须专注于几个指令并且做到精通。在下面的代码中我也展示了在同一个窗口中比较不同图表的方法。它需要gridExtra包来配合,所以你要先安装这个包。我用了R内置的数据集。



reshape2包
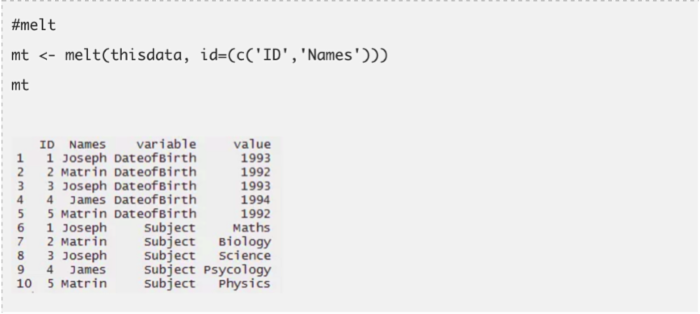
正如这个包的名字所表示的含义,这个包对于重塑数据格式很有用。我们都知道数据会有很多不同的表现格式。因此,我们需要根据需要“驯服”它们以为己用。通常,在R中重塑数据格式非常无聊和麻烦。R基础函数中有一个Aggregation函数,用来缩减并重新排列数据为更短小的格式,但是会大大减少数据包含的信息量。Aggregation包括tapply,by和aggregate基础函数。reshape包会克服这些问题。在这里我们试着把有一样值的特征合并在一起。它有两个函数,即melt和cast。
melt: 这个函数把数据从宽格式转化为长格式。这是一种把多个类别列“融合”为一行的结构重组。我们来通过代码理解它是怎么运行的。

Cast: 这个函数把数据从长格式转换为宽格式。它始于融合后的数据,然后把数据重新构造为长格式。它就是melt函数的反向操作。它包括两个函数,即,dcast和acast。dcast返回数据框作为输出结果。acast返回向量/矩阵/数组作为输出结果。让我们通过下面的代码来看看怎么用它们。

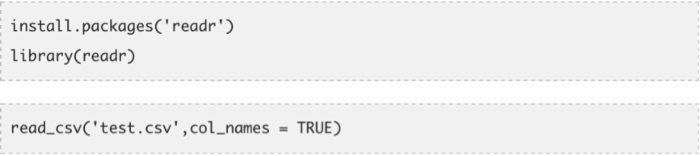
readr包
正如这个包的名字所暗示的,readr用来把不同格式的数据读入R中,通过比传统方法快十倍的速度。在此,字符型变量不会被转化为因子型变量(所以不再有stringAsFactors = FALSE命令)。这个包可以代替传统的R基础函数read.csv()和read.table()。它可以用来读入以下格式的数据:
- 分隔符文件:read_delim(),read_csv(),read_tsv()和read_csv2()
- 固定宽度文件:read_fwf()和read_table()
- 网络日志文件:read_log()
如果数据载入时间超过5秒,函数还会显示进度条。你可以通过命令它为FALSE来禁止进度条出现。我们来一起看一下下面的代码。
你也可以利用以下的代码定义数据集中每列变量的格式:

然而,如果我们忽视不重要的变量,那么该函数会自动定义这些变量的格式。所以上述代码也可以写成以下形式:

备注:readr包中含有很多有用的函数。所以你可以考虑利用write_csv函数来导出数据,这个函数的运算效率高于write.csv函数。
tidyr包
这个包可以让你的数据看上去“整洁”。它主要用四个函数来完成这个任务。毋庸赘言,当你发现自己在数据探索阶段卡壳的时候,你可以(和dplyr包一起)随时使用这些函数。这两个包形成了一个实力强大的组合。它们很好学,代码容易些,应用便捷。这四个函数是:
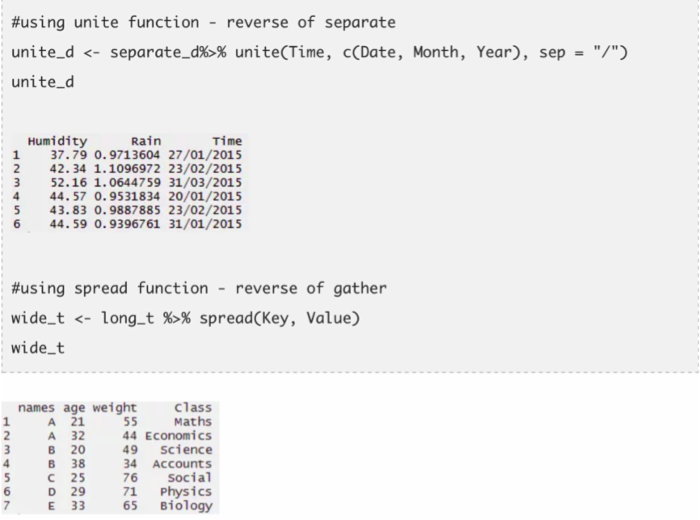
- gather()——它把多列放在一起,然后转化为key:value对。这个函数会把宽格式的数据转化为长格式。它是reshape包中melt函数的一个替代。
- spread()——它的功能和gather相反,把key:value对转化成不同的列。
- separate()——它会把一列拆分为多列
- unite()——它的功能和separate相反,把多列合并为一列
我们一起来通过下面的代码更仔细地了解如何使用他们:

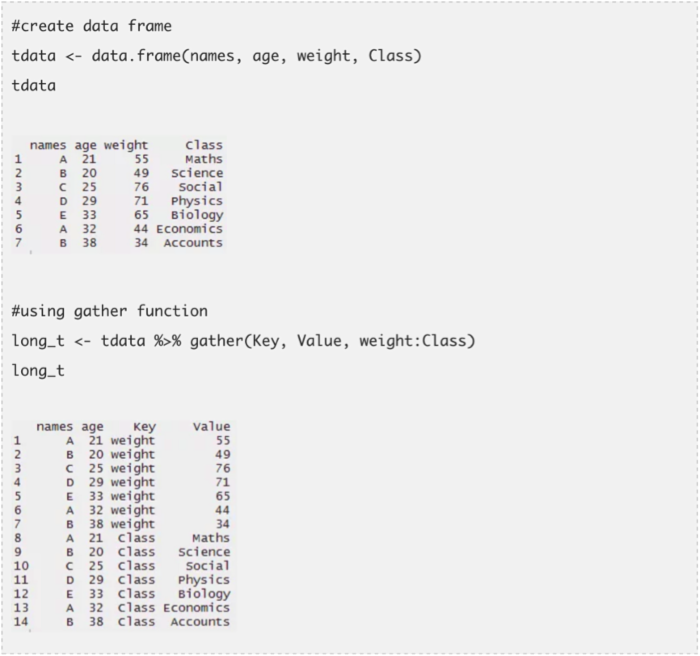
函数separate最适用于有时间变量的数据集。由于列中包含了很多信息,因此把它们拆分开来并分别使用它们很有必要。使用以下的代码,我把一个列拆分成了日期,月份和年。
lubridate包
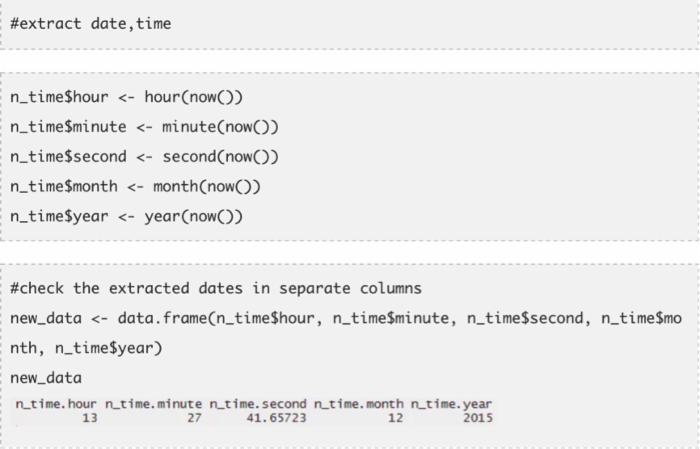
Lubridate包可以减少在R中操作时间变量的痛苦。此包的内置函数提供了很好的解析日期与时间的便利方法。这个包常用于包含时间数据的数据集。在此我展示了Lubridate包中的三个函数。
这三个函数是update,duration和date extraction。作为一个初学者,了解这三个函数足以让你成为处理时间变量的专家。尽管R有内置函数来处理日期,这个包的处理方法会更快。让我们一起来通过以下代码了解这些函数是如何运用的:

注:这些包最佳的使用方法不是分开单独使用,而是把它们用在一起。你可以很容易地同dplyr一起使用这个包,在dplyr中你可以比较方便地选择一个数据变量并通过链式命令提取出有用的数据。
结语:
这些包不仅能帮助你提升数据处理水平,还能助你更深入地探索R。现在我们已经看到了,这些包让在R中写代码变得更容易。你不再需要写长串的代码,相反,代码变得更短,可以处理的任务变得更多。
每个包都有多线处理任务的功能。因此,我建议你们掌握那些常用的重要函数。同时,当你熟悉了如何使用它们时,你就能进行更深入地挖掘和探索。我开始也犯了这个错误,我试着研究ggplot2中所有的特征函数,结果最后一头雾水。我建议你们在阅读文章的同时能试着练习写这些代码。这会有助于你更自信地使用这些包。
在这篇文章中,我介绍了可以让数据探索变得更方便快捷的7个包的使用方法。R因其令人赞叹的统计功能而闻名于世,同时,时时更新的包也让它成为数据科学家最爱使用的工具。
原文链接:
http://www.analyticsvidhya.com/blog/2015/12/faster-data-manipulation-7-packages/
原文作者:Manish Saraswat
翻译:Fibears
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

