【BDTC 2015】数据库分论坛:GBase 8t、PosgreSQL-X2及Greenplum核心技术解析
2015年12月10-12日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所、北京中科天玑科技有限公司与CSDN共同协办,以“数据安全、深度分析、行业应用”为主题的 2015中国大数据技术大会 (Big Data Technology Conference 2015,BDTC 2015)在北京新云南皇冠假日酒店盛大开幕。
2015中国大数据技术大会第二天的数据库分论坛分论坛中,来自南大通用、西北工业大学、中国移动苏州研发中心、 华东师范大学、Pivotal的专家与教授分享了大数据时代下数据管理技术、事务处理等方面的经验。本次论坛由华东师范大学数据科学与工程研究院院长周傲英主持。

华东师范大学数据科学与工程研究院院长 周傲英
天津南大通用高级副总裁兼CTO武新:GBase 8t 高端OLTP数据库核心技术剖析
数据库产业至今已有30年的辉煌,形成了Oracle、SQL Server、Sybase ASE 、Informax(IBM)、DB2五大金刚并立,Oracle一家独大的局面。主流数据库应具备主机高可用机制、容灾机制、并发支持机制、高端SMP支持核心能力。国产OLTP数据库在核心技术、架构、成熟度等方面均存在差距。
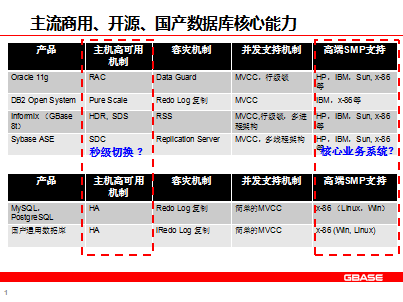
GBase 8t是由Informix发展而来,其基于IBM Informix 12.10最新源代码构建而成,是一个高性能事务型数据库,可用于金融、电信、安全、党政、国防、零售等行业的核心业务系统。
武新重点介绍了GBase 8t整体架构:共享内存+进程+VP,核心在于共享内存。其与Oracle相比创新点在于VP。他从以下五点进行了详解:
1.DSA的工作原理,包括VC(虚拟CPU)单个进程之内的多线程和不依赖系统线程库。进而可以支持大量的进程链接,且系统内存消耗很低。
2.Shared Memory共享内存架构,用户链接产生错误,不会影响其他用户链接,该架构同样支持swap扩展。
3.组件架构、开放、融合、灵活,GBase 8t 以数据库扩展方式提供对多种数据格式的存储支持,包括时间序列数据、OLAP列存、JSON文档、MQ消息。
4.GBase 8t采用了SDS共享存储集群、连接管理器CM、HDR高性能数据实时复制、GBase 8t 两地三中心等方案。
5.GBase 8t通过采用高性能、稳定的OLTP引擎、时间序列Engine和物联网解决方案、基于内存的数据分析加速器等方案使其具有卓越的跨平台能力。
武新表示,GBase 8t的用户核心价值在于最低的TCO。用户可远程部署应用程序,如零售商店、区域中心等等 ;在数据库被部署的地方不需要数据库管理员(远程部署);一个数据库管理员可以管理几千个站点的POS终端、ATM机。用户无需手动管理,应用程序控制数据库,自动管理,从而节约成本。GBase 8t使用更少的资源做更多的事情: 小的存储空间,高效的处理能力。

天津南大通用高级副总裁兼CTO 武新
演讲最后,武新谈到在大数据时代,GBase 8t带动了国产生态系统发展,采用混搭、融合架构,在政府和用户的支持下,国产数据库无法支撑核心业务系统的时代终结了,无论是在数据分析领域还是在联机交易系统领域,国内用户从此有了国产的高端数据库产品选择。他同时透漏在明年推出面向企业用户的GBase UP (Unified Platform)大数据平台产品,可以大大降低企业用户使用大数据的技术门槛。
西北工业大学软件技术研究所所长李战怀 :新型存储架构下数据管理技术面临的机遇与挑战
西北工业大学软件研究所所长李战怀演讲题目“新型存储架构下数据管理技术面临的机遇与挑战”。计算机系统性能依赖于处理器的数据计算能力和存储层次向处理器传输数据的能力。 数据管理系统在应对不同数据应用和环境的发展过程中,始终追求更快的数据处理能力。面向数据管理系统的最高效优化技术是软件与硬件的高效配合。多核/众核、GPU、FPGA、新型存储等硬件技术的发展给数据管理技术的发展带来机遇和挑战。他表示存储介质的更新和相关存储技术的发展一直是推动数据管理技术变革和发展的主要驱动力;存储器与处理器发展速度的差异导致两者长久以来都存在难以跨越的性能鸿沟,也使得“数据I/O瓶颈”始终是数据管理系统发展需要解决的重要问题。

西北工业大学软件技术研究所所长 李战怀
紧接着,李战怀介绍了NVM/SCM的非易失(断电情况下可保存信息)、高速随机访问(接近DRAM)、价格低廉、容量大(接近HDD)、低能耗、无噪音、面向字节寻址(Byte Addressability)等主要技术特征。 NVM技术涵盖广泛:从底层介质、控制器及算法、到体系结构以及上层软件栈等贯穿计算机的全系技术。他表示,NVM融入当今存储子系统两种方案:一、直接替换DRAM,由NVM作为内存。该方案简单,上层应用可以在不感知的情况下,无需修改直接运行。但目前存在性能低下、功耗增加等缺陷;二、NVM与DRAM混合,其涉及技术包括数据划分与分布技术、可靠性控制技术等,并且混合式介质融合是未来的发展趋势。

数据库都是架构在目标存储层级(storage hierarchy)上的,数据库架构分为Disk-oriented 、Memory-oriented、NVM-oriented三种。Disk-oriented:普遍采用如Buffer pool或者复杂的并发控制,缓解disk导致的IO延迟;Memory-oriented:消减数据驻留磁盘的高昂代价,从存储层次中数据使用的需求(冷热程度)出发改善存储;NVM-oriented:该架构与传统的two-tier相似,只是利用NVM替换了HDD。
演讲最后,李战怀谈到了目前NVM研究状况,面向NVM环境的上层数据管理技术存在困难,NVM尚未有可用的工业级产品,同时,面向NVM的软件的系统级的评测也是一个难题。李战怀希望在未来做数据库管理时,一定要密切关注硬件的发展,新硬件的特点将会促进架构的重新设计。
中国移动苏州研发中心大数据产品开发部高级工程师薛港:PosgreSQL-X2 的开发和应用
中国移动苏州研发中心大数据产品开发部高级工程师薛港带来的分享是:“PosgreSQL-X2 的开发和应用”。在大数据时代下,数据爆发式增长,分布式数据库种种优点使其独占鳌头。Postgres-X2是一款分布式关系数据库。即具有关系数据库的特性,同时又具备可扩展、高可用的特性,主要应用于海量数据的实时在线交易处理系统。

Postgres-X2的架构的核心组件分别是:用于全局事务控制GTM,在一个CLUSTER中只能有一台主的GTM; 为降低GTM压力的GTM_Proxy,用于对coordinator节点提交的任务进行分组等操作。机器中可以存在多个GTM_Proxy;数据节点与应用之间的接口--协调节点(Coordinator),协调节点是数据节点与应用之间的接口,协调节点并不物理上存储表数据。当应用发起SQL时,会先到达协调节点,然后协调节点将 SQL分发到各个数据节点,汇总数据;物理上存储表数据的数据节点(Datanode),数据节点物理上存储表数据,表数据存储方式分为分片和完全复制两种。
Datanode HA方案中:错位配置用于奇数机器;交叉配置用于偶数机器。然后薛港介绍了Postgres-X2备份和恢复方案:GTM备份和恢复,备份gtm.control ;Datanodte备份和恢复,和单机一样,基础备份加WAL日志;Coordinator备份和恢复,只备份元数据;利用create barrier‘name’保证整个Cluster恢复到一致点。Postgres-x2数据分片方案中,分片表适用于数据量很大的表;复制表适用于适用于数据量小、并且频繁需要参与join的静态表或者更新缓慢的码表。薛港介绍了Postgres-X2踩的一些坑,如数据结点的主备存在数据不一致;整个Cluster没办法根据XID恢复到一个一致点,只能恢复到BARRIER点;不支持二进制传输等。

中国移动苏州研发中心大数据产品开发部高级工程师 薛港
演讲最后他谈到了Postgres-X2的下一步开发计划,包括数据的多副本和自定义分片规则,前者无需配置Slave节点,所有数据天然多副本;后者能够提供更灵活的分片规则,尽可能的实现数据均匀分布。尽管相信分布式数据库是未来的发展方向,分布式数据库不是万能的它有自已适合的场景,Postgres-X2开发团队努力的目标,就是让它适合更多的场景。针对OLTP的分布式数据库目前不是太成熟,应从从简单场景、小应用着手,慢慢进行完善。
华师范大学数据科学与工程研究院教授钱卫宁 :可扩展事务处理系统:研究问题与进展
华东师范大学数据科学与工程研究院教授钱卫宁汇报的主题是“可扩展事务处理系统”。他介绍到:最初的数据库是用于订票和记账。事务处理包括并发控制和数据库恢复两个问题。其中并发控制减少了事务串行执行代价过高的弊端、但引入了事务之间的操作冲突。数据库恢复用于处理由于硬件、软件、网络等问题对数据库造成的可逆伤害。
钱卫宁首先介绍了事务处理的四大要素:原子性、一致性、隔离性、持久性。接下来,他重点介绍可互联网环境下事务处理需求,一些“现象级”应用产生使得传统的事务处理系统展露弊端,例如双十一大量订单产生的海量数据;同时,现象级不在“现象”,每天出现的秒杀、抢票等活动对后台交易支付系统产生巨大的压力。

由此引出了可扩展数据管理系统架构,该架构采用Master-slave结构,提供分冶策略,提高了并行性、可靠性(主备)、可用性(热备),实现读写分离和队列系统。可利用新型存储设备、高速网络、大容量内存和非易失快速存储介质等方面的优势将可扩展数据管理系统架构应用到事务处理。同样也面临着高可用 、容错、一致性这三者不能兼得的CAP定理,但是并不是不可逾越的障碍。

华师范大学数据科学与工程研究院教授 钱卫宁
钱卫宁提到不同应用的数据、负载、性能指标各不相同,针对不同的问题应分别对待。他还介绍了开源Oceanbase(0.4)的工作方式,通过将闲时数据和当日数据分别缓存于不同主机提高工作效率。通过事务编译,定义中间层操作,实现网络通讯优化。事务提交优化方面,首先缓冲区预分配,然后在缓存区并行填充。
演讲结尾,他谈到了关于一致性与分布式事务、加法与减法、原型与应用、one-size-fits-a-bunch方面的个人体会,并提出了观点:事务处理应该开放架构,使其适用于其他系统;开放源码,从开源社区中汲取经验,同样应致力于社区建设;开放思维,在理论和硬件平台的限制下寻找方法。
Pivotal 研发总监姚延栋:开源大数据引擎——分布式Greenplum数据库内核分析
姚延栋谈到大数据并不等于Hadoop。大多情况下,GPDB 更适合做大数据存储、计算、分析和挖掘的引擎。姚延栋介绍到GrGPDB支持标准 SQL 数据库:ANSI SQL 2008 标准,OLAP,JDBC/ODBC;支持ACID、分布式事务;支持分布式数据库:线性扩展,支持上百物理节点;支持企业级数据库;是一个开源数据库(greenplum.org),有着良性生态系统。
姚延栋重点讲解了MPP(大规模并行处理)无共享体系架构,该架构中分为主节点和从主节点,主节点负责协调整个集群。一个数据节点可以配置多个节点实例(Segment Instances) ,节点实例并行处理查询(SQL)。数据节点有自己的CPU、磁盘和内存(Share nothing)。
该架构中高速Interconnect处理持续数据流(Pipelining)。采用并行化数据分布,其策略和目标是均匀分布数据到各个数据节点。采用多级分区存储方式,能够生成并行查询计划,多级存储,能够大规模并行数据加载。

Pivotal 研发总监 姚延栋
Greenplum 组件中包含:
- 执行词法分析、语法分析并生成解析树的解释器;
- 处理解析树,生成查询计划的优化器;
- 发送查询计划给各个Segments的调度器;
- 分配处理查询需要的集群资源,收集并返回结果给客户端的执行器;
- 存储和管理数据库、表、字段的元数据的系统表;
- 主节点上的分布式事务管理器协调Segment上的提交和回滚操作的分布式事务。
Greenplum 数据库SQL执行流程:首先,当一个系统处于空闲状态时,一边是postmaster,另一边有两个Segment节点。当一个发送接口查询或链接,会先发给postmaster进程,收到这个请求之后会出来一个进程(QD,作为协调的角色),专门用来处理用户所发的请求。Segment上的postmaster收到这个请求以后又有一个进程(QE,就是实际执行任务的一个角色)。QD收到查询之后会做解析、做优化,生成查询计划,下发给所有的QE进程,所有的QE都会收到QD下发的查询计划。在这个过程中为了实现QE之间和QD之间的数据交换,会建立个连接,这个链接是通过UDP实现的。基础架构建立完之后开始执行,执行的时候是QE访问数据,做各种操作,把结果按照需求转发给其他所有需要的QE或者QD。
谈到开源,他介绍到Greenplum 最先进的开源分布式数据库(greenplum.org),具有十几万行的数据库源代码,采用完全基于社区的工作方式。
最后,姚延栋补充到通过主节点和数据节点的高可用性实现GPDB的高可用性。采用ftsprobe 故障检测进程使用心跳检测segments是否发生故障、自动failover到镜像 Segment等方式进行故障检测和恢复。
更多精彩内容,请关注直播专题 2015中国大数据技术大会(BDTC) ,新浪微博 @CSDN云计算 ,订阅 CSDN大数据 微信号。
正文到此结束
- 本文标签: 酒店 交易系统 时间 软件 主机 备份 db 数据库 Datanode 数据 需求 分布式事务 src rmi node Oracle UI 代码 json 企业 云 db2 噪音 集群 金融 SDN 实例 SQL Server IBM 科技 产品 系统架构 多线程 解析 微博 Hadoop swap 互联网 配置 FIT CTO 开源 源码 压力 sql 管理 空间 开发 2015 编译 js 进程 安全 大数据 UDP 快的 http 站点 ip 线程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

