物化视图中的统计信息导致的查询问题分析和修复
今天开发的同事下午反馈给我一个问题,说有操作直接卡住了,听这个描述,感觉很可能是查询慢了。
于是连接到环境中,查看了一下正在执行的sql语句情况,发现下面的语句已经执行了一段时间。
语句类似下面的形式:
select t1.SECURITY_PHONE as MOBILE_PHONE, t1.SECURITY_EMAIL as OTHER_EMAIL,
t2.* from accstat.ACCOUNT_DELTA t1, bidata.TMP_CN06 t2
where t1.CN_MASTER = t2.CN
其实对于这个查询,看起来条件也蛮简单的,但是为什么查询慢呢。
首先得了解一下这个问题的背景。
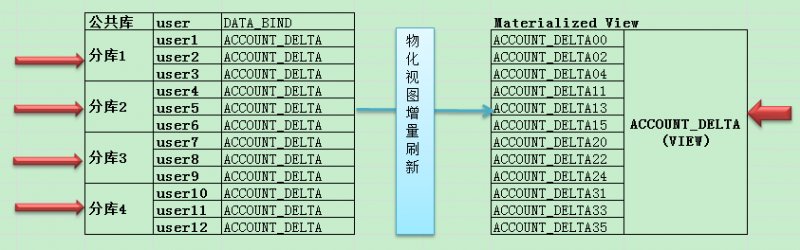
目前的这个库是一个统计库,库里的数据是从账号库中分库分表的12个用户中得来,就如同左边所示,是放在了4个分库,12个用户中,表名都是account_delta
目前采用是物化视图的增量刷新来实现,使得数据能够每天按时增量刷新到统计库中。统计库中也存在一套类似的结构,也是12个相似的表,不过在统计库中为了增量刷新我们采用了物化视图。
然后对外是使用一个account_delta的视图来实现。
所以现在的情况是account_delta和另外一个临时表关联,则实际意味着实际上是12个物化视图和1个表在关联。
那么到底慢在哪里了,我们来看看执行计划,可以看到12个物化视图都毫无例外走了全表扫描。当然整个执行计划的消耗那是非常惊人的。
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 622M| 95G| | 7160K (1)| 23:52:02 |
|* 1 | HASH JOIN | | 622M| 95G| 2056K| 7160K (1)| 23:52:02 |
| 2 | TABLE ACCESS FULL | TMP_CN06 | 80953 | 1106K| | 2294 (1)| 00:00:28 |
| 3 | VIEW | ACCOUNT_DELTA | 620M| 87G| | 2357K (2)| 07:51:25 |
| 4 | UNION-ALL | | | | | | |
| 5 | MAT_VIEW ACCESS FULL| ACC00_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 6 | MAT_VIEW ACCESS FULL| ACC02_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 7 | MAT_VIEW ACCESS FULL| ACC04_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 8 | MAT_VIEW ACCESS FULL| ACC11_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 9 | MAT_VIEW ACCESS FULL| ACC13_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 10 | MAT_VIEW ACCESS FULL| ACC15_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 11 | MAT_VIEW ACCESS FULL| ACC20_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 12 | MAT_VIEW ACCESS FULL| ACC22_ACCOUNT_DELTA | 47M| 6880M| | 196K (2)| 00:39:16 |
| 13 | MAT_VIEW ACCESS FULL| ACC24_ACCOUNT_DELTA | 52M| 7200M| | 196K (2)| 00:39:18 |
| 14 | MAT_VIEW ACCESS FULL| ACC31_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 15 | MAT_VIEW ACCESS FULL| ACC33_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 16 | MAT_VIEW ACCESS FULL| ACC35_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
PLAN_TABLE_OUTPUT
---------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."CN_MASTER"="T2"."CN")
Note
-----
- dynamic sampling used for this statement (level=2)
初步怀疑是索引导致的,但是发现两个表中的cn字段索引都存在。
然后继续查看发现了一个不同之处。TMP_CN06中的字段cn是varchar2(70),而account_delta中的cn_master是varchar2(50),感觉这里似乎有点关联,但是自己实在是想不出到底哪里可能有问题,于是把TMP_CN06中的字段cn改为了varchar2(50),其实内容是在varchar2(50)之内的。但是改了之后查看执行计划还是没有任何改善,还是全表扫描。
这个时候问题催的也非常着急,这个时候也在犹豫是不是因为多个物化视图导致了这个问题。
为了尽快修复问题,一边排查一遍开始准备复制一份数据来,表中的数据量非常大,最后开了并行的复制。最后还是一个ora错误收场。这个时候时间又过去了十多分钟。
create table accstat.ACCOUNT_DELTA_ALL as select *from accstat.ACCOUNT_DELTA
*
ERROR at line 1:
ORA-12801: error signaled in parallel query server P010
ORA-01652: unable to extend temp segment by 8192 in tablespace ACCSTAT_DATA
Elapsed: 00:16:14.85
这个时候尝试分片思想。把第二个分片的数据导入表中,大概持续了8分钟左右。不过按照这个速度还是有很大的差距。剩下的11个分片数据量都不小。
SQL> insert into accstat.ACCOUNT_DELTA_all select *from ACCSTAT.ACC02_ACCOUNT_DELTA ;
commit;
52074945 rows created.
Elapsed: 00:08:07.24
好了,我们还是放弃这种数据复制的方法,开始琢磨到底能不能做点什么。
继续分片,拿出一个分片和表TMP_CN06关联,然后查看执行计划,发现这个时候就走了索引扫描,而且执行的代价也小了很多。
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 3717601510
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 80953 | 12M| 26604 (1)| 00:05:20 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 80953 | 12M| 26604 (1)| 00:05:20 |
| 3 | TABLE ACCESS FULL | TMP_CN06 | 80953 | 1106K| 2294 (1)| 00:00:28 |
|* 4 | INDEX RANGE SCAN | ACC00_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 5 | MAT_VIEW ACCESS BY INDEX ROWID| ACC00_ACCOUNT_DELTA | 1 | 151 | 1 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."CN_MASTER"="T2"."CN")
Note
-----
- dynamic sampling used for this statement (level=2)
好了,这些尝试都做完了,我们来看看末尾的dynamic sampling的情况,一般的物化视图可能我们也就是纯粹为了增量刷新,也基本没有动过统计信息。我采用了下面的方式来收集统计信息。
exec DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=> 'ACCSTAT', TABNAME =>'ACC04_ACCOUNT_DELTA' ,CASCADE =>TRUE,METHOD_OPT=>'FOR ALL INDEXED COLUMNS SIZE 1',DEGREE =>4, GRANULARITY =>'ALL');
剩下的11个都是如法炮制,操作很快就完成了。
那么等我做完11个之后,再次查看执行计划还是全表扫描,还是提示dynamic sampling。直到我收集完全之后,再次查看执行计划。就变成了下面的形式。
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 949K| 143M| 1169K (1)| 03:53:49 |
| 1 | NESTED LOOPS | | 949K| 143M| 1169K (1)| 03:53:49 |
| 2 | TABLE ACCESS FULL | TMP_CN06 | 80953 | 1106K| 2294 (1)| 00:00:28 |
| 3 | VIEW | ACCOUNT_DELTA | 1 | 145 | 14 (0)| 00:00:01 |
| 4 | UNION ALL PUSHED PREDICATE | | | | | |
| 5 | MAT_VIEW ACCESS BY INDEX ROWID| ACC00_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | ACC00_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 7 | MAT_VIEW ACCESS BY INDEX ROWID| ACC02_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN | ACC02_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 9 | MAT_VIEW ACCESS BY INDEX ROWID| ACC04_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 10 | INDEX RANGE SCAN | ACC04_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 11 | MAT_VIEW ACCESS BY INDEX ROWID| ACC11_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 12 | INDEX RANGE SCAN | ACC11_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 13 | MAT_VIEW ACCESS BY INDEX ROWID| ACC13_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 14 | INDEX RANGE SCAN | ACC13_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 15 | MAT_VIEW ACCESS BY INDEX ROWID| ACC15_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 16 | INDEX RANGE SCAN | ACC15_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 17 | MAT_VIEW ACCESS BY INDEX ROWID| ACC20_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 18 | INDEX RANGE SCAN | ACC20_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 19 | MAT_VIEW ACCESS BY INDEX ROWID| ACC22_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 20 | INDEX RANGE SCAN | ACC22_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 21 | MAT_VIEW ACCESS BY INDEX ROWID| ACC24_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 22 | INDEX RANGE SCAN | ACC24_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 23 | MAT_VIEW ACCESS BY INDEX ROWID| ACC31_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 24 | INDEX RANGE SCAN | ACC31_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 25 | MAT_VIEW ACCESS BY INDEX ROWID| ACC33_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 26 | INDEX RANGE SCAN | ACC33_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 27 | MAT_VIEW ACCESS BY INDEX ROWID| ACC35_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 28 | INDEX RANGE SCAN | ACC35_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("CN_MASTER"="T2"."CN")
8 - access("CN_MASTER"="T2"."CN")
10 - access("CN_MASTER"="T2"."CN")
12 - access("CN_MASTER"="T2"."CN")
14 - access("CN_MASTER"="T2"."CN")
16 - access("CN_MASTER"="T2"."CN")
18 - access("CN_MASTER"="T2"."CN")
20 - access("CN_MASTER"="T2"."CN")
22 - access("CN_MASTER"="T2"."CN")
24 - access("CN_MASTER"="T2"."CN")
26 - access("CN_MASTER"="T2"."CN")
28 - access("CN_MASTER"="T2"."CN")
虽然看起来似乎会有些冗长,不过总体来看还是不错的。因为我们确实需要TMP_CN06走全表扫描。
那么我们再次尝试这个过程,时间就变为了惊人的3秒。TMP_CN06表中有近10万的记录,也没有走并行。
create table test_201551214 as select t1.SECURITY_PHONE as MOBILE_PHONE, t1.SECURITY_EMAIL as OTHER_EMAIL,
* t2.* from accstat.ACCOUNT_DELTA t1, bidata.TMP_CN06 t2 where t1.CN_MASTER = t2.CN;
Table created.
Elapsed: 00:00:03.27
所以从这个程度来看,物化视图堆叠起来的视图性能其实也差不了,用不好就会感觉差。也算是对物化视图的一个重新认识吧。
这个问题其实之前有同事反馈过,当时也是思路全在物化视图日志上下功夫了,准备解析物化视图日志来做一个merge的操作,最后也是无功而返,也对物化视图的操作产生了一些误解,看来这种情况下,性能也照样差不了。我已经试过水了,所以这种情况还是值得推广的。
于是连接到环境中,查看了一下正在执行的sql语句情况,发现下面的语句已经执行了一段时间。
语句类似下面的形式:
select t1.SECURITY_PHONE as MOBILE_PHONE, t1.SECURITY_EMAIL as OTHER_EMAIL,
t2.* from accstat.ACCOUNT_DELTA t1, bidata.TMP_CN06 t2
where t1.CN_MASTER = t2.CN
其实对于这个查询,看起来条件也蛮简单的,但是为什么查询慢呢。
首先得了解一下这个问题的背景。
目前的这个库是一个统计库,库里的数据是从账号库中分库分表的12个用户中得来,就如同左边所示,是放在了4个分库,12个用户中,表名都是account_delta
目前采用是物化视图的增量刷新来实现,使得数据能够每天按时增量刷新到统计库中。统计库中也存在一套类似的结构,也是12个相似的表,不过在统计库中为了增量刷新我们采用了物化视图。
然后对外是使用一个account_delta的视图来实现。
所以现在的情况是account_delta和另外一个临时表关联,则实际意味着实际上是12个物化视图和1个表在关联。
那么到底慢在哪里了,我们来看看执行计划,可以看到12个物化视图都毫无例外走了全表扫描。当然整个执行计划的消耗那是非常惊人的。
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 622M| 95G| | 7160K (1)| 23:52:02 |
|* 1 | HASH JOIN | | 622M| 95G| 2056K| 7160K (1)| 23:52:02 |
| 2 | TABLE ACCESS FULL | TMP_CN06 | 80953 | 1106K| | 2294 (1)| 00:00:28 |
| 3 | VIEW | ACCOUNT_DELTA | 620M| 87G| | 2357K (2)| 07:51:25 |
| 4 | UNION-ALL | | | | | | |
| 5 | MAT_VIEW ACCESS FULL| ACC00_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 6 | MAT_VIEW ACCESS FULL| ACC02_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 7 | MAT_VIEW ACCESS FULL| ACC04_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 8 | MAT_VIEW ACCESS FULL| ACC11_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 9 | MAT_VIEW ACCESS FULL| ACC13_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 10 | MAT_VIEW ACCESS FULL| ACC15_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 11 | MAT_VIEW ACCESS FULL| ACC20_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
| 12 | MAT_VIEW ACCESS FULL| ACC22_ACCOUNT_DELTA | 47M| 6880M| | 196K (2)| 00:39:16 |
| 13 | MAT_VIEW ACCESS FULL| ACC24_ACCOUNT_DELTA | 52M| 7200M| | 196K (2)| 00:39:18 |
| 14 | MAT_VIEW ACCESS FULL| ACC31_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 15 | MAT_VIEW ACCESS FULL| ACC33_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:18 |
| 16 | MAT_VIEW ACCESS FULL| ACC35_ACCOUNT_DELTA | 52M| 7201M| | 196K (2)| 00:39:17 |
PLAN_TABLE_OUTPUT
---------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."CN_MASTER"="T2"."CN")
Note
-----
- dynamic sampling used for this statement (level=2)
初步怀疑是索引导致的,但是发现两个表中的cn字段索引都存在。
然后继续查看发现了一个不同之处。TMP_CN06中的字段cn是varchar2(70),而account_delta中的cn_master是varchar2(50),感觉这里似乎有点关联,但是自己实在是想不出到底哪里可能有问题,于是把TMP_CN06中的字段cn改为了varchar2(50),其实内容是在varchar2(50)之内的。但是改了之后查看执行计划还是没有任何改善,还是全表扫描。
这个时候问题催的也非常着急,这个时候也在犹豫是不是因为多个物化视图导致了这个问题。
为了尽快修复问题,一边排查一遍开始准备复制一份数据来,表中的数据量非常大,最后开了并行的复制。最后还是一个ora错误收场。这个时候时间又过去了十多分钟。
create table accstat.ACCOUNT_DELTA_ALL as select *from accstat.ACCOUNT_DELTA
*
ERROR at line 1:
ORA-12801: error signaled in parallel query server P010
ORA-01652: unable to extend temp segment by 8192 in tablespace ACCSTAT_DATA
Elapsed: 00:16:14.85
这个时候尝试分片思想。把第二个分片的数据导入表中,大概持续了8分钟左右。不过按照这个速度还是有很大的差距。剩下的11个分片数据量都不小。
SQL> insert into accstat.ACCOUNT_DELTA_all select *from ACCSTAT.ACC02_ACCOUNT_DELTA ;
commit;
52074945 rows created.
Elapsed: 00:08:07.24
好了,我们还是放弃这种数据复制的方法,开始琢磨到底能不能做点什么。
继续分片,拿出一个分片和表TMP_CN06关联,然后查看执行计划,发现这个时候就走了索引扫描,而且执行的代价也小了很多。
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 3717601510
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 80953 | 12M| 26604 (1)| 00:05:20 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 80953 | 12M| 26604 (1)| 00:05:20 |
| 3 | TABLE ACCESS FULL | TMP_CN06 | 80953 | 1106K| 2294 (1)| 00:00:28 |
|* 4 | INDEX RANGE SCAN | ACC00_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 5 | MAT_VIEW ACCESS BY INDEX ROWID| ACC00_ACCOUNT_DELTA | 1 | 151 | 1 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."CN_MASTER"="T2"."CN")
Note
-----
- dynamic sampling used for this statement (level=2)
好了,这些尝试都做完了,我们来看看末尾的dynamic sampling的情况,一般的物化视图可能我们也就是纯粹为了增量刷新,也基本没有动过统计信息。我采用了下面的方式来收集统计信息。
exec DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=> 'ACCSTAT', TABNAME =>'ACC04_ACCOUNT_DELTA' ,CASCADE =>TRUE,METHOD_OPT=>'FOR ALL INDEXED COLUMNS SIZE 1',DEGREE =>4, GRANULARITY =>'ALL');
剩下的11个都是如法炮制,操作很快就完成了。
那么等我做完11个之后,再次查看执行计划还是全表扫描,还是提示dynamic sampling。直到我收集完全之后,再次查看执行计划。就变成了下面的形式。
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 949K| 143M| 1169K (1)| 03:53:49 |
| 1 | NESTED LOOPS | | 949K| 143M| 1169K (1)| 03:53:49 |
| 2 | TABLE ACCESS FULL | TMP_CN06 | 80953 | 1106K| 2294 (1)| 00:00:28 |
| 3 | VIEW | ACCOUNT_DELTA | 1 | 145 | 14 (0)| 00:00:01 |
| 4 | UNION ALL PUSHED PREDICATE | | | | | |
| 5 | MAT_VIEW ACCESS BY INDEX ROWID| ACC00_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | ACC00_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 7 | MAT_VIEW ACCESS BY INDEX ROWID| ACC02_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN | ACC02_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 9 | MAT_VIEW ACCESS BY INDEX ROWID| ACC04_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 10 | INDEX RANGE SCAN | ACC04_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 11 | MAT_VIEW ACCESS BY INDEX ROWID| ACC11_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 12 | INDEX RANGE SCAN | ACC11_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 13 | MAT_VIEW ACCESS BY INDEX ROWID| ACC13_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 14 | INDEX RANGE SCAN | ACC13_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 15 | MAT_VIEW ACCESS BY INDEX ROWID| ACC15_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 16 | INDEX RANGE SCAN | ACC15_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 17 | MAT_VIEW ACCESS BY INDEX ROWID| ACC20_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 18 | INDEX RANGE SCAN | ACC20_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 19 | MAT_VIEW ACCESS BY INDEX ROWID| ACC22_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 20 | INDEX RANGE SCAN | ACC22_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 21 | MAT_VIEW ACCESS BY INDEX ROWID| ACC24_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 22 | INDEX RANGE SCAN | ACC24_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 23 | MAT_VIEW ACCESS BY INDEX ROWID| ACC31_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 24 | INDEX RANGE SCAN | ACC31_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 25 | MAT_VIEW ACCESS BY INDEX ROWID| ACC33_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 26 | INDEX RANGE SCAN | ACC33_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
| 27 | MAT_VIEW ACCESS BY INDEX ROWID| ACC35_ACCOUNT_DELTA | 1 | 145 | 1 (0)| 00:00:01 |
|* 28 | INDEX RANGE SCAN | ACC35_IND_CCMNN | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("CN_MASTER"="T2"."CN")
8 - access("CN_MASTER"="T2"."CN")
10 - access("CN_MASTER"="T2"."CN")
12 - access("CN_MASTER"="T2"."CN")
14 - access("CN_MASTER"="T2"."CN")
16 - access("CN_MASTER"="T2"."CN")
18 - access("CN_MASTER"="T2"."CN")
20 - access("CN_MASTER"="T2"."CN")
22 - access("CN_MASTER"="T2"."CN")
24 - access("CN_MASTER"="T2"."CN")
26 - access("CN_MASTER"="T2"."CN")
28 - access("CN_MASTER"="T2"."CN")
虽然看起来似乎会有些冗长,不过总体来看还是不错的。因为我们确实需要TMP_CN06走全表扫描。
那么我们再次尝试这个过程,时间就变为了惊人的3秒。TMP_CN06表中有近10万的记录,也没有走并行。
create table test_201551214 as select t1.SECURITY_PHONE as MOBILE_PHONE, t1.SECURITY_EMAIL as OTHER_EMAIL,
* t2.* from accstat.ACCOUNT_DELTA t1, bidata.TMP_CN06 t2 where t1.CN_MASTER = t2.CN;
Table created.
Elapsed: 00:00:03.27
所以从这个程度来看,物化视图堆叠起来的视图性能其实也差不了,用不好就会感觉差。也算是对物化视图的一个重新认识吧。
这个问题其实之前有同事反馈过,当时也是思路全在物化视图日志上下功夫了,准备解析物化视图日志来做一个merge的操作,最后也是无功而返,也对物化视图的操作产生了一些误解,看来这种情况下,性能也照样差不了。我已经试过水了,所以这种情况还是值得推广的。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

