SqlServer中Sql语句的逻辑执行顺序
准备数据
Sql脚本如下,两张表,一张客户表Customers只包含customerid和city字段,一张订单表Orders包含orderid和customerid(关联Customers的customerid字段)
IF OBJECT_ID('dbo.Orders') IS NOT NULL DROP TABLE dbo.Orders; IF OBJECT_ID('dbo.Customers') IS NOT NULL DROP TABLE dbo.Customers; GO CREATE TABLE dbo.Customers ( customerid CHAR(5) NOT NULL PRIMARY KEY, city VARCHAR(10) NOT NULL ); CREATE TABLE dbo.Orders ( orderid INT NOT NULL PRIMARY KEY, customerid CHAR(5) NULL REFERENCES Customers(customerid) ); GO INSERT INTO dbo.Customers(customerid, city) VALUES('FISSA', 'Madrid'); INSERT INTO dbo.Customers(customerid, city) VALUES('FRNDO', 'Madrid'); INSERT INTO dbo.Customers(customerid, city) VALUES('KRLOS', 'Madrid'); INSERT INTO dbo.Customers(customerid, city) VALUES('MRPHS', 'Zion'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(1, 'FRNDO'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(2, 'FRNDO'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(3, 'KRLOS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(4, 'KRLOS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(5, 'KRLOS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(6, 'MRPHS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(7, NULL); View Code 对于一条Sql语句(主要指的是查询语句)的执行顺序,很多开发人员并不是十分的了解,哪怕已经工作几年的所谓高级开发人员也是一样,对于他们来说,只关心最终得到的结果,并不关心中间的过程,那么了解SqlServer的语句执行过程到底有什么用处的?
1、如果不了解执行过程,下面的Sql语句你认为结果是一样的吗?
select * from Customers AS C left join Orders AS O On C.customerid=O.customerid and C.customerid='FRNDO' where city ='Madrid' select * from Customers AS C left join Orders AS O On C.customerid=O.customerid where city ='Madrid' and C.customerid='FRNDO'
如果你了解Sql的执行顺序,这个问题就不难解释了,只不过是On语句和Where语句谁先执行以及On和Where之间是否还有其它执行步骤?
2、下面这两条语句,第一个会提示列where语句中的myorder(select 中起的别名)无效,第二条是可以正常执行的,那问题来了,为什么order by语句中可以使用myorder列而where中就不可以呢?
select C.customerid,C.city,O.orderid as myorder from Customers AS C left join Orders AS O On C.customerid=O.customerid where myorder >3 order by myorder desc select C.customerid,C.city,O.orderid as myorder from Customers AS C left join Orders AS O On C.customerid=O.customerid where O.orderid >3 order by myorder desc
Sql语句逻辑执行顺序
一条常用的查询语句应当是包含了下面的几条命令
select distinct top 3 C.customerid, count(O.orderid) as orderCount from Customers as C left join Orders as O ON C.customerid=O.customerid where C.city='Madrid' group by C.customerid having count(O.orderid)>1 order by orderCount desc
1、From阶段
From阶段主要是标识数据来源,处理表运算符(join、apply,pivot等,本文只针对join讲解),以及各个子阶段(包括笛卡尔积、ON筛选器应用、添加外部行[只有外链接才有]);
1.1 join阶段 join分为cross join、inner join、[left join、right join,full join]
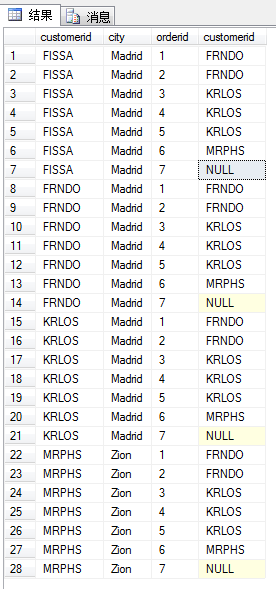
cross join只是简单的进行笛卡尔积,如上面的两张表cross join之后的结果如下图(左一);
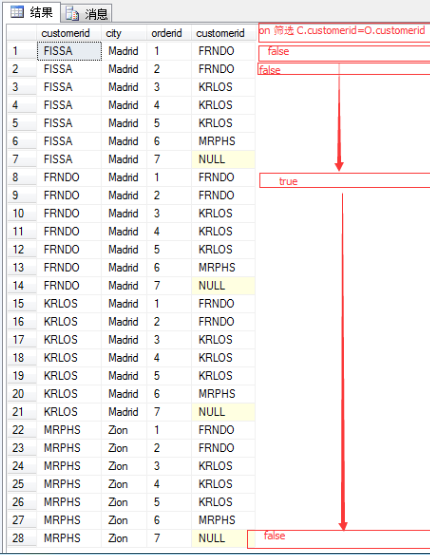
inner join是在cross join的基础上加入了ON筛选条件,如图(左二和左三),只有ON(C.customerId=O.customerId)为Ture的才会返回
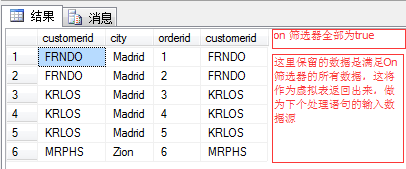
left join 是在 inner join的基础上添加了外部行,在ON阶段获取的数据基础上添加左表(Customer表)中的未满足ON筛选条件的所有行(未在ON阶段出现的),如图(左四)
2、Where 阶段
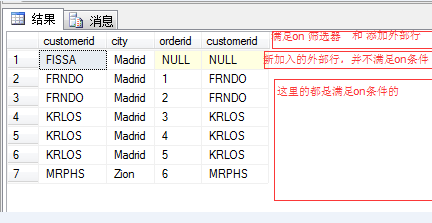
where 阶段就是对From阶段得到的虚拟表进行进一步的过滤和筛选,和Join中的ON筛选类似,只是比ON筛选器执行的晚,特别对于外链接来说,ON筛选和Where筛选中间还多了一步添加外部行,这里应该可以解释本文开篇提到的第一个问题了。
3、Group By
Group By 只是按照指定的列名对第二步(如果存在)Where阶段得到的虚拟表进行分组,每个分组只有一条数据,一般都是使用聚合函数来计算一些数据,比如上面例子中用按照CustomerId进行分组,用Count获取每个客户的订单数量,然后按照订单数量倒序去排名前三的客户。
4、Having
Having阶段是在第三步(如果存在)分组之后再一次进行过滤,也就是对Group By阶段得到的虚拟结果集进行进一步的筛选过滤,过程和ON、Where类似,只能用在Group BY 之后。
5、Select
Select 阶段则是针对第四步(如果存在)获取的虚拟表的基础上选择需要的列,也就是最终要返回的列,看到这里是不是明白了本文开篇提到的第二个问题,为什么Select中的别名不能再Wher阶段使用,因为Where早于Select,
Select又可以分为几个子阶段,包括(5.1计算表达式,5.2 Distinct,5.3 Top)
6、Order By
Order By 阶段是整个查询的最后阶段也就是根据指定的列名对Select阶段进行排序,这也就是为什么在Order By语句中可以用Select阶段起的别名的原因,不过Order By阶段和上面的5个阶段有个很大的区别,Order By阶段返回的数据集是游标,而上面的5个阶段生成的都是数据表,理解这点很重要,SqlServer的理论基础是集合论,集合中的行之间没有预先定义顺序,它只是成员之间的逻辑组合,成员之间的顺序无关紧要,而对于带有Order By的查询语句,是返回了一个按照特定的顺寻组成的一个对象,成为游标。
最后附上一张Sql语句的执行流程图(图片来源Sql08解密)

总结
不知不觉已经写了将近3个小时了,本文简单介绍SqlServer中个语句的执行过程,只有理解的个语句的执行过程,才能写出更加准确,更加高效的Sql命令。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

