Introduction To Cuckoo Hashing
Motivation & Intuition
为什么引入Cuckoo Hashing?
常见的hashing处理冲突方法一般包括两种:开散列(Separate Chaining )和闭散列(Linear / Quadratic Probing )。开散列是将冲突的元素组织成一个链表(其实组织成一个二叉树也是没问题的啊),闭散列将冲突的元素还是放在哈希表slot中,使用线性探测等方法进行处理。
那么,这两种方法,都有啥优缺点呢?
开散列,实现简单,但是对cache不友好,cache miss rate较高。
闭散列,实现相对复杂一点点,对cache很友好,但是对load factor要求较高:load factor稍高性能就急剧下降。
而Cuckoo Hashing在load factor为50%左右的情况下表现较佳。如果哈希函数有4个,那么甚至可以在97%的load factor下良好工作。
Cuckoo Hashing
一般的Hashing只包括一个Hash Tables,但是Cuckoo Hashing由两张甚至多张表构成。每张表对应一个哈希函数。本文讨论两张哈希表(记为table1和table2)、两个哈希函数(记为hf1和hf2)这种常见情形。
Insert:首先通过hf1计算出一个slot index,然后查看table1中该slot是否vacant,如果是,则插入;否则通过hf2计算出一个slot index,通过查看table2中该slot是否vacant,如果是,则插入,否则执行replace操作。
replace操作的过程:随机选出一张表,将slot index对应的那个元素踢出(evict),把我们待插入的元素插到那个位置。那被踢出来的元素呢?尝试插入到另外一张表对应的slot处,这时候可能又踢出一个元素,接下去就是递归的执行这个过程,直到所有元素都安置妥当。
举个例子吧,假如某个时刻,两个哈希表的内容如下:
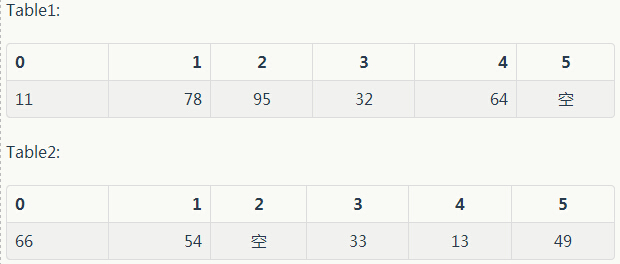
假设我们待插入的元素为77。
slot index1 = hf1(77) = 1
Table1中的index为1的slot已经被78占了。那么看Table2:
slot index2 = hf2(77) = 3
Table2中的index为3的slot已经被33占了。因此执行replace。
执行replace动作,选择Table2,将slot index = 3的元素33踢出,插入77。然后被踢出的元素33,计算它在Table1中的index为slot index1 = hf2(33) = 2,因此将95踢出,插入33。被踢出的元素95在Table2中的slot index为2,该slot为vacant,没人使用,因此将95插入。完毕。现在的Tables中元素为:

值得注意的是,replace可能失败(发生“死循环”,无法找到一个vacant slot),此时需要进行rehash。因此代码里需要有一定的判断。
在某些假设下,插入操作的期望复杂度为O(1)。
Find:要检查的slot一共两个,index分别为hf1(key)和hf2(key),因此只要查看一下Table1中的hf1(key)以及Table2中的hf2(key)这两个slot即可。时间复杂度为O(1)。
Del:同Find,要检查的slot也就两个,复杂度为O(1)。
实现
简单实现了一个,有需要的可以参考 这里
参考文献
http://resources.mpi-inf.mpg.de/departments/d1/teaching/ws14/AlgoDat/materials/cuckoo.pdf
Cuckoo Hashing原始论文
https://www.eecs.harvard.edu/~michaelm/postscripts/esa2009.pdf
这篇文章介绍了一些关于Cuckoo Hashing的Open Questions
http://web.stanford.edu/class/cs166/lectures/13/Slides13.pdf
这个slides偏重对Cuckoo Hashing理论上的分析
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=6888938&url=http%3A%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D6888938
碉堡了,lock free Cuckoo Hashing
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

